

BERT-based government affair official document ontology concept extraction method
A technology of official documents and ontology, which is applied in the field of ontology learning, can solve problems such as insufficient comprehensiveness and richness of ontology concepts, poor extraction of ontology concepts, etc., and achieve the effect of improving the clustering effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

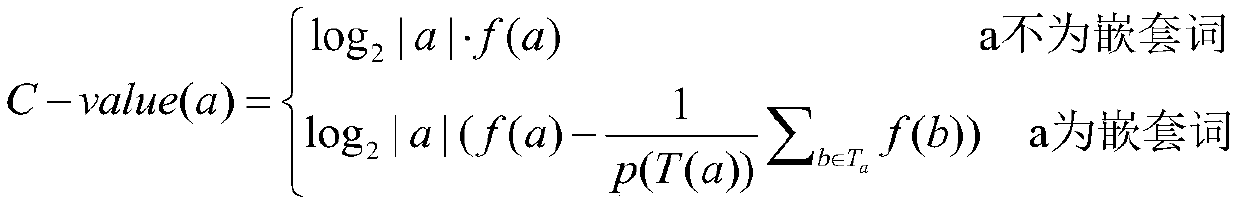
Examples
Embodiment 1
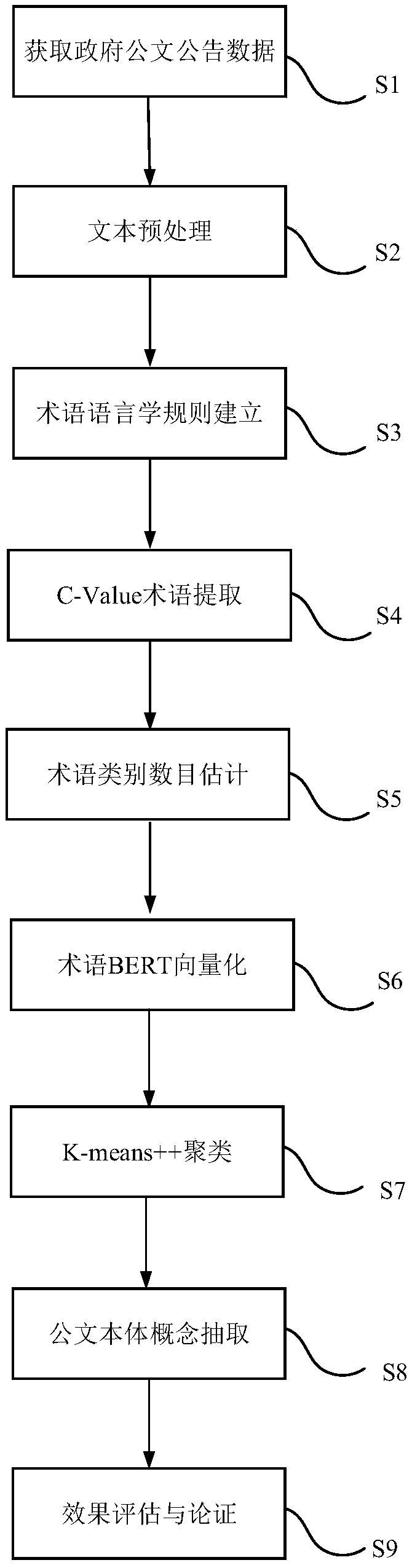
[0056] As mentioned above, a BERT-based method for extracting the concept of government official texts includes the following steps:
[0057] (1) Using the crawler method to obtain government official document data from the website of the people's government of a certain province using crawlers;
[0058] (2) Perform text data preprocessing on the public government official document data;
[0059](3) Terminological rules extracted according to linguistic regulations;
[0060] (4) Use the C-value algorithm to realize the term extraction of government official document data;
[0061] (5) Use BERT to realize the vectorized representation of official document terms;
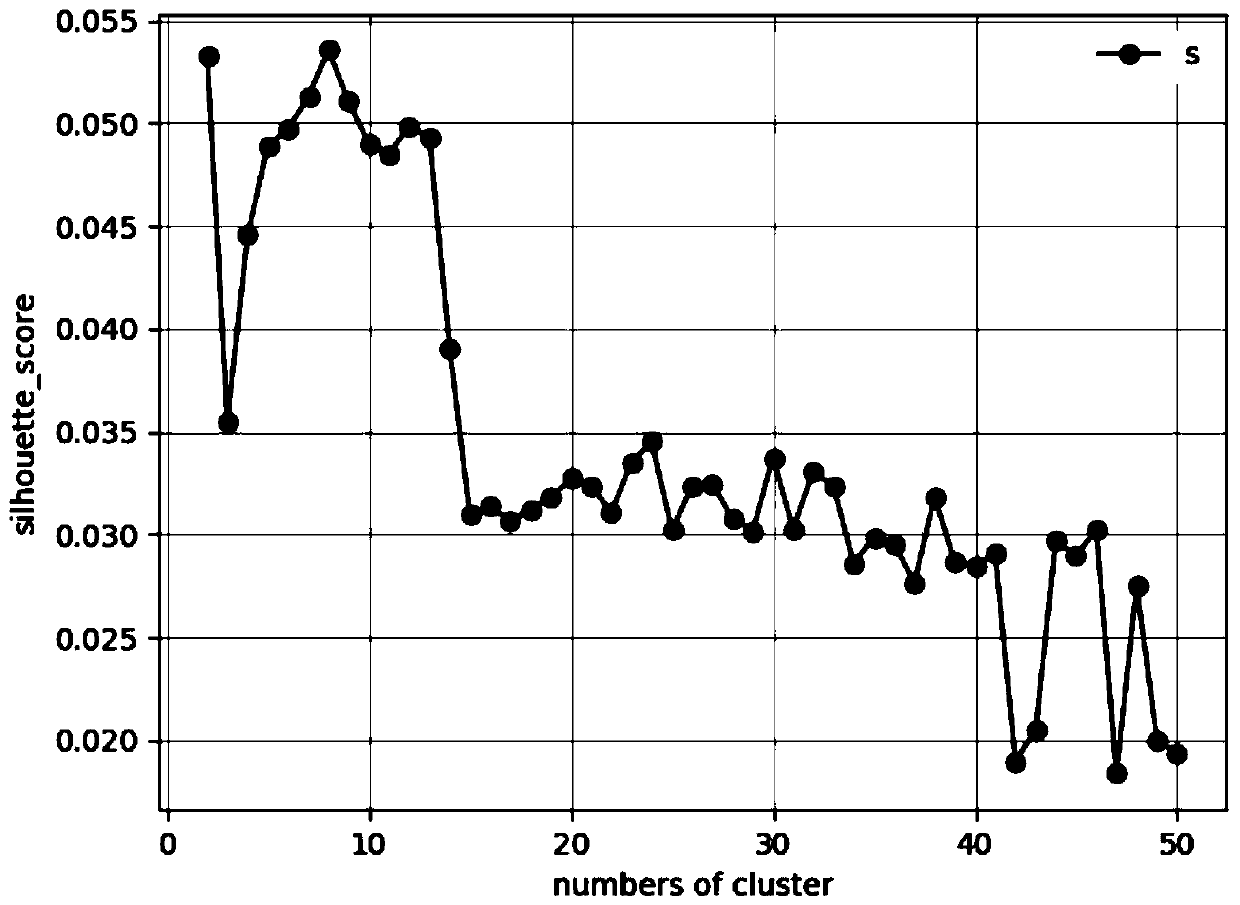
[0062] (6) Use the contour coefficient method to estimate the number of official document term classes;
[0063] (7) Use the K-means++ algorithm to realize the clustering of official document terms;
[0064] (8) Select Top_N in the class as the official document concept to realize the extraction of official docume...
Embodiment 2
[0067] Such as figure 1 As shown, a BERT-based method for extracting the concept of government official texts includes the following steps:
[0068] First execute step S1 to obtain government official document data
[0069] Send a request to the opposite server through the URL, obtain the static or dynamic code of the page, and clean the required document title and document text from the page code by parsing the DOM tree or other aspects to realize data capture and storage.
[0070] This example crawls the official document data of a certain province's government affairs disclosure from 2013 to 2018, with a total of 8,530 official document documents and 9,796,600 official document words.
[0071] Next, execute step S2 to perform text preprocessing on all official government documents
[0072] Use the python development language to remove stop words, numbers, English characters, punctuation marks, low-frequency words, etc., and then use the stutter word segmentation tool to c...
Embodiment 3
[0106] As mentioned above, a BERT-based method for extracting the concept of government official texts includes the following steps:
[0107] (1) Obtain government official document data;
[0108] (2) Perform text data preprocessing on the public government official document data;
[0109] (3) Restrict the terminology of official documents with linguistic rules;
[0110] (4) Extract terminology from government official document data;
[0111] (5) Carry out vectorized representation to the extracted official document terms;
[0112] (6) Estimate the number of official document term categories;
[0113] (7) Realize official document term clustering by combining the clustering method with the vector representation of terms;
[0114] (8) Select official document concepts from each type of term set to complete the extraction of official document body concepts;
[0115] (9) Evaluate and verify the concept extraction results.
[0116] In the step (1), the government official do...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More