

Method for quickly retrieving mass data
A massive data, fast technology, applied in structured data retrieval, digital data information retrieval, database indexing, etc., can solve the problem of waste of storage space
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] In order to facilitate the understanding of those skilled in the art, the present invention will be further described below in conjunction with the embodiments and accompanying drawings, and the contents mentioned in the embodiments are not intended to limit the present invention.
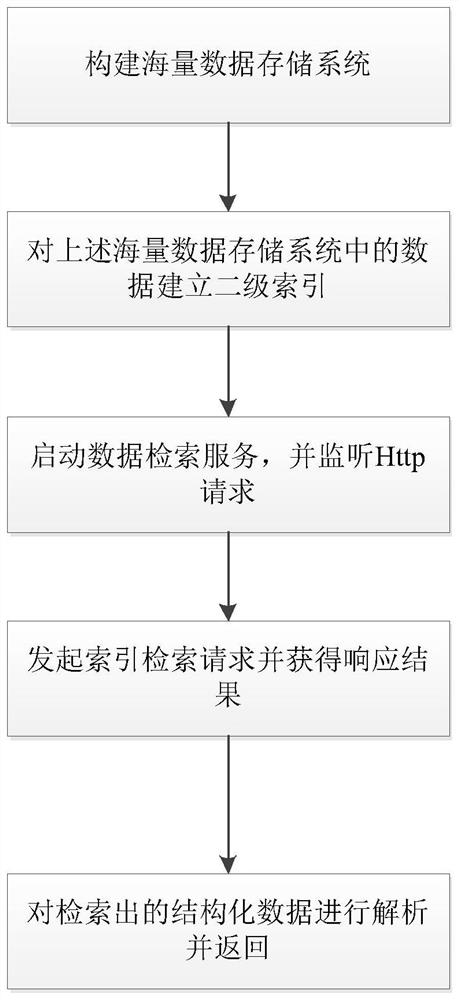
[0034] refer to figure 1 As shown, a kind of fast retrieval method for mass data of the present invention comprises steps as follows:
[0035] 1) Build a massive data storage system;
[0036] The mass data storage system is Apache HBase, which is a distributed and scalable mass data storage system based on Hadoop. The business data to be retrieved is stored in HBase according to the respective business design, and a suitable RowKey is designed. , which is used as the unique identifier of the record; let the data be evenly distributed to multiple RegionServers of HBase, improve the performance of concurrent processing, and avoid local overheating.
[0037] 2) Establish a secondary index for...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More