

Multi-speaker and multi-language speech synthesis method and system thereof
A speech synthesis and speaker technology, applied in speech synthesis, speech analysis, instruments, etc., to achieve the effects of high voice quality, fast speech synthesis, and fluent conversion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
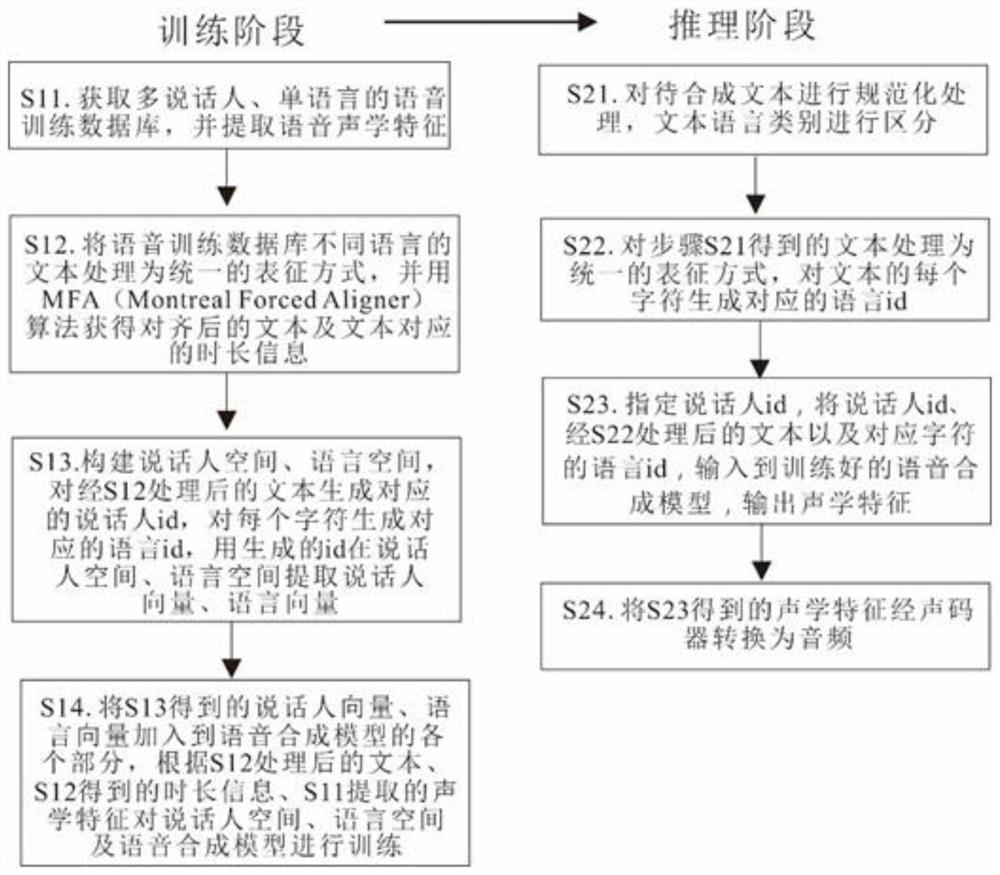
[0040] combined with figure 1 As shown, a multi-speaker, multi-language speech synthesis method, including:
[0041] Training phase:
[0042] Step S11: Obtain a multi-speaker and single-language speech training database, extract speech acoustic features, and the multi-speaker and single-language speech training data includes multi-speaker speech data and corresponding texts in at least two or more different languages; Speech acoustic features include Mel spectral features, spectral energy features, and fundamental frequency features; optionally, Chinese and English speech databases are selected as training databases, and the Chinese data set can use Biaobei’s public female voice database and our own recordings covering 20 Multiple voice databases; English voice databases can use LJSpeech, VCTK and other public databases;
[0043] Step S12: Process the texts in different languages of the speech training database into a unified representation, that is, process them into a un...
Embodiment 2
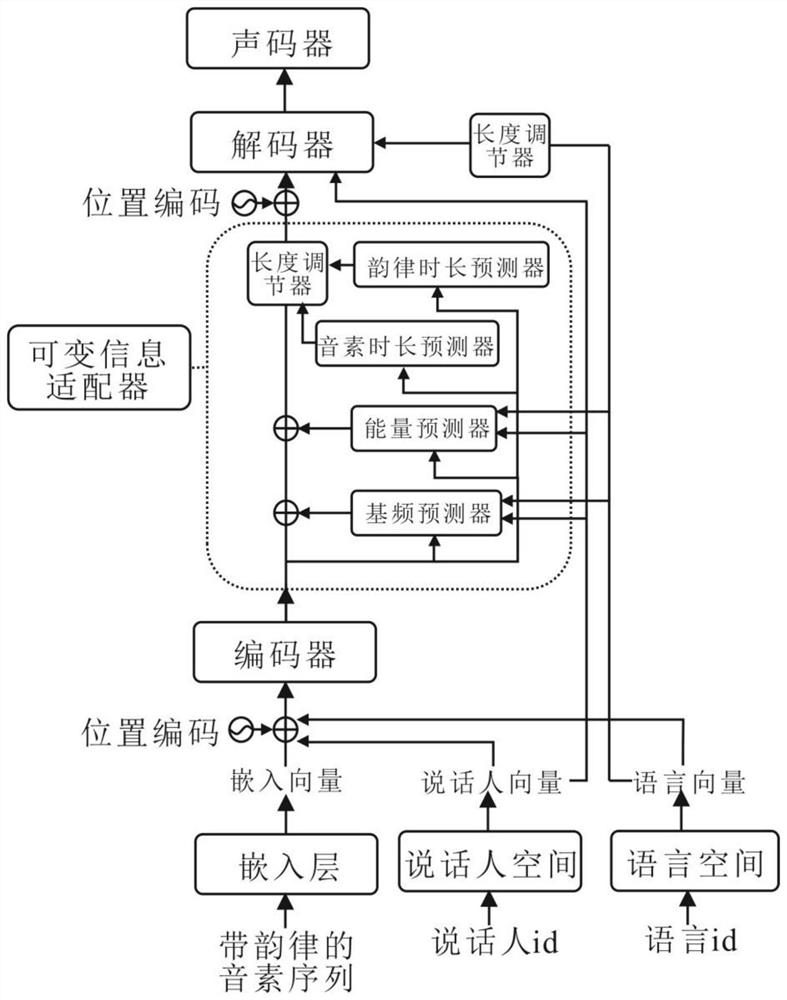
[0056] A multi-speaker, multi-language speech synthesis system, including a text processing module, an information marking module, an information encoding module, an acoustic feature output module and a vocoder module, wherein:
[0057] The text processing module is used to normalize the text, classify the text according to the language and process the text in different languages into a unified expression;
[0058] Optionally, process the text in different languages of the speech database into a unified phoneme expression, or process the text in different languages into a unified Unicode encoding expression; if it is used for training, use the MFA algorithm to convert text and audio in different languages Align, obtain the aligned text and the corresponding duration of the text, convert the duration into the number of frames, and the sum of the duration and the number of frames is equal to the sum of the extracted Mel spectrum features;
[0059] The information marking m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More