

Multi-agent system cooperative control method and system based on reinforcement learning algorithm
A multi-agent system and collaborative control technology, applied in the field of control, can solve problems such as low efficiency, complex HJB equations, and difficulty in operating efficiency to meet practical applications, and achieve the effect of high scalability and wide application value.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
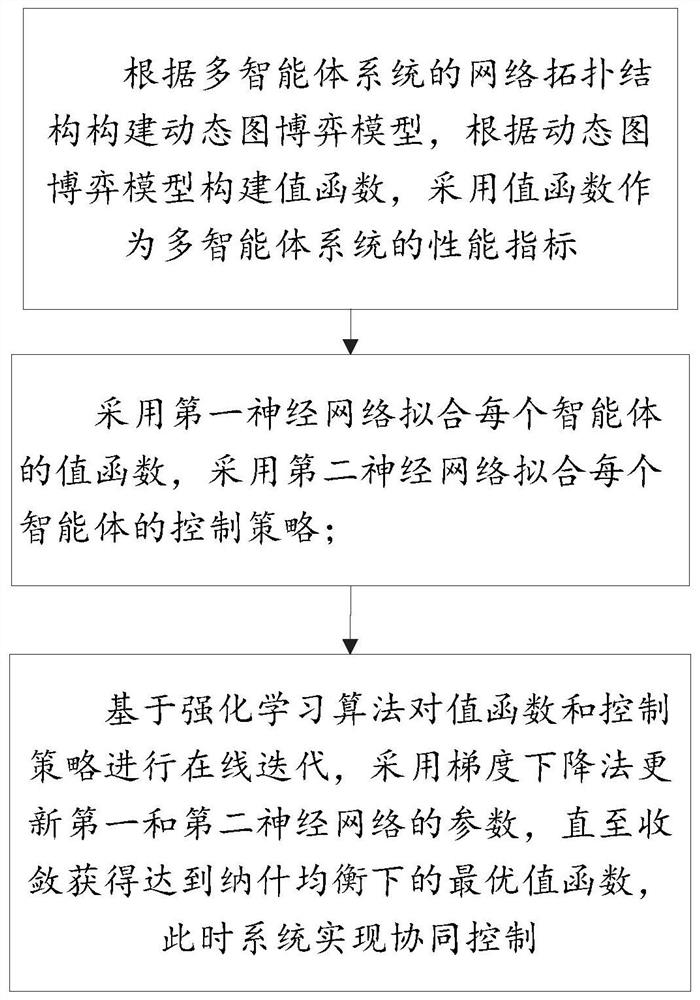
[0027] Such as figure 1 As shown, the multi-agent system cooperative control method based on reinforcement learning algorithm includes:
[0028] Construct a dynamic graph game model according to the network topology of the multi-agent system, construct a value function according to the dynamic graph game model, and use the value function as the performance index of the multi-agent system;
[0029] The first neural network is used to fit the value function of each agent, and the second neural network is used to fit the control strategy of each agent;
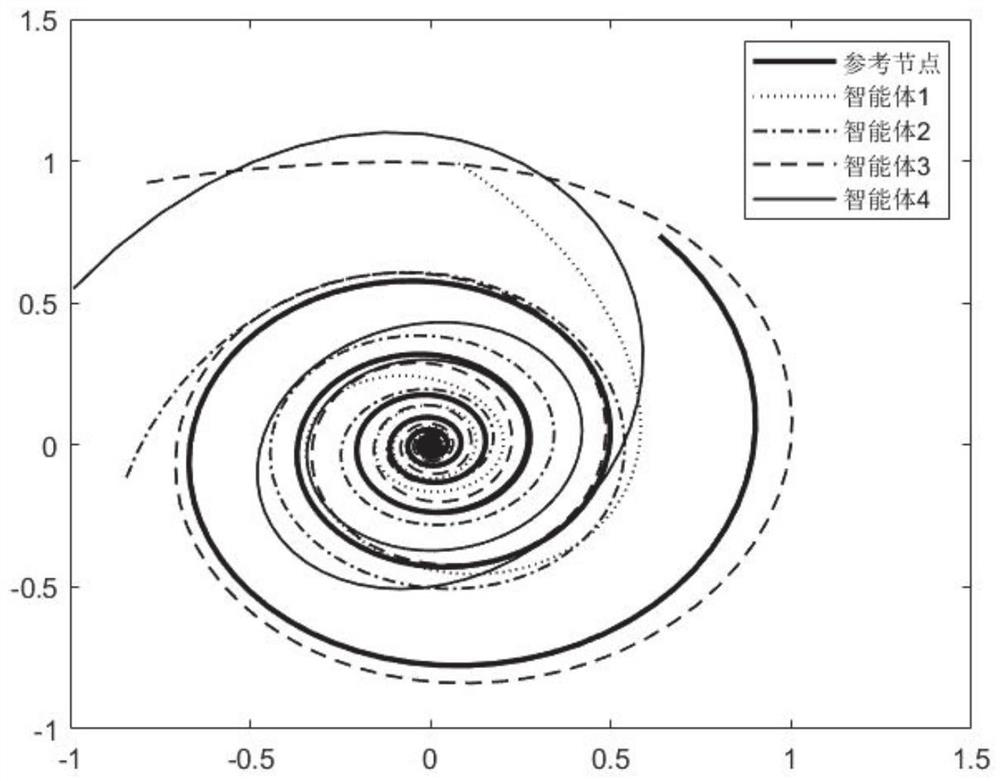
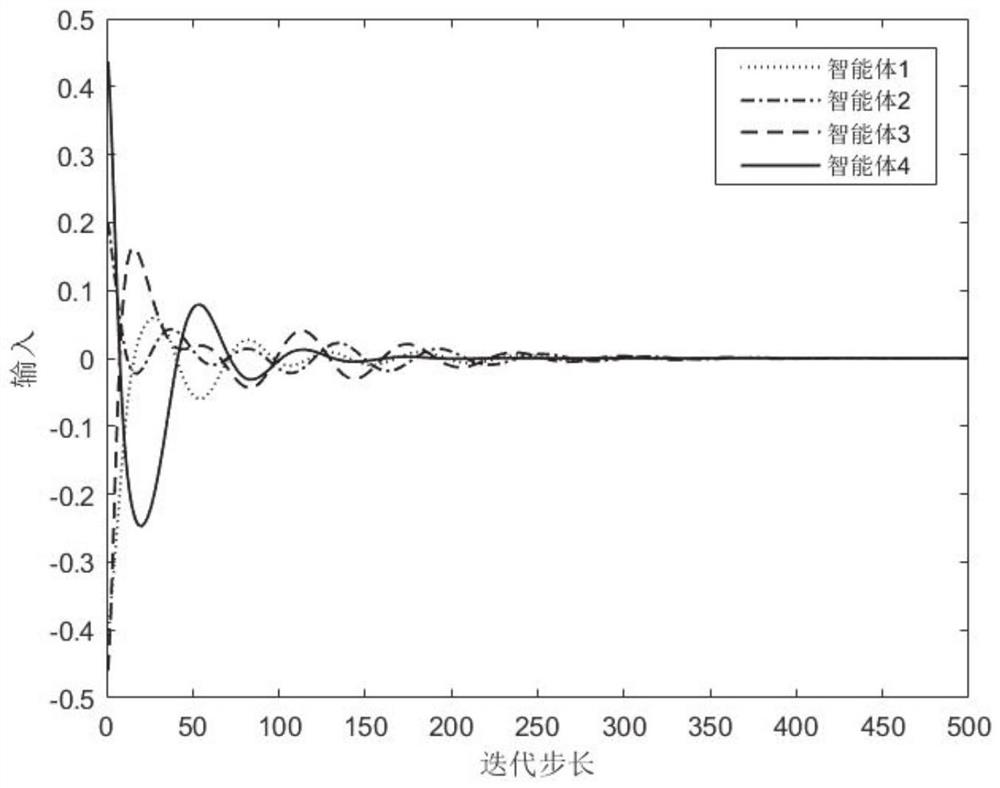
[0030] Based on the reinforcement learning algorithm, the value function and the control strategy are iterated online, and the parameters of the first and second neural networks are updated using the gradient descent method until the convergence reaches the optimal value function under Nash equilibrium. At this time, the multi-agent system realizes collaboration control.
[0031] In the process of algorithm iteration, it needs ...
Embodiment 2
[0096] This embodiment also provides a multi-agent system cooperative control system based on a reinforcement learning algorithm, including:
[0097] The multi-agent system building block is used to establish a multi-agent system, construct a dynamic graph game model according to the network topology of the multi-agent system, construct a value function according to the dynamic graph game model, and use the value function as the performance index of the multi-agent system ;
[0098] The neural network building block is used to adopt the first neural network to fit the value function of each agent, and adopt the second neural network to fit the control strategy of each agent;
[0099] The data processing module is used for performing online iteration on the value function and the control strategy based on the reinforcement learning algorithm, and adopts the gradient descent method to update the parameters of the first and second neural networks until the optimal approximation v...
Embodiment 3
[0103] A computer-readable storage medium is used to store computer instructions. When the computer instructions are executed by a processor, the multi-agent system cooperative control method based on the reinforcement learning algorithm as described in the above embodiments is completed.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More