

A Speech Synthesis Method Based on Generative Adversarial Networks
A speech synthesis, generative technology, applied in speech synthesis, biological neural network model, speech analysis, etc., can solve the problems of slow speed, little improvement in synthesis speed, difficult application, etc., achieve fast speed and small model parameters , to ensure the effect of clarity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
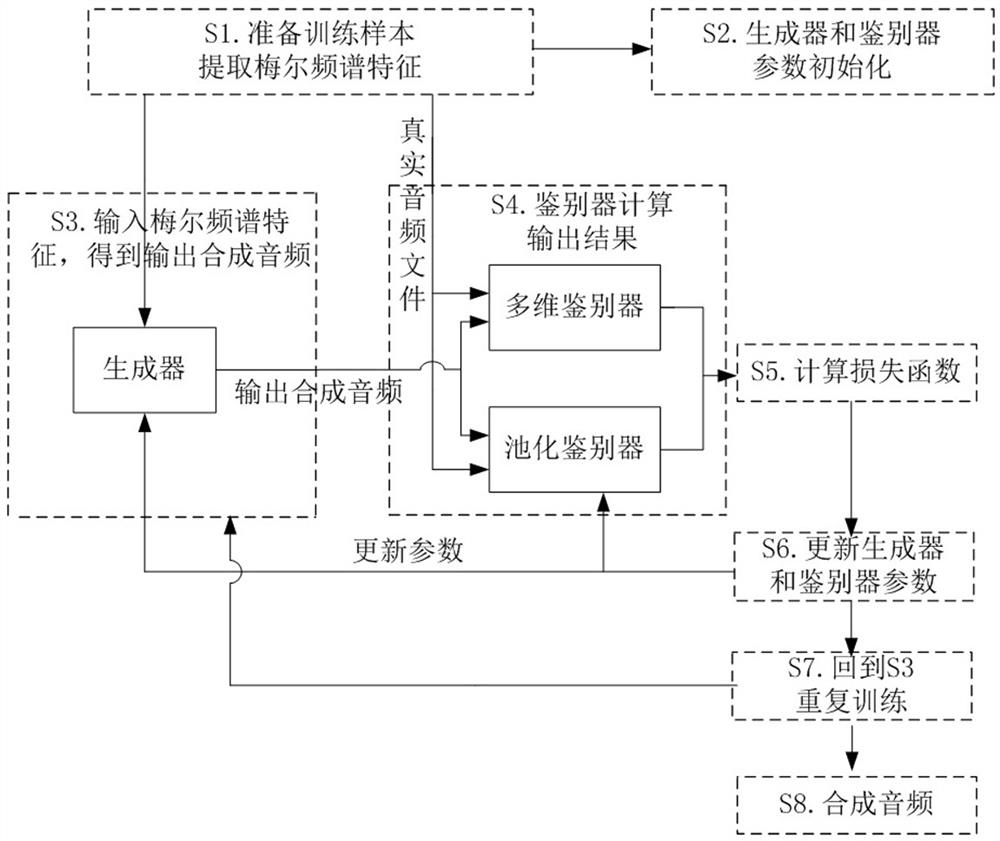
[0048] The present invention is based on a speech synthesis method of a generated counterfeit network, comprising the steps of:
[0049] S1. Prepare the sample, including real audio data, and extract the Mervere spectrum characteristics of true audio data;
[0050]S2. According to the extraction method and sampling rate of Meer spectral characteristics, set the initialized generator parameter group, including setting one-dimensional anti-convolution parameter and one-dimensional consolidation parameter; set the initializable discriminator parameter group, including multidimensioner and Parameters of the Chihua Diatori;
[0051] S3. Enter the Meer Spectrum feature to the generator, by the generator to obtain the corresponding output synthetic audio;
[0052] S4. The output synthesis audio obtained by the real audio data in S1 corresponds to the multidimensional authenticator and poolization discriminator at the same time; w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More