Index generation method and retrieval method for scientific big data
A data indexing and big data technology, applied in database indexing, structured data retrieval, digital data information retrieval, etc., can solve the problems of low disk access rate and computing speed, improve retrieval efficiency, prevent disk access overhead, The effect of data block size optimization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0052] This embodiment provides an index generation method for scientific big data, including the following steps:
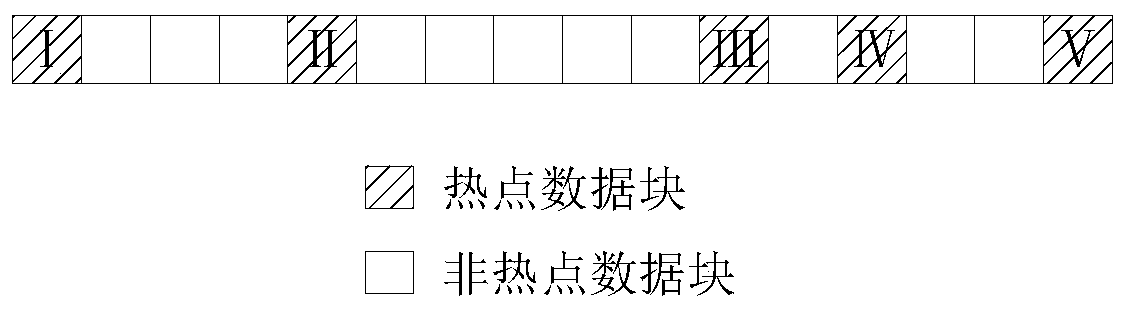
[0053] According to the heat of each data block, it is determined that several of the data blocks are hot data blocks;
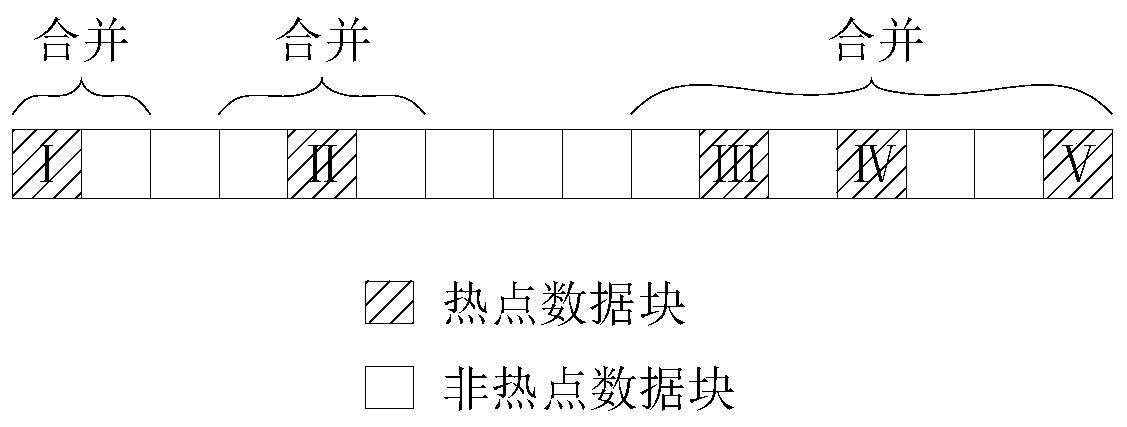
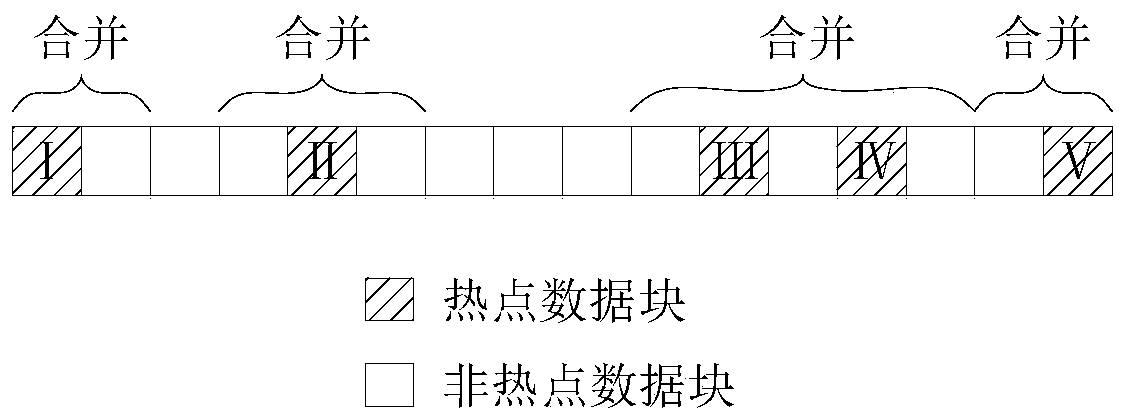
[0054] Merge the hot data block and the data blocks adjacent to the hot data block according to the continuity of the hot data block;
[0055] Generate data indexes or update original data indexes according to the merged data blocks.
[0056] According to the real-time heat of each data block, the hot data block is determined, and the hot data block is merged with the data blocks adjacent to the hot data block according to the continuity of the hot data block. Specifically: when the hot data block is relatively discontinuous, Merge the hotspot data block with its adjacent non-hotspot data block; when the hotspot data block is relatively continuous, merge the hotspot data block with the non-hotspot data block and hotspot data block adjacent to...
Embodiment 2
[0100] This embodiment provides a search method for scientific big data, including the index generation method for scientific big data as described in Embodiment 1, and also includes the following steps:
[0101] Data retrieval based on data index.
[0102] According to the continuous situation of the hot data block, the hot data block and the data block adjacent to the hot data block are dynamically merged, and the size of the data block can be optimized. According to the data index generated or updated in real time according to the dynamically merged data block, based on the data The index retrieves scientific big data, which can not only prevent the data block from being too large and cause too much redundant information to enter the disk during retrieval and increase the overhead of data filtering, but also prevent the data block from being too small to increase the disk memory access overhead during retrieval , make full use of computer computing resources, and greatly im...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com