Stock prediction method, system and device based on affinity propagation and medium
A technology of neighbor propagation and prediction method, applied in prediction, character and pattern recognition, instruments and other directions, can solve the problems of "overfitting, inability to parallel processing, slow learning speed, etc., to improve the prediction accuracy, improve the The speed of training, the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0084] Embodiment one, as figure 1 As shown, a stock prediction method based on neighbor propagation includes the following steps:
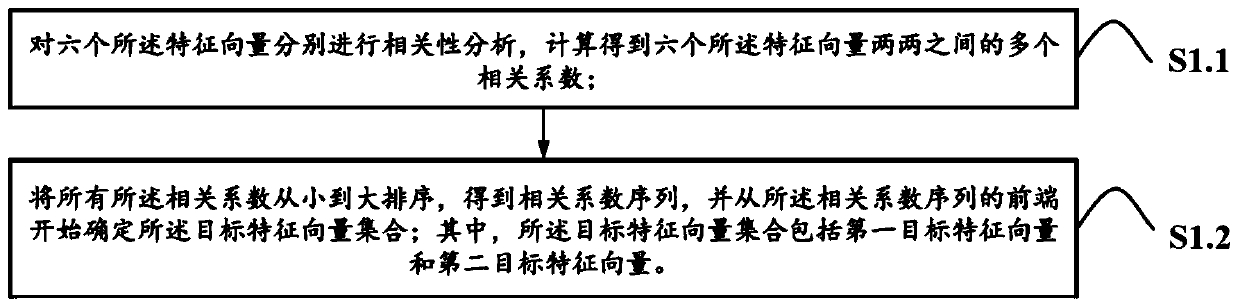
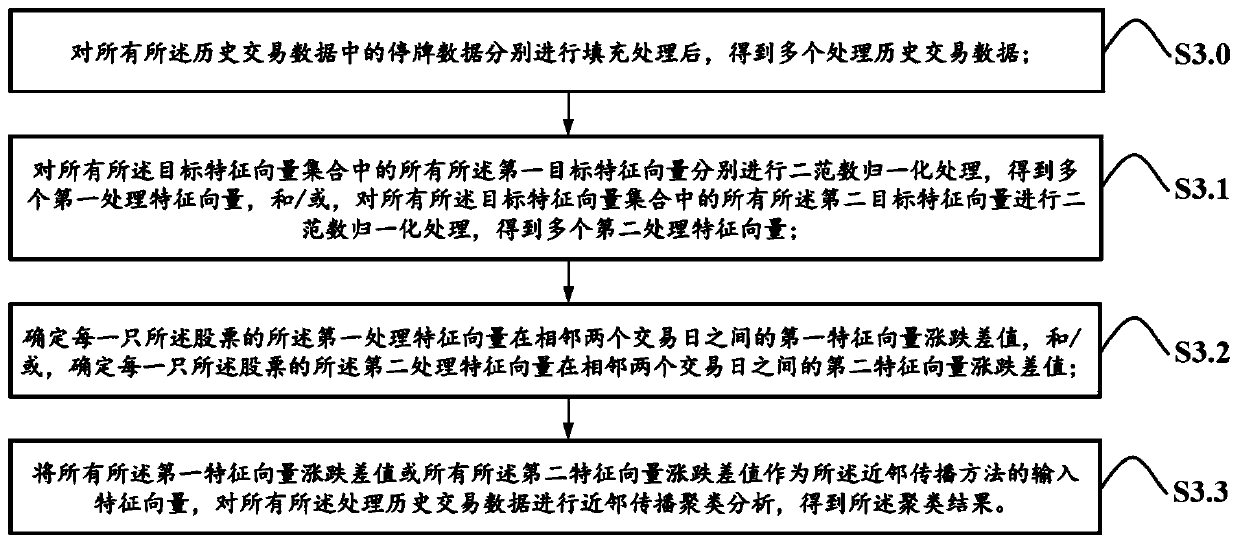
[0085] S1: Obtain multiple historical transaction data of multiple stocks within a preset time, process the feature vector set in the historical transaction data of any one of the stocks, and obtain the target feature of the corresponding one of the stocks collection of vectors;
[0086] S2: According to the target feature vector set of a corresponding stock obtained in S1, directly obtain a plurality of target feature vector sets corresponding to other remaining stocks in S1; S3: Use neighbor propagation method, performing a neighbor propagation clustering analysis on the historical transaction data corresponding to all the stocks according to the set of all target feature vectors to obtain a clustering result;
[0087] S4: According to the clustering results, select a preset number of sample stocks in the clusters of the stocks to be predicte...
Embodiment 2
[0156] Embodiment two, such as Figure 5 As shown, a stock prediction system based on neighbor propagation, including data acquisition module, data processing module, cluster analysis module, model training and construction module and prediction module;
[0157] The data acquisition module is used to acquire a plurality of historical transaction data of a plurality of stocks within a preset time;
[0158] The data processing module is configured to process the set of feature vectors in the historical transaction data of any one of the stocks to obtain a set of target feature vectors corresponding to one of the stocks;
[0159] The clustering analysis module is used to directly obtain the one-to-one correspondence with the other remaining stocks in the data processing module according to the target feature vector set of the corresponding one of the stocks obtained by the data processing module. A plurality of the target feature vector sets; it is also used to perform neighbor ...
Embodiment 3
[0163] Embodiment 3. Based on Embodiment 1 and Embodiment 2, this embodiment also discloses a stock prediction device based on neighbor propagation, which includes a processor, a memory, and is stored in the memory and can run on the processor. A computer program that, when run, implements the figure 1 The specific steps from S1 to S5 are shown.
[0164] By storing the computer program on the memory and running it on the processor, the prediction of the rising and falling trend of the stock of the present invention is realized. Based on the nearest neighbor propagation clustering method and the support vector machine training method, the calculation amount is low and the calculation time is short. It occupies less memory and has high parallelism. The stock trend prediction model obtained can accurately predict the ups and downs of the stocks to be predicted, and significantly improves the prediction accuracy.
[0165] This embodiment also provides a computer storage medium, w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com