

Robot imitation learning method based on virtual scene training
A learning method and virtual scene technology, applied in the field of imitation learning and artificial intelligence, can solve the problems of reducing the amount of calculation, the amount of calculation is large, and the learner cannot be rewarded frequently, so as to reduce the training cost and reduce the risk.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

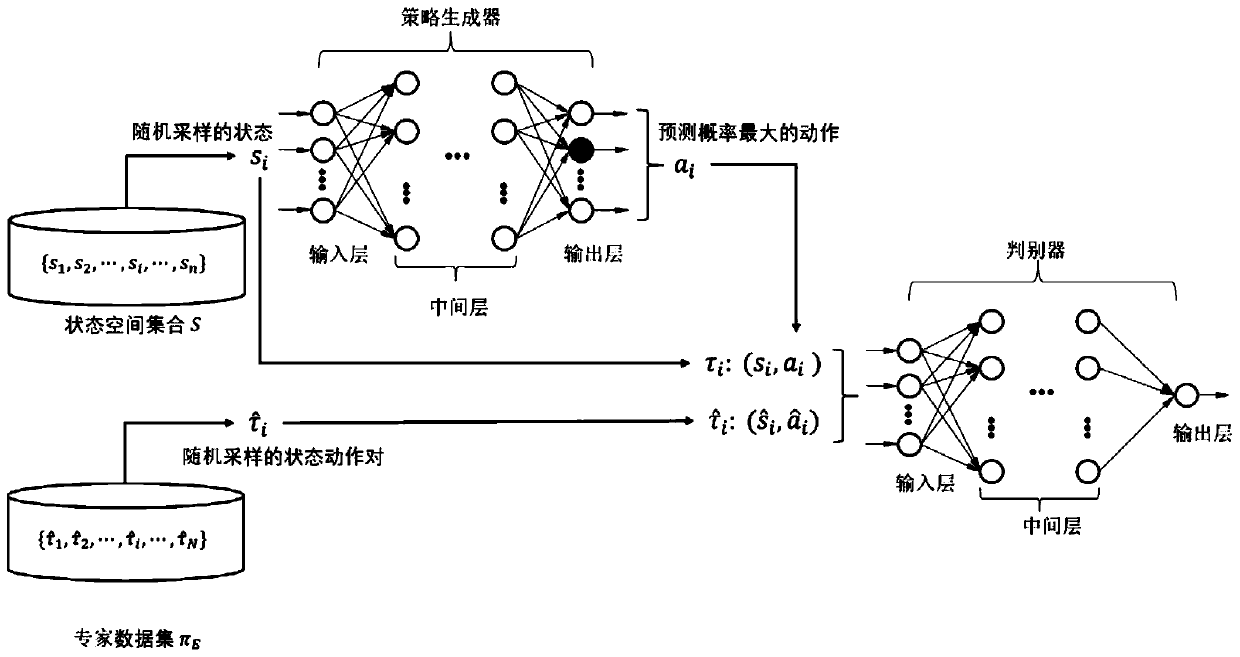
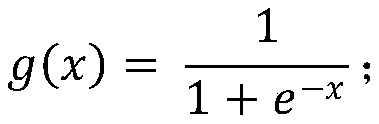
Examples
Embodiment
[0064] For ease of understanding, in this embodiment, the CartPole balancing car game is taken as an example.
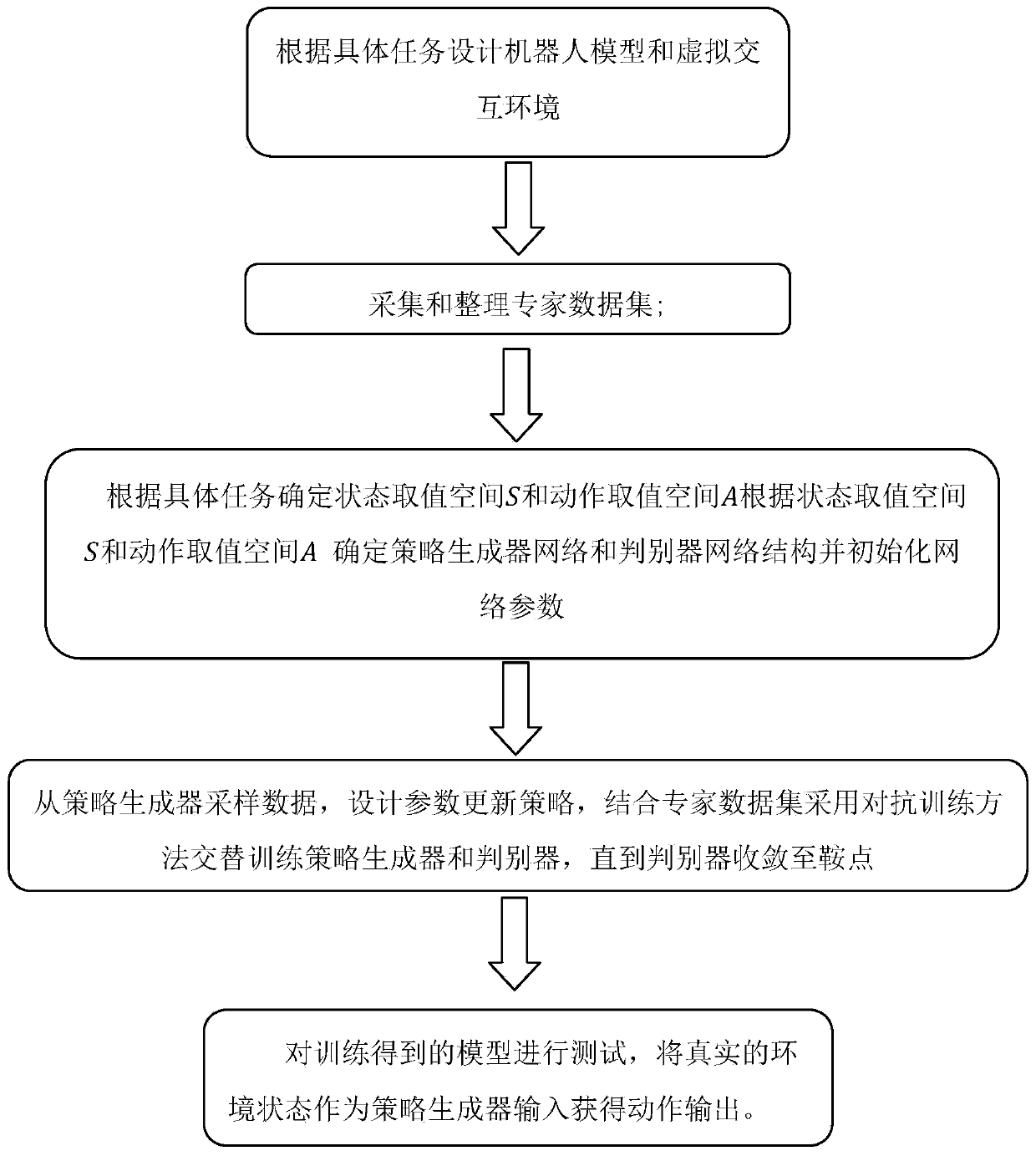
[0065] A robot imitation learning method based on virtual scene training, such as figure 1 shown, including the following steps:
[0066] S1. Designing a robot model and a virtual interactive environment according to specific tasks; including the following steps:
[0067] S1.1. Design the robot model and virtual environment according to specific tasks, and use the unity3D engine to design the simulation environment. The simulation environment is as close to the real environment as possible, including the car, the straight rod on the car, and the moving slide rail; its purpose is to provide a The visual graphical interface helps to train the model faster and migrate later, reduces the dangers that may be encountered in direct training in the real environment, and reduces training costs;
[0068] S1.2. Combining domain randomization method, randomize the environmenta...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More