

Sound source identification method and device, server and storage medium
A recognition method and sound source technology, applied in instruments, speech analysis, etc., can solve the problems of low voiceprint description accuracy, high model maintenance cost, and occupied resources, etc., and achieve easy calculation, easy storage, and individual representation. strong effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
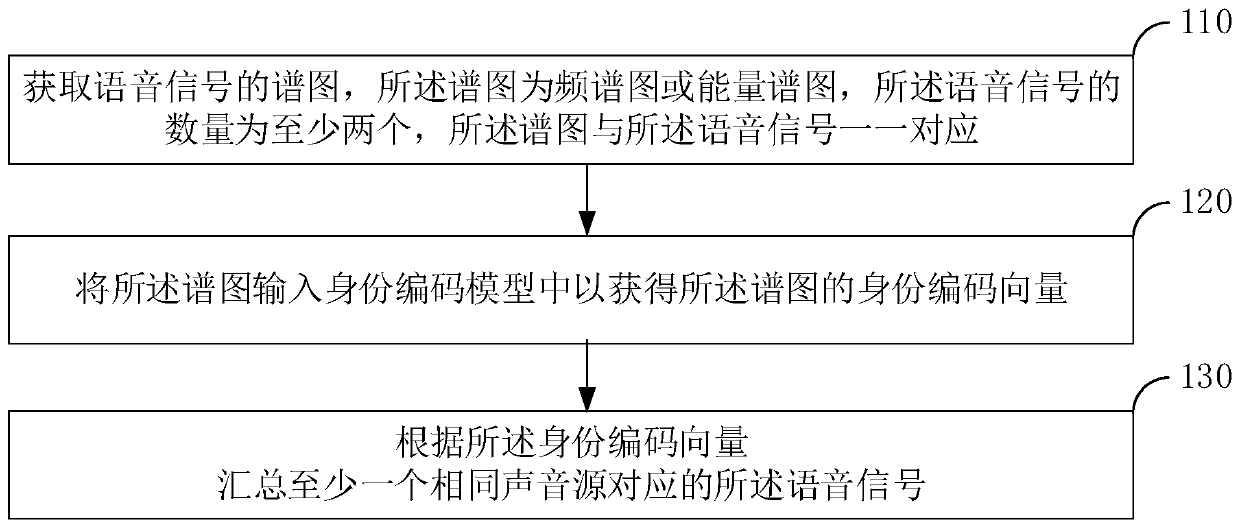
[0059] figure 1 The flow chart of the sound source identification method provided by Embodiment 1 of the present invention specifically includes the following steps:
[0060] Step 110, acquire the spectrogram of the speech signal, the spectrogram is a spectrogram or an energy spectrogram, the number of the speech signals is at least two, and the spectrogram corresponds to the speech signal one by one;
[0061] In this embodiment, each speech signal corresponds to a spectrogram.
[0062] Exemplarily, when the spectrogram is a speech spectrogram, specifically, the time-domain function of the speech signal can be obtained first, and the time-domain function is subjected to Fourier transform or Laplace transform to obtain the frequency-domain function. Preferably, the The frequency domain function is obtained by short-time Fourier transform (STFT) of the time domain function, and then the waveform diagram drawn according to the frequency domain function is the speech spectrogram....
Embodiment 2
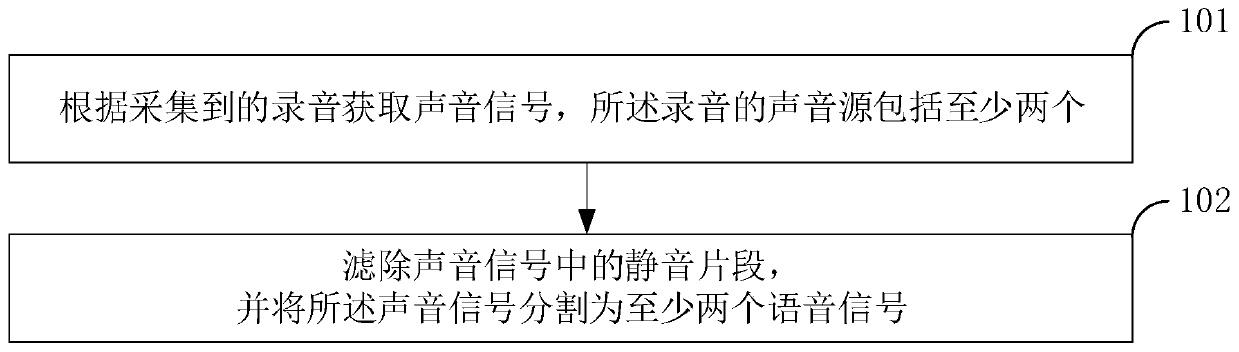
[0091] Figure 8 The flow chart of the sound source identification method provided by Embodiment 1 of the present invention specifically includes the following steps:
[0092] Step 210. Acquire sound signals according to the collected recordings, where the sound sources of the recordings include at least two.
[0093] In this embodiment, the recording is a recording of at least two people speaking, and preferably the recording is a telephone recording of at least two people speaking. Exemplarily, when the user dials the service party's telephone, the customer service of the telephone recording service party and the user's telephone recording .
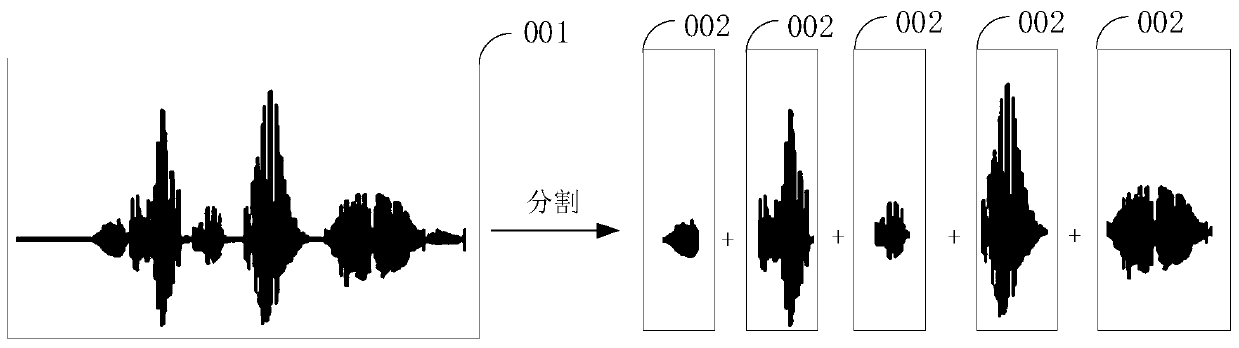
[0094] Step 220: Filter out the silent segment in the sound signal, and divide the sound signal into at least two speech signals.
[0095] In this embodiment, when at least two people speak, it usually starts after one person finishes speaking and the other person listens to the former person's words. The voice signal obtained after...
Embodiment 3
[0123] The sound source identification device provided by the embodiment of the present invention can execute the sound source identification method provided by any embodiment of the present invention, see Figure 11 , the identification device 3 of the sound source specifically includes:
[0124] A spectrogram acquisition module 31, configured to acquire a spectrogram of a speech signal, the spectrogram is a spectrogram or an energy spectrogram, the number of the speech signals is at least two, and the spectrogram corresponds to the speech signal one by one ;
[0125] An identity encoding vector acquisition module 32, configured to input the spectrogram into an identity encoding model to obtain an identity encoding vector of the spectrogram;
[0126] The speech signal summarization module 33 is configured to sum up the speech signals corresponding to at least one same sound source according to the identity coding vector.
[0127] In an alternate embodiment, see Figure 12 ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More