Large-scale data retrieval method based on improved hash learning algorithm
A large-scale data and learning algorithm technology, applied in the field of deep learning, can solve the problem of low search accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0071] A large-scale data retrieval method based on an improved hash learning algorithm, comprising the following steps:
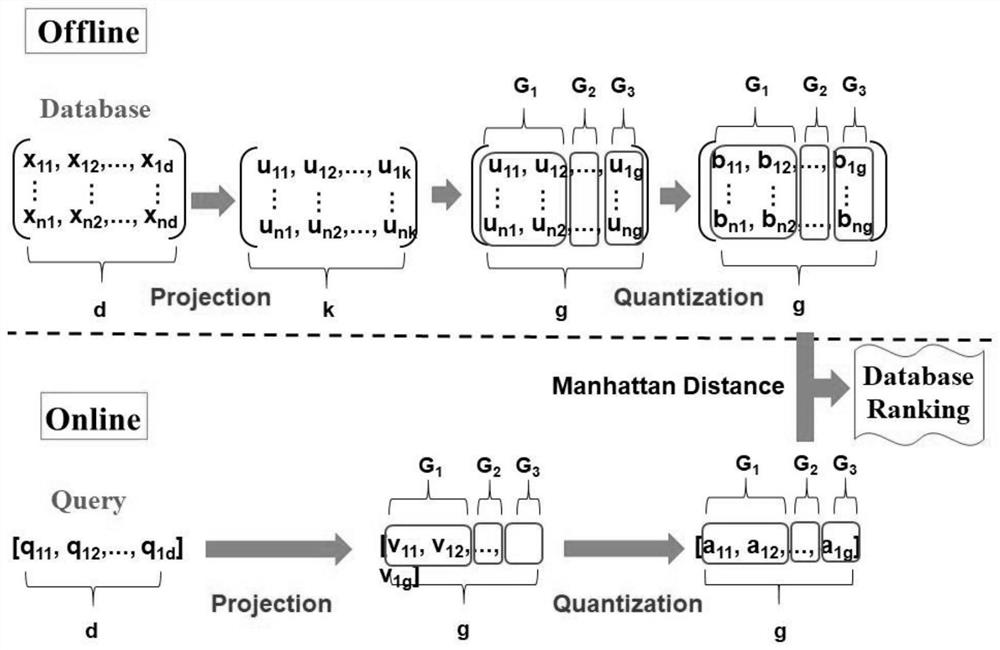
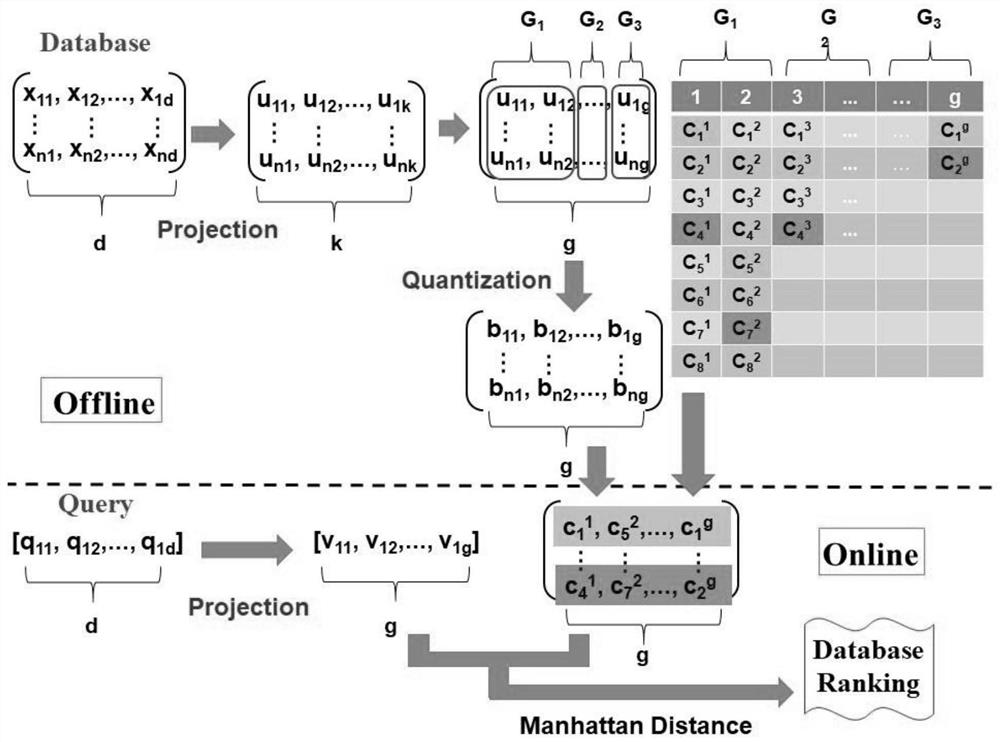
[0072] Step 1: where the existing projection matrix is learned in spectral hashing, principal component analysis hashing, and iterative quantization, such as figure 1 and figure 2 Projection is performed as shown in the projection process in the left part of the upper half area;
[0073] Step 2: Analyze the importance of each projection dimension, and define importance as discriminative power, select a subset of projection dimensions with higher resolution, and use the minimum variance (MV) algorithm (such as figure 1 and figure 2 grouping process in the middle part of the upper half) to group them;
[0074] Step 3: For projection dimensions in the same group, which have similar discriminative power, we adaptively learn a threshold with a two-step iterative algorithm to divide them into the same number of regions;
[0075] Step 4: In the quantizati...
Embodiment 2
[0079] The specific algorithm and steps of embodiment 1 retrieval method are as follows:
[0080] Step 1: For database point x i ∈ R d , we first map it to the projected point u i ∈ R k (Such as figure 1 and figure 2 shown in the projection process on the left part of the upper half). make is an n-dimensional data point. μ represents the average value of the data, P∈R d×k Represents projection matrices learned in spectral hashing, principal component analysis hashing, and iterative quantization. for any x i ∈X, calculate the jth projection dimension:
[0081] u ij =p' j (xi -μ) (1)
[0082] where p j Representing the jth column of P, the purpose of centralizing X is to ensure that the bias in each projected dimension is based on zero.
[0083] Step 2: Analyze the importance of each projection dimension with an analytical model similar to Principal Component Analysis (PCA), and define importance as discriminative power. Let U={{u ij} n i=1} k j=1 ∈R n×k is...
Embodiment 3
[0117] Embodiment 3: (verification instance)
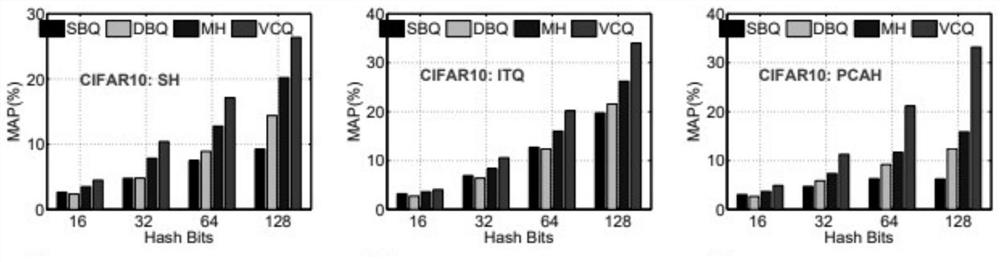
[0118] We conduct experiments on five common public datasets SIFT-10K, SIFT-1M, CIFAR10, MNIST and NUS-WIDE-SCENE. The SIFT dataset is an evaluation set, especially for nearest neighbor search applications. There are 10,000 descriptors in the SIFT database, and 35,000 training points.
[0119] The query set is a subset of the training set containing 100 points. SIFT-1M also consists of 128-D SIFT descriptors, but larger than SIFT-10K, which contains 100,000 training points, 1,000,000 database points, and 10,000 query points.
[0120] For the SIFT-10K and SIFT-1M datasets, 100 exact nearest neighbors for each query point are provided in 100×100 and 10000×100 ground-truth neighbor matrices, respectively.
[0121] CIFAR10 is a subset of the tiny image dataset. It consists of 60,000 images of 32×32 pixels divided into 10 categories: airplane, car, bird, cat, deer, dog, frog, horse, boat, and truck. The dataset is divided into a d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More