

Network autonomous intelligent management and control method based on deep reinforcement learning
A technology of reinforcement learning and autonomous intelligence, applied in the field of artificial intelligence, can solve problems such as training data correlation overfitting, limited discrete state and action space, and not suitable for SDN network systems, and achieve the effect of network performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

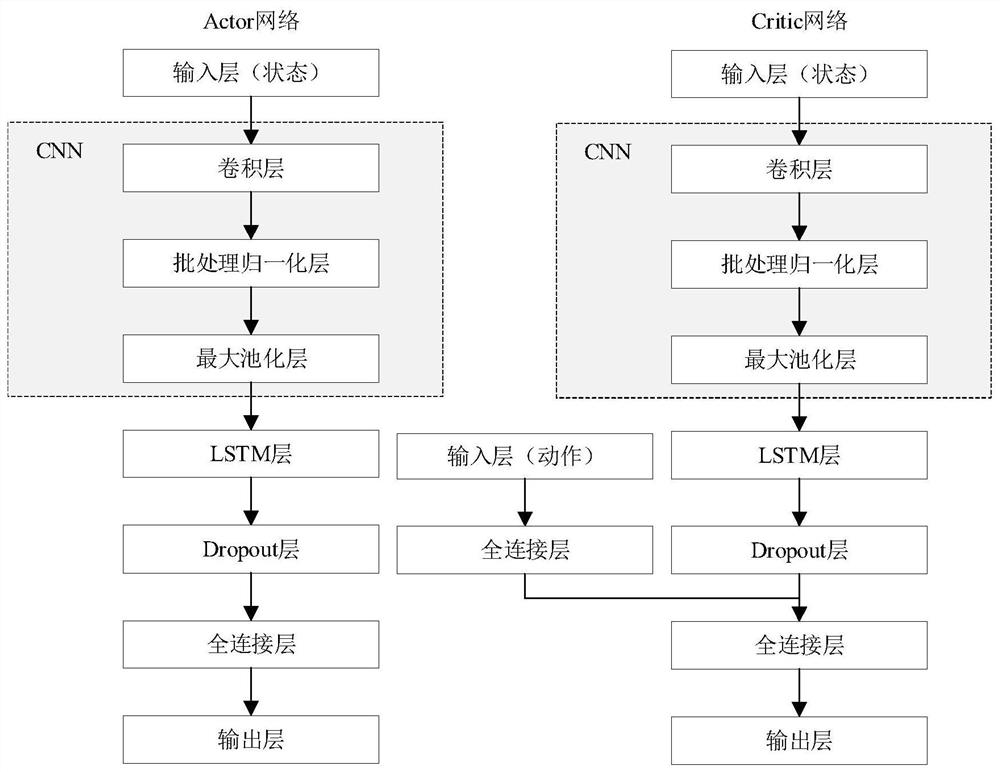
Examples
Embodiment
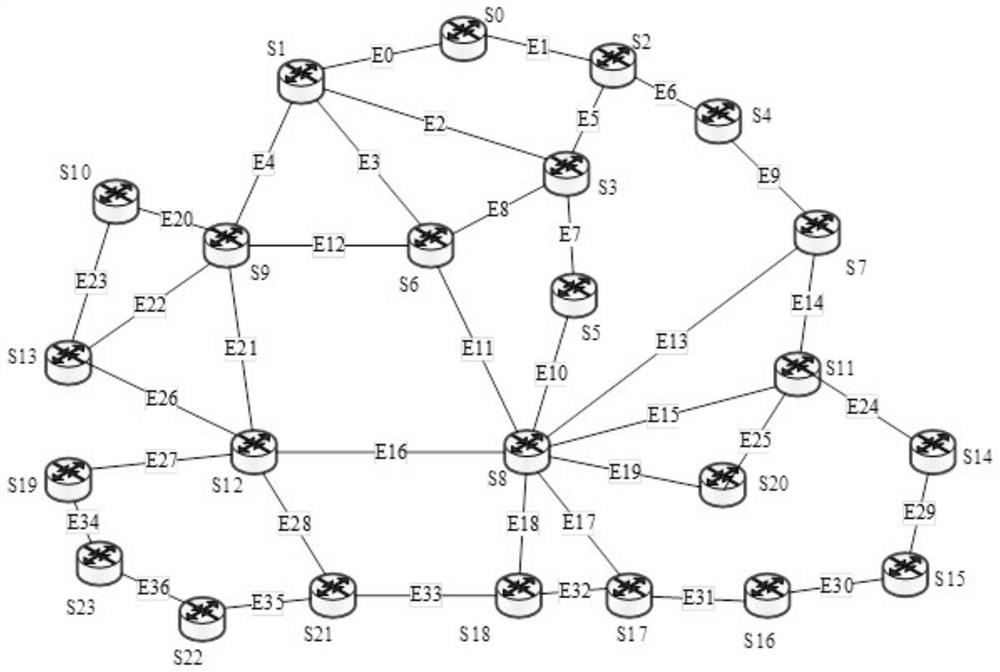
[0047] This embodiment uses ONOS as the network controller. Simulate the SDN network environment through Mininet (a network emulator connected by some virtual terminal nodes, switches, and routers), and use Mininet's topology construction API to generate the following figure 1 Experimental topology shown.
[0048] The topology consists of 24 switch nodes and 37 bidirectional links. Each switch is connected to a terminal host by default, and the number is the same as that of the switch. The four performance parameters of link bandwidth, delay, jitter and packet loss rate are configured through Mininet's TCLink class. The rated bandwidth of each link is set to 10Mbps, the range of link delay is 10-100ms, the range of delay jitter is 0-20ms, and the range of packet loss rate is 0-2%.
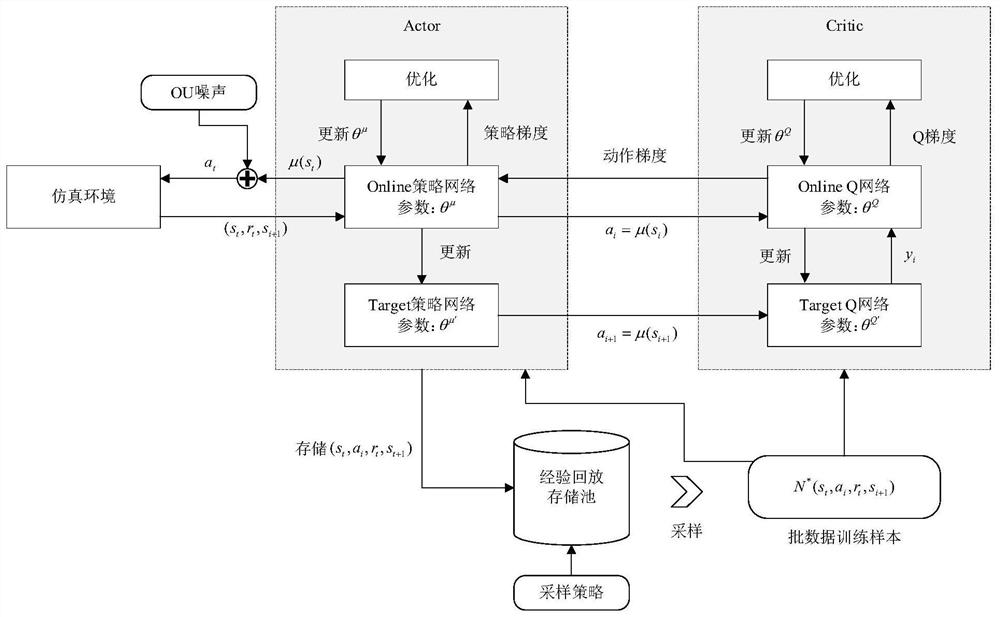
[0049] In this embodiment, the operation process of the DDPG agent is as follows figure 2 As shown, it specifically includes the following steps:
[0050] S1. Initialize the current number of ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More