Complex scene voice recognition method and device based on multiple modes
A speech recognition and complex scene technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as limited application of single-modal speech recognition technology
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0077] In order to better understand the contents of the present invention, an example is given here.
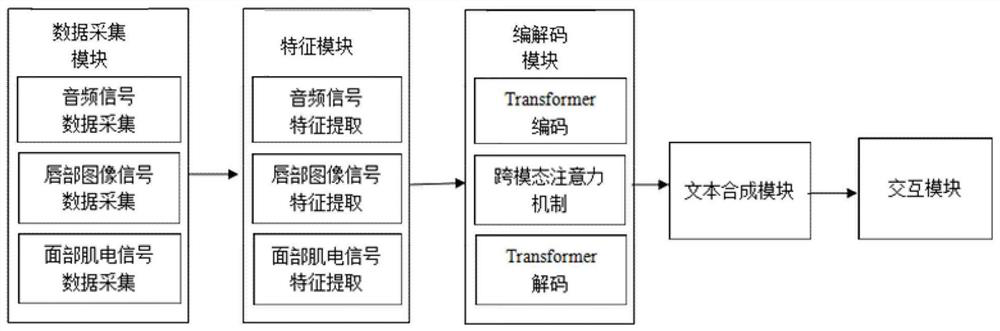
[0078] On the one hand, the present invention proposes a complex scene speech recognition method based on multimodality, figure 1 It is an overall schematic diagram of a complex scene speech recognition device based on multimodality. The method includes:
[0079]S1, taking the change of the lip image collected by the image sensor as a sign of multi-modal data input, that is, the lip image data collection device monitors whether the user's lip image changes, and if it detects that the collected user's lip image changes , it is considered that the user sends out voice input, and the audio signal, lip image signal and facial EMG signal corresponding to the voice input are collected synchronously;
[0080] S2, according to the audio signal, the lip image signal and the facial electromyographic signal, determine the multi-source data characteristics of the signal in the space a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More