

Binocular vision positioning method based on semantic target
A binocular vision positioning and target technology, applied in image analysis, instruments, computing and other directions, can solve the problems of high layout cost, inability to locate indoors, low positioning accuracy, etc., to achieve strong autonomy, fast and accurate positioning services, The effect of high positioning accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
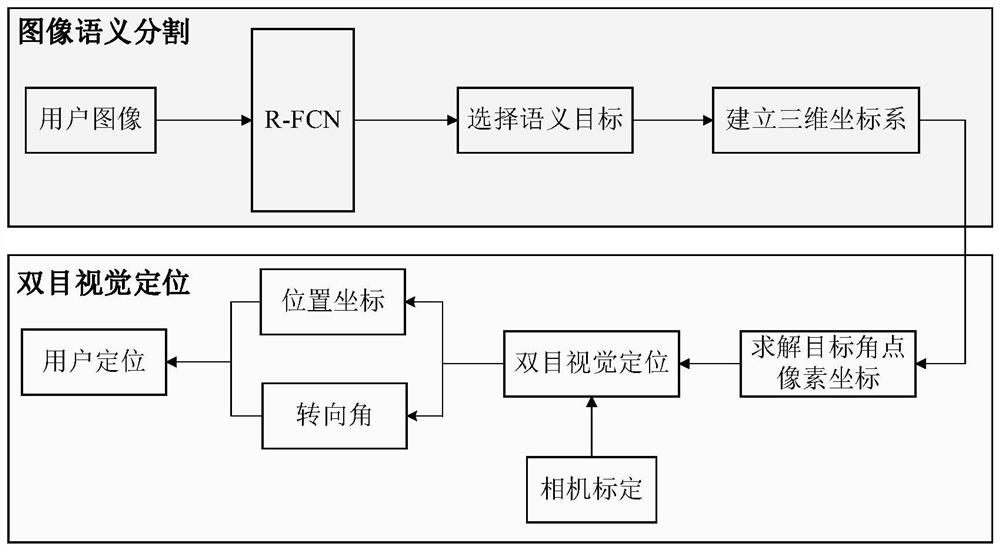
[0033] Specific implementation mode one: combine figure 1 Describe this embodiment, the specific process of a binocular vision positioning method based on semantic targets in this embodiment is:
[0034] It is divided into two modules: image semantic segmentation and binocular vision positioning;
[0035] Image Semantic Segmentation Module:
[0036] Step 1. The user uses the binocular camera to shoot the scene currently seen, and obtains two left and right images;
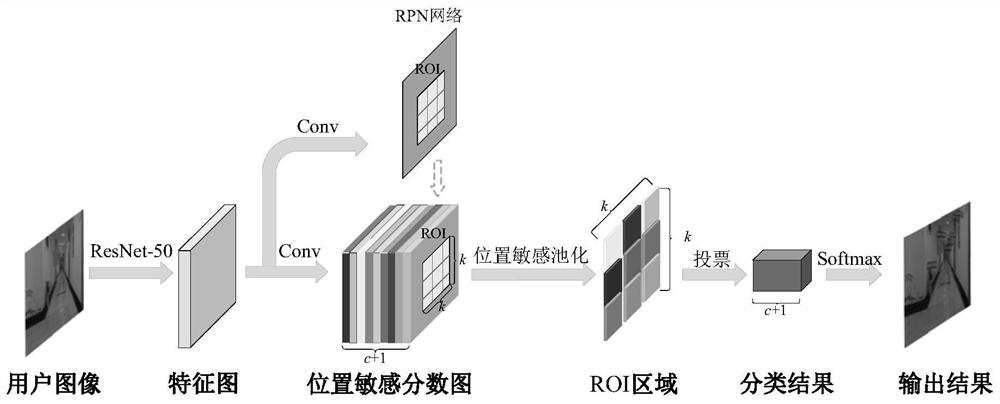
[0037] Step 2. Input the left and right images captured by the binocular camera into the trained R-FCN semantic segmentation network. The R-FCN semantic segmentation network identifies the semantic targets contained in the current left and right images, and each semantic target Corresponding corner coordinates;
[0038]Step 3: The user selects a semantic target shared by the left and right images among many semantic targets, and establishes a three-dimensional coordinate system of the target based on the corner ...
specific Embodiment approach 2
[0043] Specific embodiment two: the difference between this embodiment and specific embodiment one is that the specific training process of the trained R-FCN semantic segmentation network in the step 2 is:
[0044] The R-FCN semantic segmentation network consists of a fully convolutional network FCN, a candidate region generation network RPN, and a ROI sub-network;
[0045] The purpose of using the semantic segmentation technology in the present invention is to identify the semantic targets contained in the images taken by the user, and judge the position of the user in the indoor environment according to these targets, which is also in line with the use of surrounding landmark buildings when people enter an unknown place. Identify the characteristics of your location. The semantic segmentation network used in this paper is R-FCN, which is a two-stage target detection model developed from Faster R-CNN. It follows the idea of full convolutional network FCN and solves the prob...
specific Embodiment approach 3
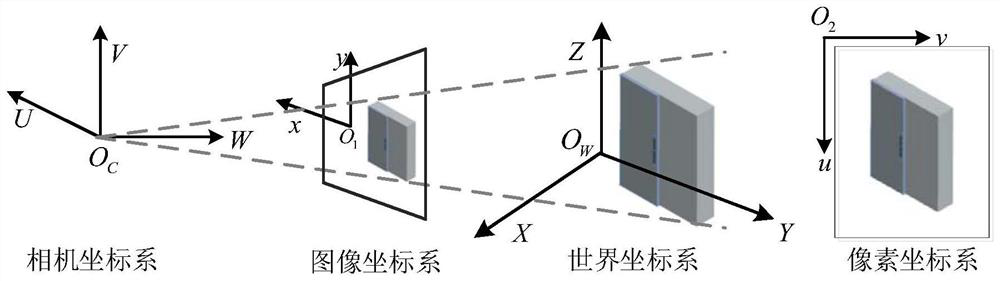
[0073] Embodiment 3: The difference between this embodiment and Embodiment 1 or 2 is that in the step 6, the corner point of the semantic target based on the step 4 corresponds to the pixel coordinate difference in the left and right images and the binocular image after step 5 is calibrated. The camera uses the binocular vision positioning algorithm to solve the current user's position coordinates and steering angle relative to the target in the three-dimensional coordinate system (indoor scene) established in step 3, to realize the positioning of the user; the specific process is:
[0074] After we use R-FCN to identify the semantic target contained in the user image and calculate the pixel coordinates corresponding to the target corner in the user image, then we will use the difference between the target corner coordinates in the left and right images to solve the current user and The distance of the target, and then restore the user's three-dimensional coordinates and steeri...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More