

Optimal control method of gait of humanoid robot based on deep Q network
A humanoid robot and network technology, applied in the direction of adaptive control, general control system, control/regulation system, etc., can solve problems such as gait walking and other complex movements, and achieve the effect of fast and stable walking and increased walking speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0042] A gait control method for a humanoid robot based on a deep Q network, comprising:
[0043] Construct the gait model of the humanoid robot to realize the omnidirectional walking of the humanoid robot;
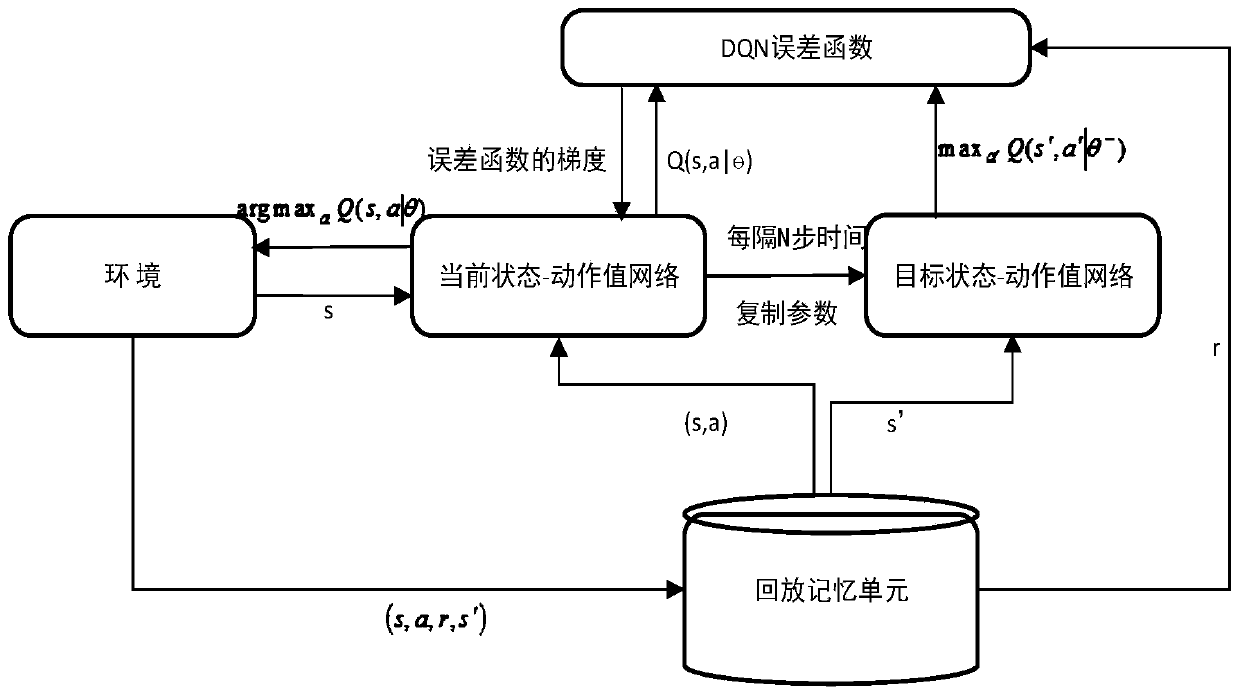
[0044] Obtain the interaction data between the humanoid robot and the environment during the walking process, store it in the memory data pool, and use it to provide training samples; the interaction data is a quadruple (s, a, r, s′), where s represents State parameters, a represents the dynamic parameters of the humanoid robot in state s, r represents the feedback reward value obtained by the humanoid robot in state s when performing action a, and s′ represents the reward value obtained by the humanoid robot after performing action a in state s next state;
[0045] Build a deep Q-network learning architecture, learn and train the deep Q-network based on the training samples of the memory data pool, and obtain the state-action strategy deep Q-network model of the humanoid ...
Embodiment 1-1
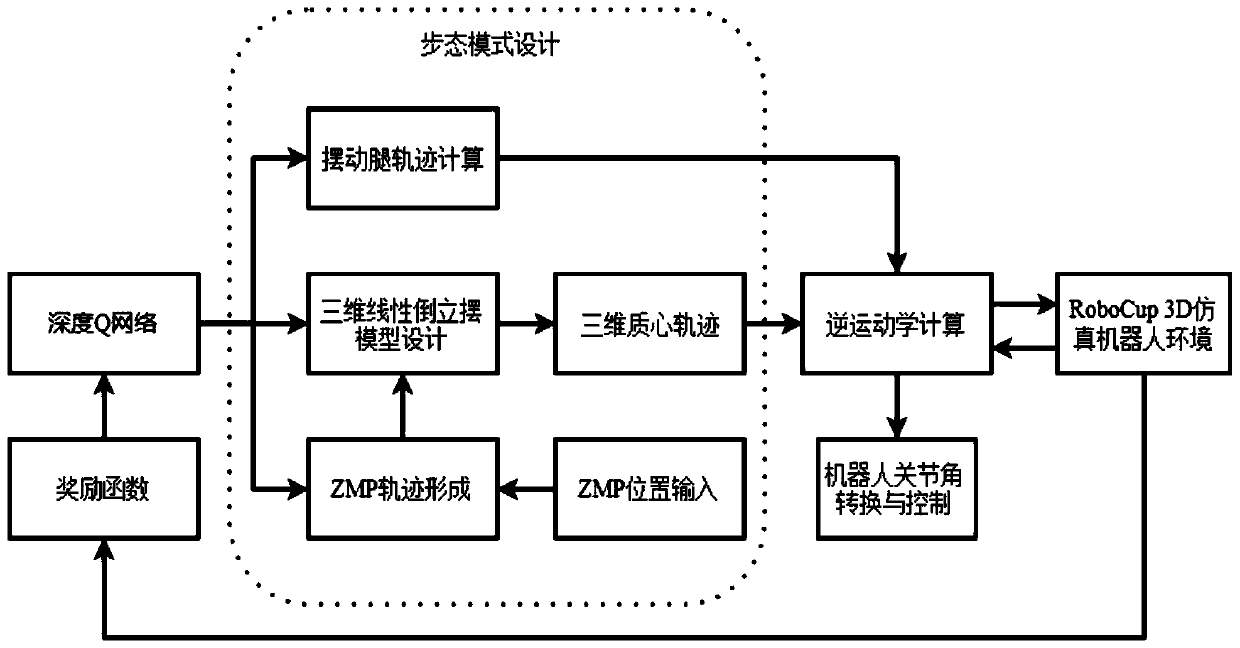
[0051] On the basis of Embodiment 1, this embodiment takes the simulation platform as an example to illustrate the gait control and optimization process of the humanoid robot, that is, this embodiment selects the NAO simulation robot as the experimental object, and the RoboCup 3D simulation platform as the experimental environment. During the training process, the gait model parameters and state parameters can be captured directly through the platform to fit the state-action value function generated by the robot walking, and the gait action performed by the current robot is selected through the action selection strategy, and the reward function is generated to update the DQN. It can reduce the problem of falling into local optimum caused by too many robot parameters in the optimization process, improve the walking speed of the robot, and realize the fast and stable walking of the humanoid robot.
[0052] refer to figure 1 and figure 2 As shown, this embodiment also includes,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More