

Voice recognition method and system based on triggered non-autoregressive model
An autoregressive model and speech recognition technology, applied in speech recognition, speech analysis, neural learning methods, etc., can solve problems such as acceleration and affecting decoding efficiency, and achieve the effects of improving decoding speed, improving accuracy, and avoiding timing dependence
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
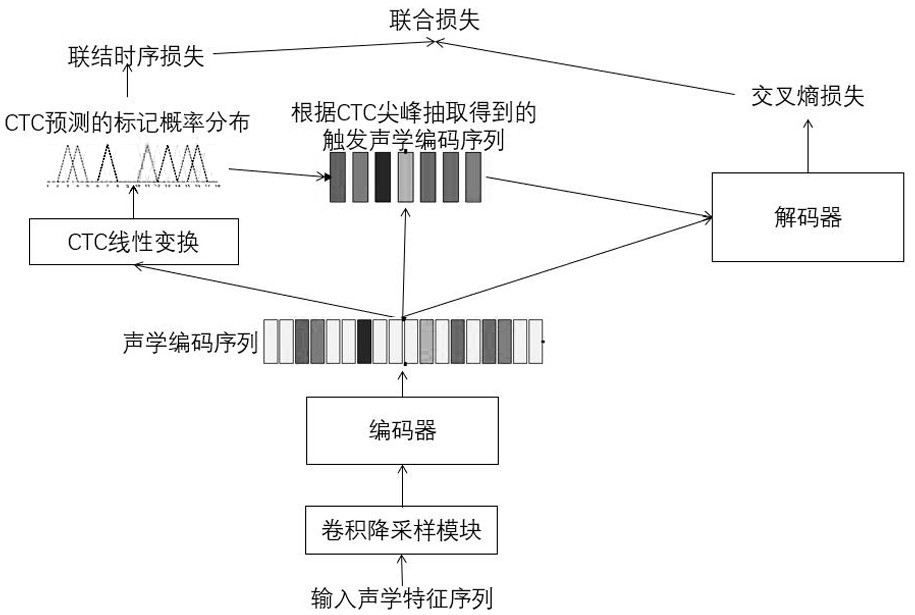
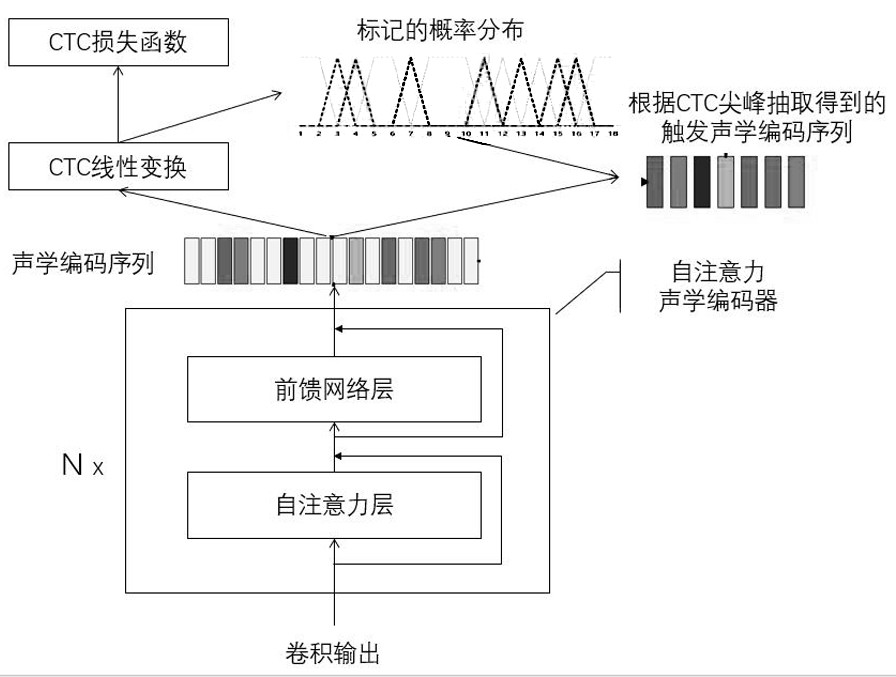
[0056] Streaming end-to-end speech recognition model and training method. Models based on self-attention transformation networks include acoustic encoders based on self-attention mechanisms and decoders based on self-attention mechanisms, such as Figure 1-4 shown, including the following steps:
[0057] Step 1, acquiring the voice training data and the corresponding text annotation training data, and extracting a series of features of the voice training data to form a voice feature sequence;
[0058] The goal of speech recognition is to convert continuous speech signals into text sequences. In the process of recognition, discrete Fourier transform is performed on the waveform signal in the time domain after windowing and framing, and the coefficients of specific frequency components are extracted to form a feature vector. The series of feature vectors constitute a sequence of speech features, and the speech features are Mel Frequency Cepstral Coefficients (MFCC) or Mel Filter...
Embodiment 2
[0084] like Figure 5 shown, a decoding method for a streaming end-to-end speech recognition model.
[0085] Decoding step 1, read the voice file from the file path and submit it to the processor;
[0086] The processor can be a smartphone, cloud server or other embedded device.
[0087] Decoding step 2, extracting features from the input speech to obtain a speech feature sequence;
[0088]The speech features are Mel Frequency Cepstral Coefficients (MFCC) or Mel Filter Bank Coefficients (FBANK), and the feature processing method is consistent with the training process.
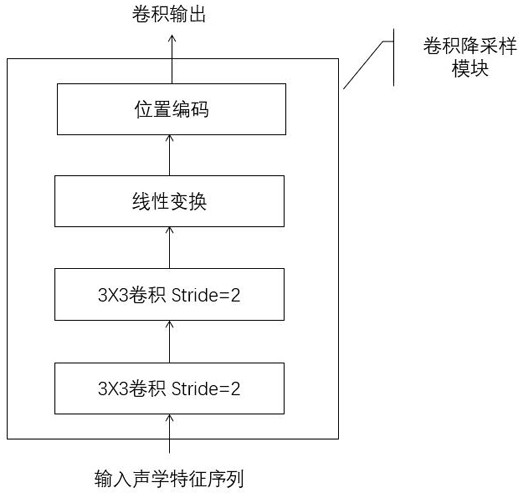
[0089] Decoding step 3, the speech feature sequence is sequentially passed through the convolution downsampling module and the encoder to calculate the encoding state sequence;
[0090] Decoding step 4, passes the coding state sequence through the linear transformation of the CTC part, and calculates the probability distribution of the mark, and further obtains the probability that each position of the codi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More