

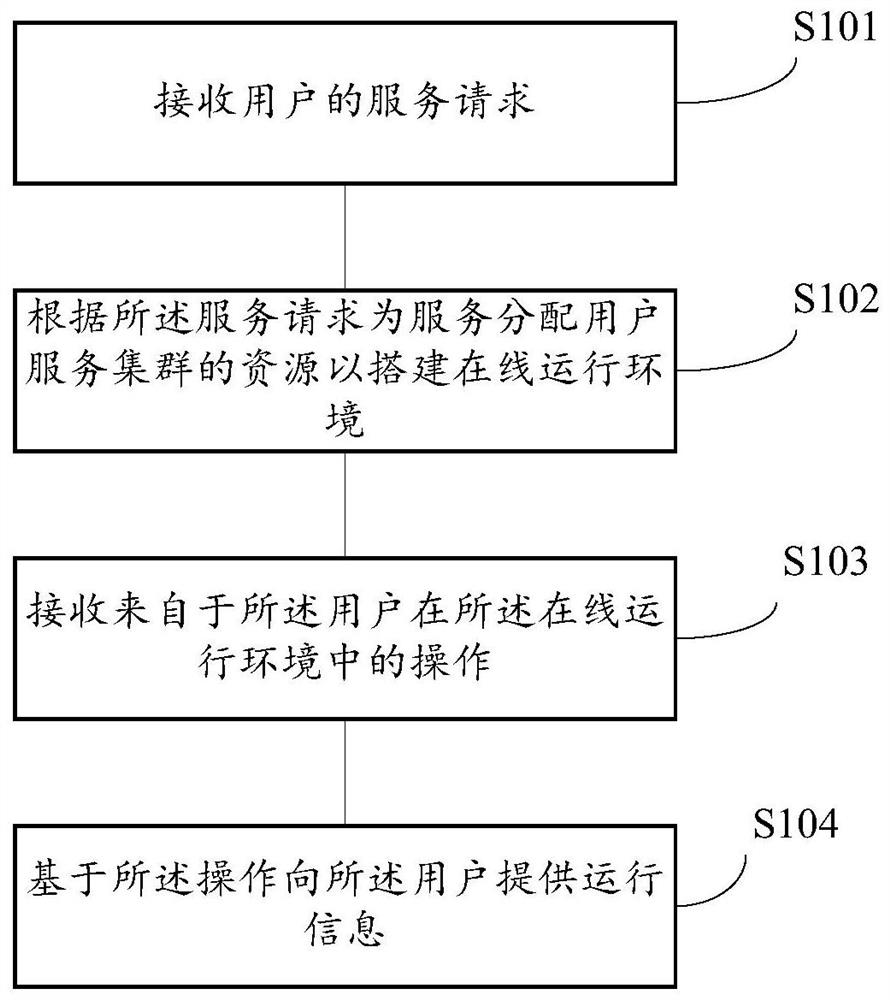
Method for constructing online machine learning project and machine learning system
A machine learning and project technology, applied in the field of machine learning, which can solve the problems of large differences in data set specifications, inability to analyze data and share experiments, and inability to save the experimental running status and data, so as to save storage space and improve Ease of access and improved readability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
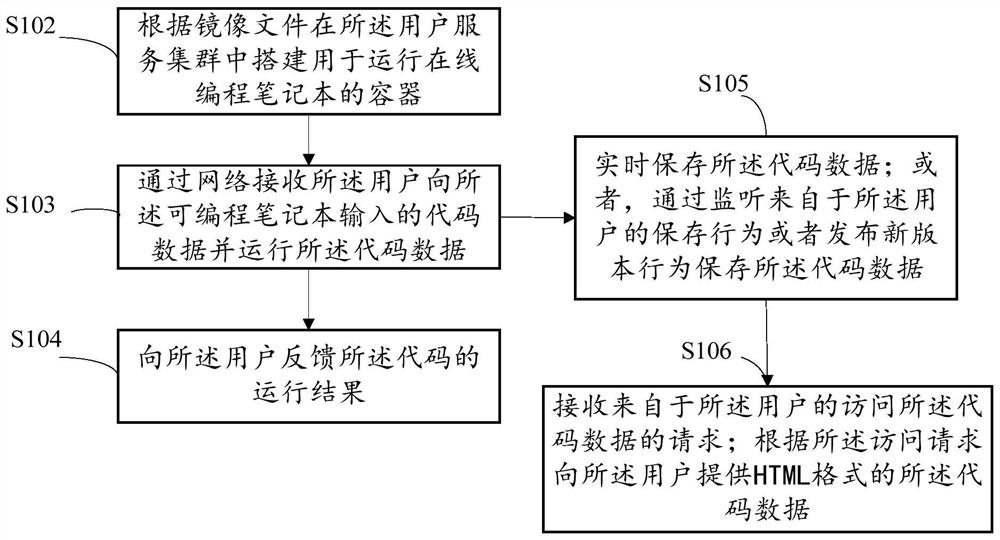
[0071] like image 3 As shown, when the service is the model development service, as an example, S102 includes: building a container for running an online programmable notebook in the user service cluster according to the image file; S103 includes: receiving the The user inputs the code data into the programmable notebook and runs the code data; S104 includes: feeding back the running result of the code to the user.
[0072] In order to improve the convenience for users to access codes, such as image 3 As shown, as an example, after S103 or while performing the input operation of S103, the method for constructing an online machine learning project further includes: S105, saving the code data in real time; or, by listening to the saving behavior from the user Or release a new version behavior to save the code data. The embodiment of the present application can save the code data of the user in the programmable notebook. Compared with the existing programmable notebook, the p...
example 2
[0075] like Figure 4 As shown, in some embodiments, the service is a model training service, and S102 includes: building a container for running an online programmable notebook in the user service cluster according to the image file; mounting the container in the container based on the NFS protocol The data set of the first project to which the service belongs; providing the code data of the first project; S103 includes: receiving the request from the user to access the target data set, wherein the target data set belongs to the first project Part or all of the data set; S104 includes: providing the user with the target data set and data within a predetermined range adjacent to the storage location of the target data set on the network storage server for the user to download . The embodiment of the present application uses NFS to mount the data set to the container of the built operating environment. Compared with the existing method of directly downloading the data set for ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More