

Author disambiguation method and device based on subject tree clustering
A subject and author's technology, applied in text database clustering/classification, instrumentation, unstructured text data retrieval, etc., can solve the problems of new data training, large amount of data, low applicability, etc., to improve accuracy, The effect of improving quality
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
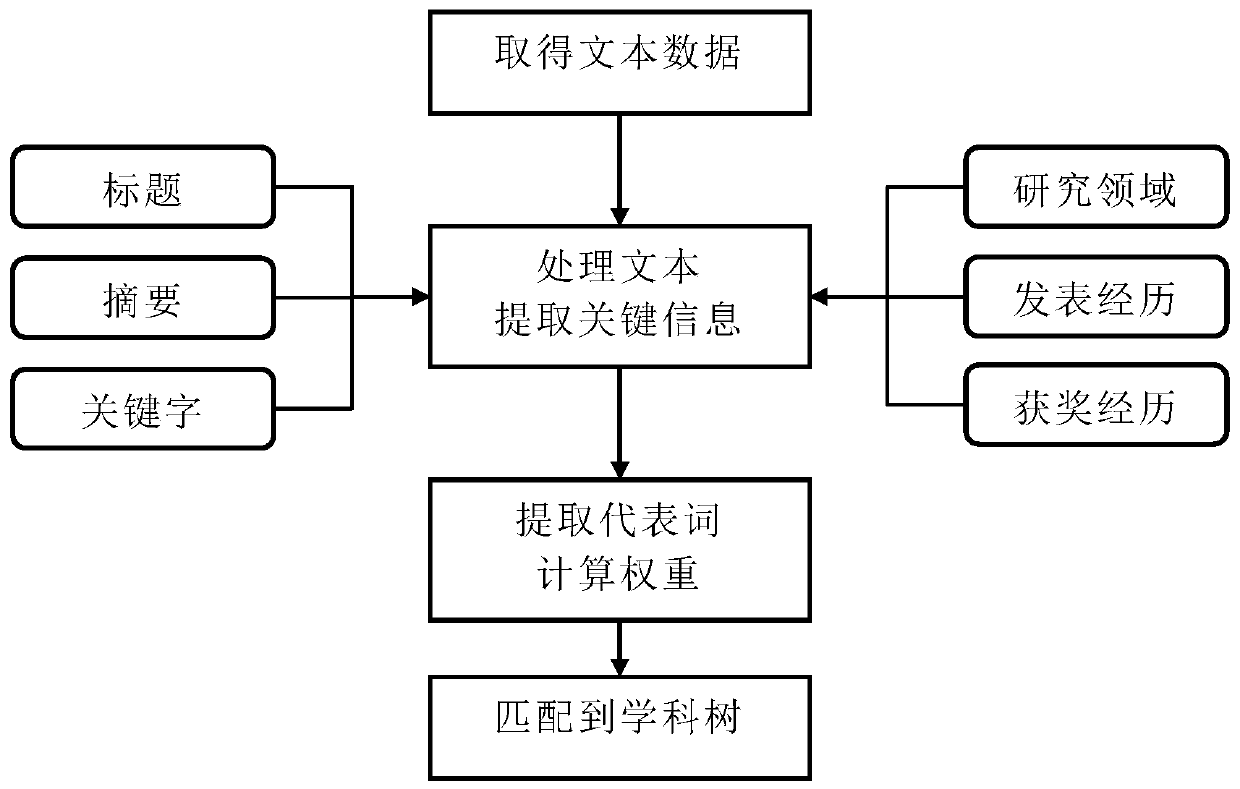
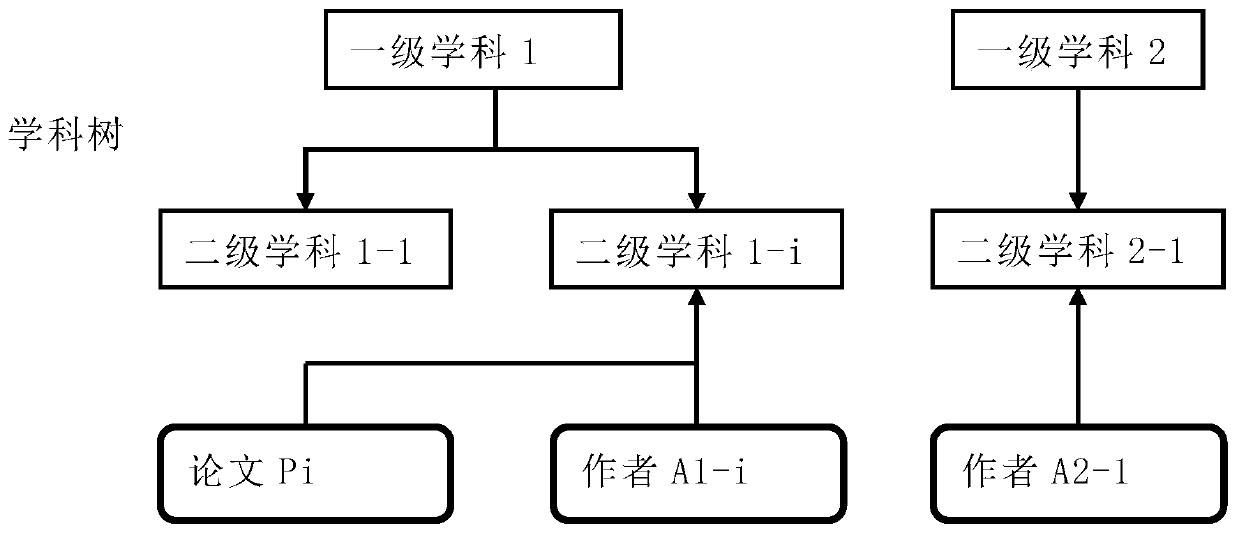
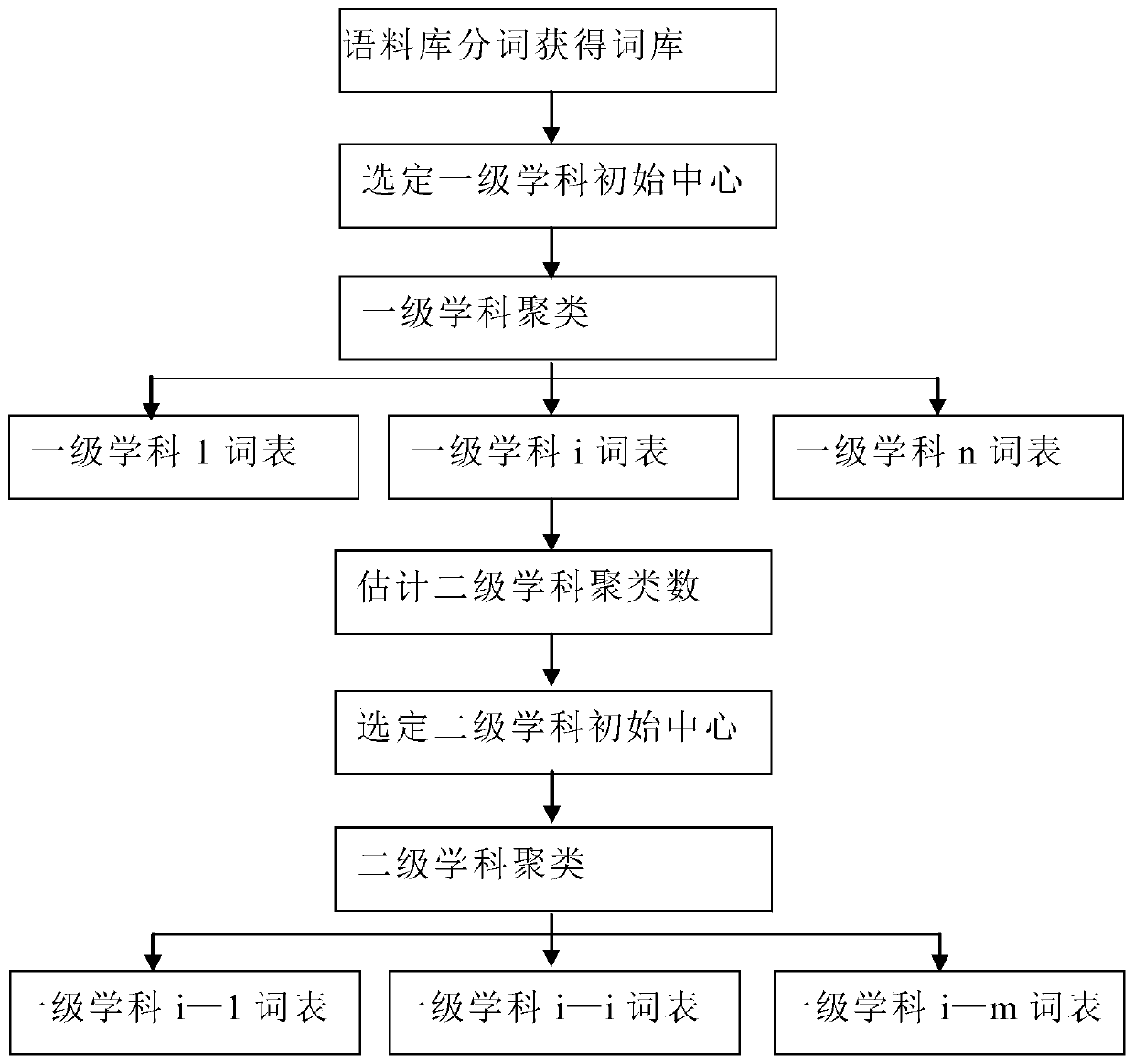
[0045] like Figure 1 to Figure 3 As shown, the author disambiguation method provided by the present invention includes the following steps:
[0046] 1. Obtain text data with the author of this article
[0047] The processor receives from the input the text data with the author of the article that needs to be disambiguated. In the embodiment of the present invention, the text data is described by taking papers as an example, which are called papers to be classified.
[0048]A set Ak={A1,...,An} of people with the same name with a given name K is stored in the memory, where K, k, and n are all natural numbers, and k∈K. Each element A1,...,An in Ak represents a realistic author with the same name but different persons, that is, there are n authors with a given name (or name number) Ak.
[0049] Given a collection of papers to be classified P={P1,...,Pn}, the author of each paper contains a given name Ak corresponding to the collection A of people with the same name. That is,...
no. 2 example
[0102] On the basis of the first embodiment, the following steps can be added to solve the situation that there is no author with the same name under a certain subject or.
[0103] 6. Determine whether there is an author with the same name under the subject node, if not, go to the next step; if so, determine that the author with the same name is the author of the text data;
[0104] 7. Match the candidate authors with the same name with each subject node in turn to calculate the matching degree;
[0105] Match each candidate author in the set Ak of persons with the same name with the subject one by one, and calculate the matching degree.
[0106] 8. Select a candidate author who is in the same discipline as the text data as the author of this article; if there is no candidate author of the same subject, it is judged that there is no author with the same name, and the author of this article is connected to the subject.
[0107] The numbering of steps 6 to 8 above is just to ...
no. 3 example
[0109] On the basis of the first embodiment, the following steps can be added to solve the situation that there are at least two authors with the same name under a certain subject (that is, the authors with the same name are different people, but the research directions of the two are the same, and they are the same subject).
[0110] 9. Determine whether there is one and only one author with the same name under the subject node, if not, go to the next step; if yes, determine that the author with the same name is the author of the text data;
[0111] 10. Determine whether there is no author with the same name in the same subject, if so, connect the author of this article to the subject, and add the author of this article to the candidate author of the subject; if not (indicating that there are multiple authors with the same name in the subject), Then go to the next step.
[0112] 11. Select the author of the paper with the highest matching degree in step 5 as the author of thi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More