

Automatic fine-grained two-stage parallel translation method
A fine-grained and automatic technology, applied in the computer field, can solve the problem of low computing efficiency, and achieve the effect of improving computing efficiency, simple logic branching, and high computing density
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
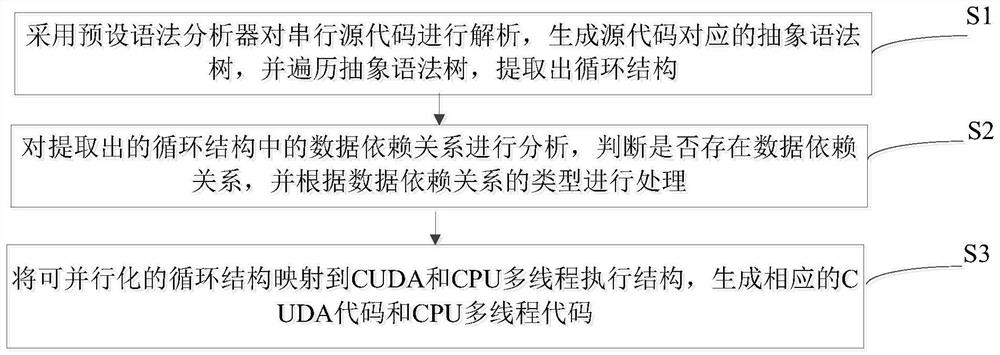
[0033] The invention relates to an automatic fine-grained two-level parallel translation method for large data task processing. Firstly, the source C code is parsed by ANTLR to automatically generate an EBNF grammar description. According to the description of EBNF, ANTLR generates corresponding lexical and syntactic analyzers for the abstract syntax tree. The loop information extracted from the parser is analyzed, and if flow dependencies are found, the loop statements containing these dependencies are not parallelizable and flagged. If anti-dependencies and output dependencies between data are found, the loop structure is processed to eliminate dependencies. Such a loop statement is parallelizable if there are no data dependencies. After eliminating the anti-dependence and output dependencies caused by variable reuse, the array privatization technique is used to localize the storage unit related to the loop iteration, so that it can be separated from the interaction of the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More