

Rhythm-controllable Chinese and English mixed speech synthesis method and system
A speech synthesis, Chinese and English technology, applied in speech synthesis, speech analysis, neural learning methods, etc., can solve problems such as unusable, naturalness of long sentence synthesis, complex models, etc., to reduce computing resource requirements and simplify training The complexity and the effect of improving fault tolerance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
preparation example Construction
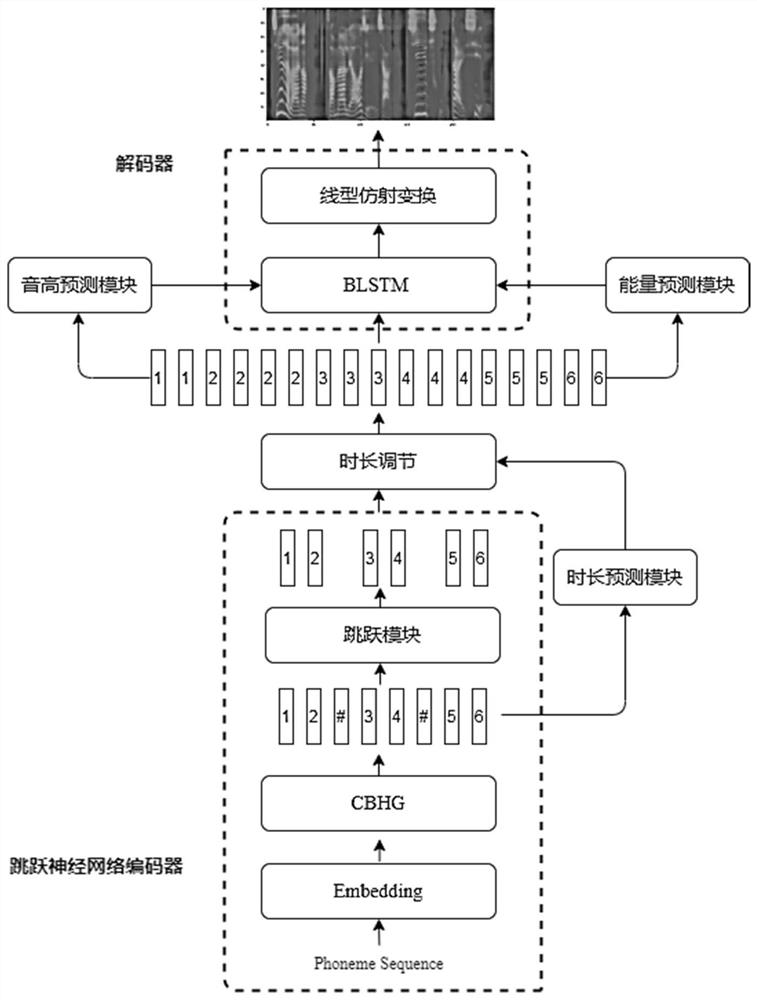
[0036] Such as figure 1 As shown, a kind of rhythm controllable Chinese-English mixed speech synthesis method of the present invention comprises the following steps:
[0037] Step 1, carry out preprocessing for the Chinese-English text data sequence of the band prosodic label of input, as the input of jumping neural network coder; Described jumping neural network coder is made of Embedding embedding layer, CBHG module, jumping module;
[0038] Step 2, for the output of the jumping neural network encoder, combined with the output of the CBHG module, through the adjustment of the duration, the text encoding information after the duration adjustment is obtained;
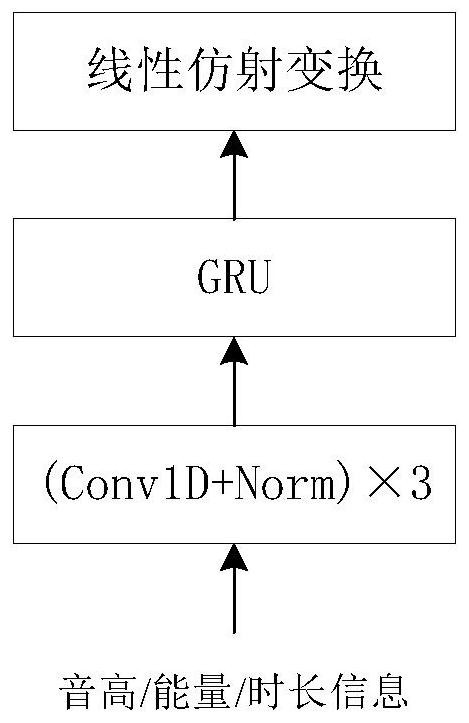
[0039]Step 3. The time-adjusted text coding information is used as the input of the pitch prediction module and the energy prediction module respectively to obtain the predicted pitch and predicted energy; combine the predicted pitch, predicted energy and the time-adjusted text coding information Finally, as the input ...
Embodiment
[0090] The present invention is tested on a text dataset containing 12,500 pieces of audio and corresponding prosodic annotations, including 10,000 pieces in Chinese, 2,000 pieces in English, and 500 pieces mixed in Chinese and English. The present invention carries out following pretreatment to data set:
[0091] 1) Extract Chinese and English phoneme files and corresponding audio, and use the open source tool Montreal-forced-aligner to extract the pronunciation duration of the phoneme.
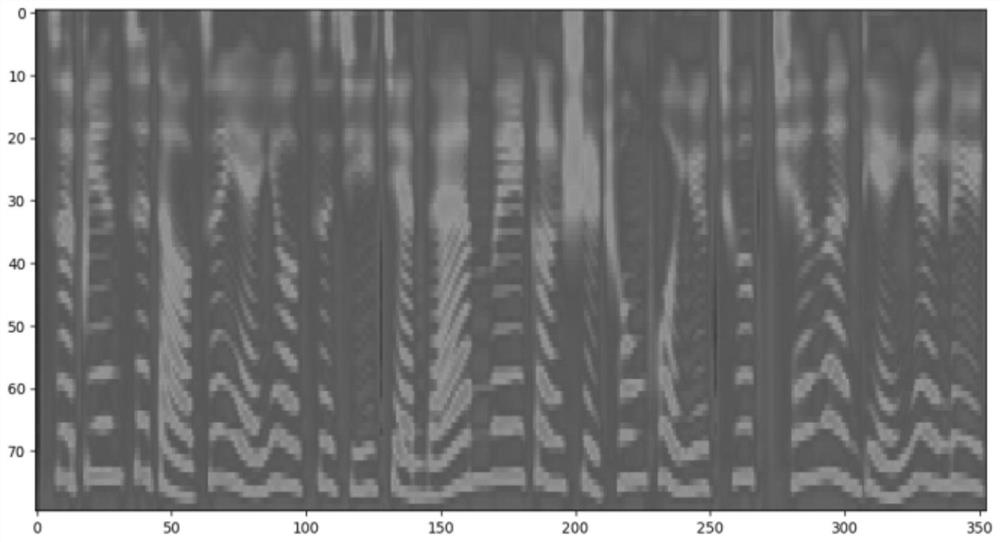
[0092] 2) Extract the mel spectrum for each audio, where the window size is 50 milliseconds, the size of the frame shift is 12.5 milliseconds, and the dimension is 80 dimensions.
[0093] 3) For each audio, the pitch of the audio is extracted using the World vocoder.
[0094] 4) Summing the mel-spectrum extracted from the audio in dimensions to obtain the energy of the mel-spectrum.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More