

Data processing method and device and storage medium
A data processing and data technology, applied in the field of data processing, can solve problems such as the inability to meet the accuracy and precision requirements of different data analysis results, reduce inaccuracy or insufficient accuracy of analysis results, optimize data processing, and improve accuracy. and precision effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0066] In order to understand the characteristics and technical contents of the embodiments of the present invention in more detail, the implementation of the embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. The attached drawings are only for reference and description, and are not intended to limit the embodiments of the present invention.
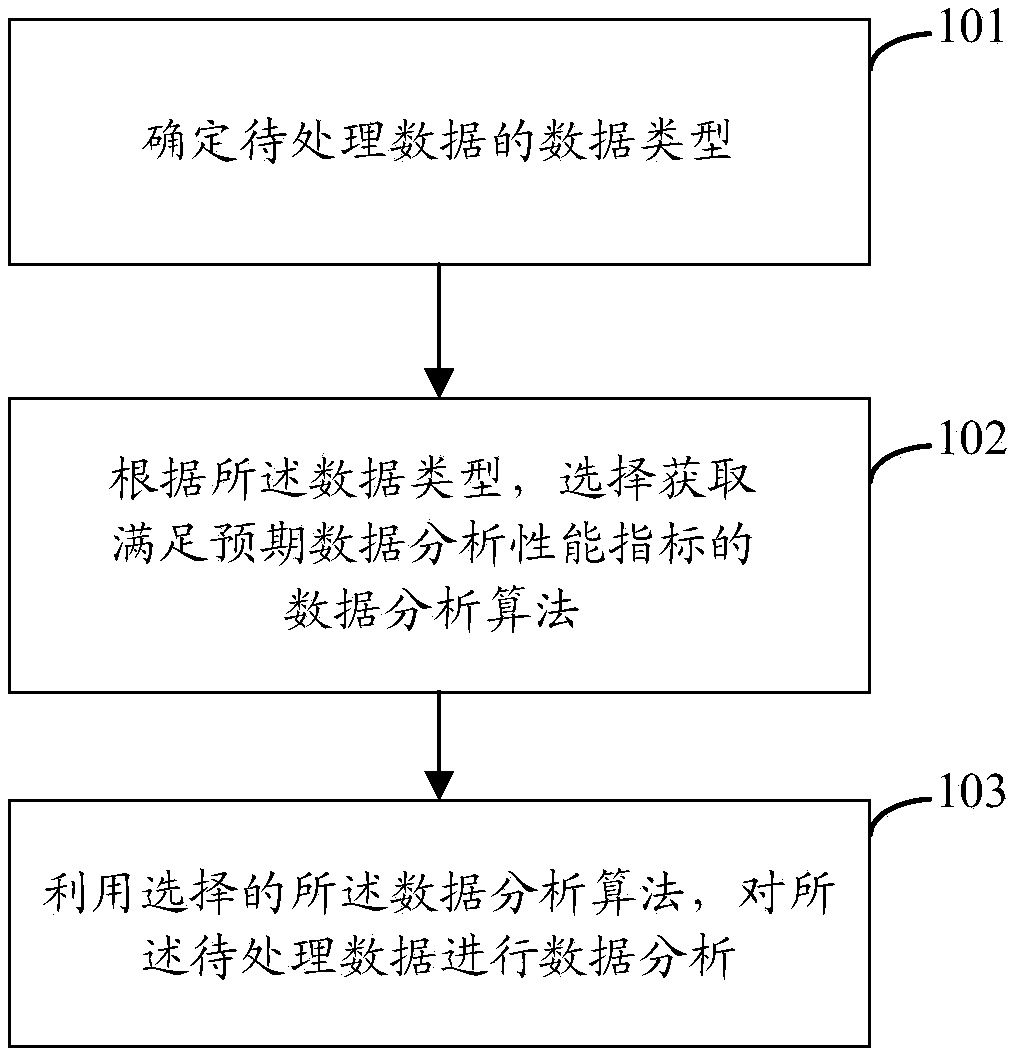
[0067] A data processing method in the embodiment of the present invention, such as figure 1 shown, including:
[0068] Step 101. Determine the data type of the data to be processed.
[0069] The data to be processed may be time series data. The data type may include: periodic data and non-periodic data other than the periodic data.
[0070] Wherein, the periodic data is the data with all the data generated within the period as a data analysis unit. For example: the monthly communication data of a certain mobile user, the daily system access data of a certain server devi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More