

Data clustering identification method and device, computer system and readable storage medium
A data clustering and identification method technology, applied in the field of communication, can solve problems such as difficulty in obtaining labeled data, misjudgment in case screening, difficulty in making an effective and reliable mature neural network, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
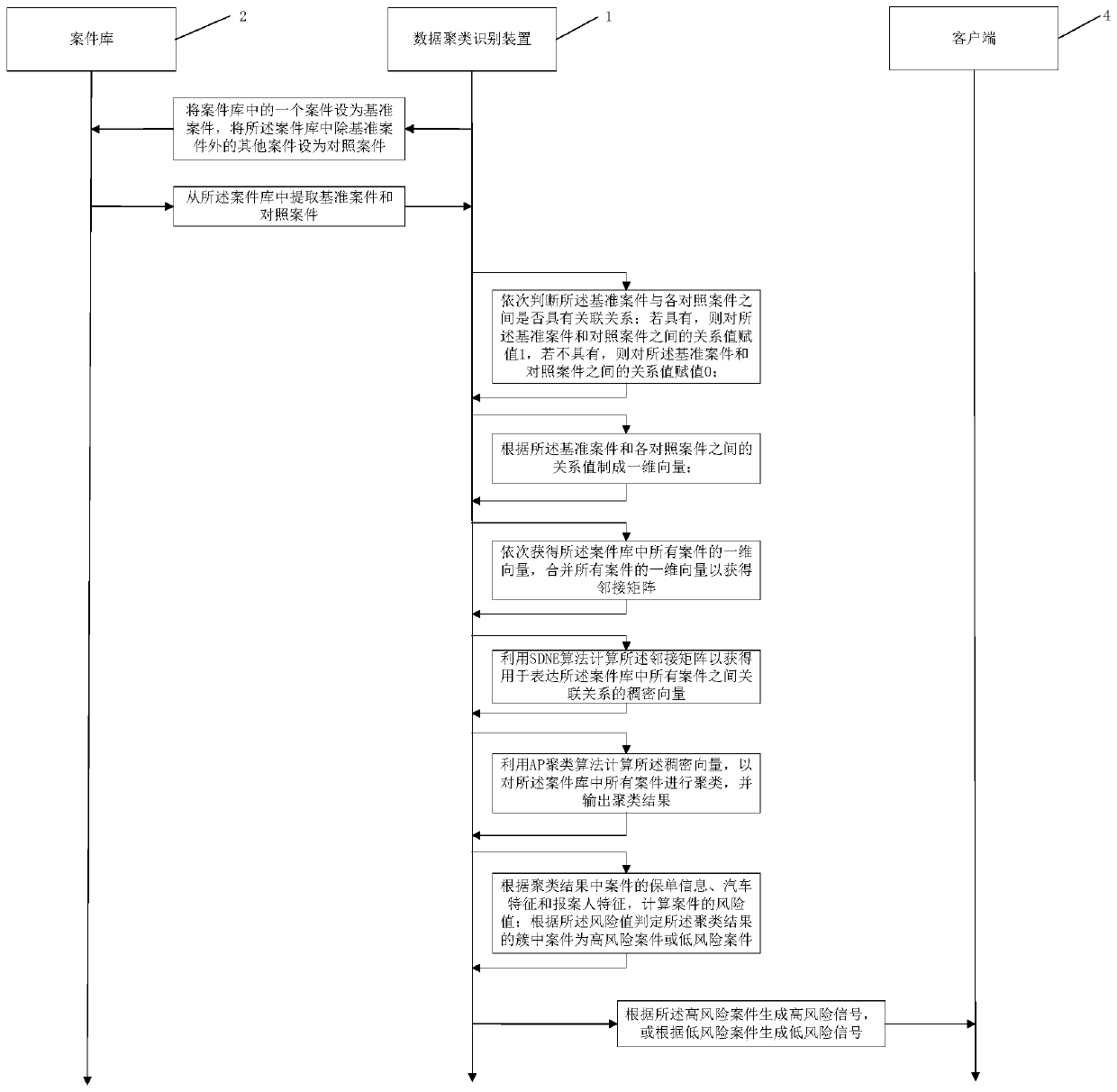
[0072] see figure 1 and figure 2 , the data clustering identification method of the present embodiment, using the data clustering identification device 1, comprises the following steps:
[0073] S1: Set a case in the case database 2 as a benchmark case, and set other cases in the case database 2 except the benchmark case as a comparison case; extract the benchmark case and the comparison case from the case database 2, and judge in turn Whether there is a relationship between the benchmark case and each control case; if yes, then assign a value of 1 to the relationship between the benchmark case and the control case; The relationship value assignment of 0; According to the relationship value between the benchmark case and each control case, the one-dimensional vector of the benchmark case is made; wherein, the data information of the case includes scene pictures, report text information, scene structure information , policy information, vehicle characteristics and reporter c...
Embodiment 2
[0192] see image 3 , the data clustering identification device 1 of this embodiment includes:
[0193] A one-dimensional vector formulating module 11, used to set a case in the case database 2 as a reference case, and set other cases in the case database 2 except the reference case as comparison cases; extract the reference case from the case database 2 Cases and comparison cases, determine whether there is a relationship between the benchmark case and each comparison case in turn; if yes, then assign a value of 1 to the relationship between the benchmark case and the comparison case; The relationship value assignment between the benchmark case and the contrast case is 0; the one-dimensional vector of the benchmark case is made according to the relation value between the benchmark case and each contrast case; wherein, the data information of the case includes on-site pictures, Report text information, scene structure information, insurance policy information, vehicle charact...
Embodiment 3
[0200] In order to achieve the above object, the present invention also provides a computer system, the computer system includes a plurality of computer equipment 3, the components of the data clustering identification device 1 of the second embodiment can be dispersed in different computer equipment, the computer equipment can be Smartphones, tablet computers, laptops, desktop computers, rack servers, blade servers, tower servers, or rack servers (including independent servers, or server clusters composed of multiple servers) that execute programs, etc. The computer equipment in this embodiment at least includes but is not limited to: a memory 31 and a processor 32 that can communicate with each other through a system bus, such as Figure 4 shown. It should be pointed out that, Figure 4 Only a computer device is shown with the components - but it should be understood that implementing all of the illustrated components is not a requirement and that more or fewer components m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More