

Internet big data cleaning method
A data cleaning and big data technology, applied in the field of data cleaning, can solve the problems of low efficiency of screening and cleaning, achieve the effect of solving low efficiency of screening and cleaning, improving accuracy, and reducing the workload of data collection
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0032] The following examples are used to further describe the present invention in detail, but the examples do not limit the present invention in any form. Unless otherwise specified, the reagents, methods and equipment used in the present invention are conventional reagents, methods and equipment in the technical field, But it does not limit the present invention in any form.
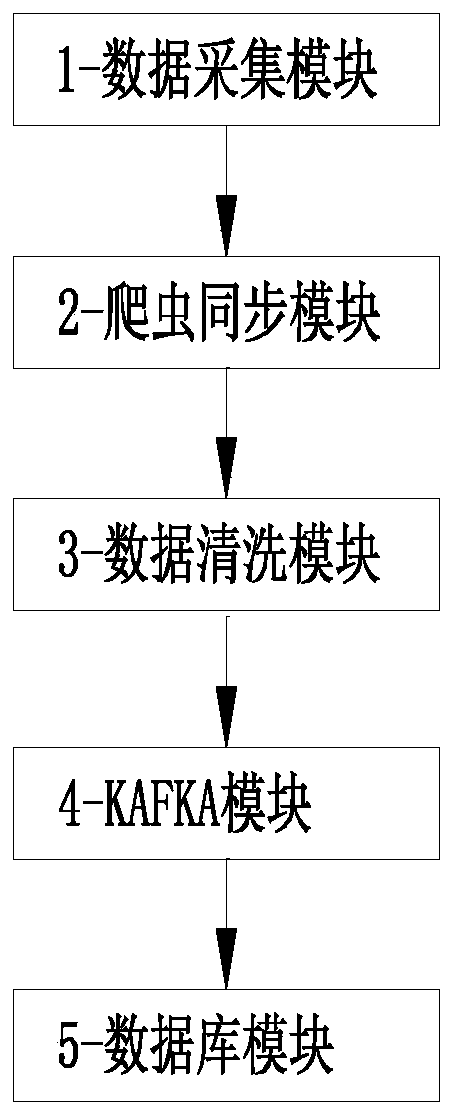
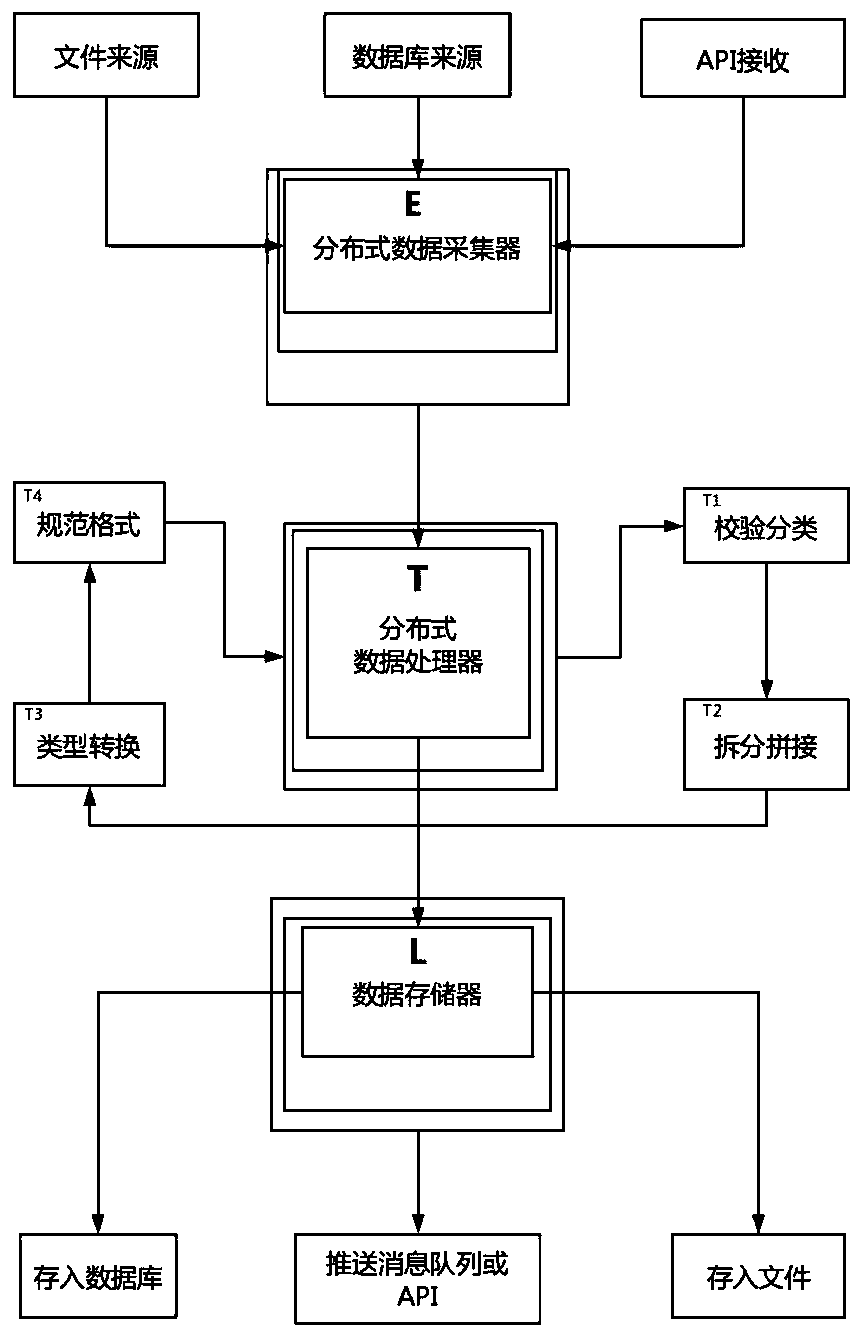
[0033] Such as Figure 1-2 As shown, the present embodiment discloses a method for cleaning Internet big data, comprising the following steps:
[0034]S1. Utilize the data collection module 1 to log in to the target server through the http protocol, and use regular expressions, xpath expressions and jsonpath expressions to extract the required data; wherein, the http protocol is a simple request-response protocol, which usually runs on over TCP. It specifies what kind of messages the client may send to the server and what kind of responses it may get. Request and response message headers are given ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More