Fraud phone recognition method, system and equipment based on multi-source features
A technology of fraudulent calls and identification methods, applied in the information field, can solve problems such as no mention, inconvenience in daily life, and affecting user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

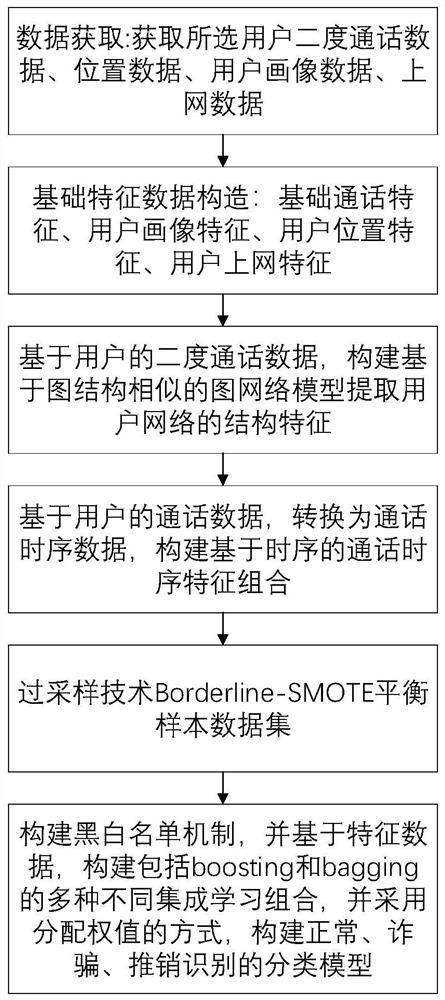
Examples
Embodiment Construction
[0052] The method for identifying fraudulent calls based on multi-source features provided by the present invention includes: the user selects a normal number, a promotional number and a fraudulent number, constructs a more practical user classification, and based on the second call of the selected user for a period of time Signaling, portrait data, location data, and Internet access data construct multi-source feature indicators, including basic features of user call data, user basic call features, portrait features, user location and Internet access features, and a graph network model based on similar graph structures ——Struct2Vec extracts the structural features of the user's second-degree network, identifies fraudulent pattern structures such as multi-point and one-line, and converts the user's second-degree call data into call time series data, extracts time-series-based feature combinations, and builds multi-source features. Use the improved smote oversampling method Bord...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com