

Implementation method and device for submitting flink job to yarn cluster in application program
A technology of application programs and implementation methods, applied in the field of big data computing, can solve the problems of space occupied by public resources, achieve the effects of reducing dependence, avoiding mutual interference, and improving deployment flexibility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
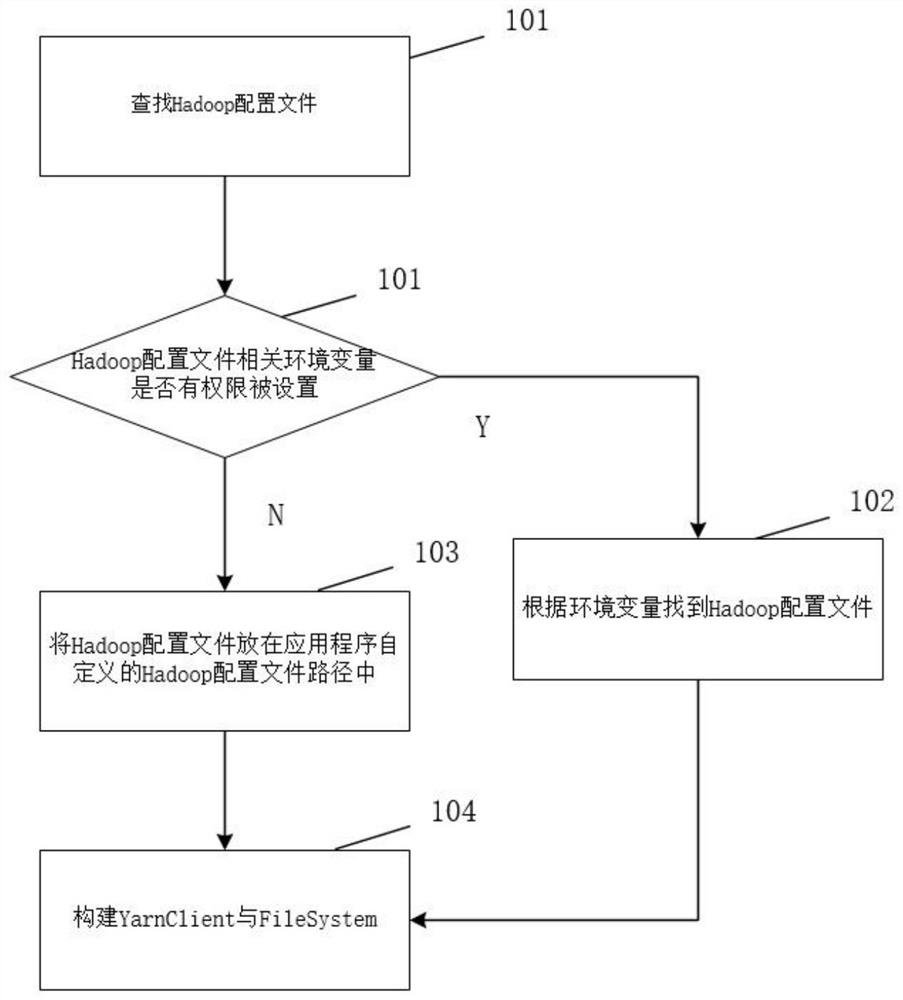
[0036] Embodiment 1 of the present invention provides an implementation method for submitting a flink job to a yarn cluster in an application program.
[0037] Flink runs on yarn. It needs to connect to the HDFS file system and the ResourceManager of yarn. It must be able to find the Hadoop configuration file. When the user does not have permission to set the environment variable to find the Hadoop configuration file, the application customizes a Hadoop configuration file path. The Hadoop configuration file is stored in the Hadoop configuration file path, and a resident YarnClient is constructed through the Hadoop configuration file, and the flink cluster interacts with the yarn cluster through the YarnClient;
[0038] The Hadoop configuration file path is the application program working directory, or other paths that can be found are defined by the application program working directory, and the Hadoop configuration file is stored in the path, and the path is designed according...
Embodiment 2
[0199] Embodiment 2 of the present invention provides an implementation method for submitting flink jobs to a yarn cluster in an application program. Compared with embodiment 1, this embodiment 2 presents a more realistic scenario in this solution to solve the Hadoop deployment of flink on yarn. Implementation process for deployment issues of configuration files.
[0200] When flink is running on yarn, it is necessary to construct a YarnClient object to access yarn's ResourceManager, and also to construct a FileSystem object to access HDFS. It is necessary to find the Hadoop configuration file to construct a YarnClient object and a FileSystem object;
[0201] The flink native code checks whether the YARN_CONF_DIR, HADOOP_CONF_DIR, HADOOP_CONF_PATH and other environment variables are in turn; if the YARN_CONF_DIR, HADOOP_CONF_DIR, HADOOP_CONF_PATH and other environment variables are not set, then check the HADOOP_HOME environment variable. For hadoop 2.x, the configuration...
Embodiment 3
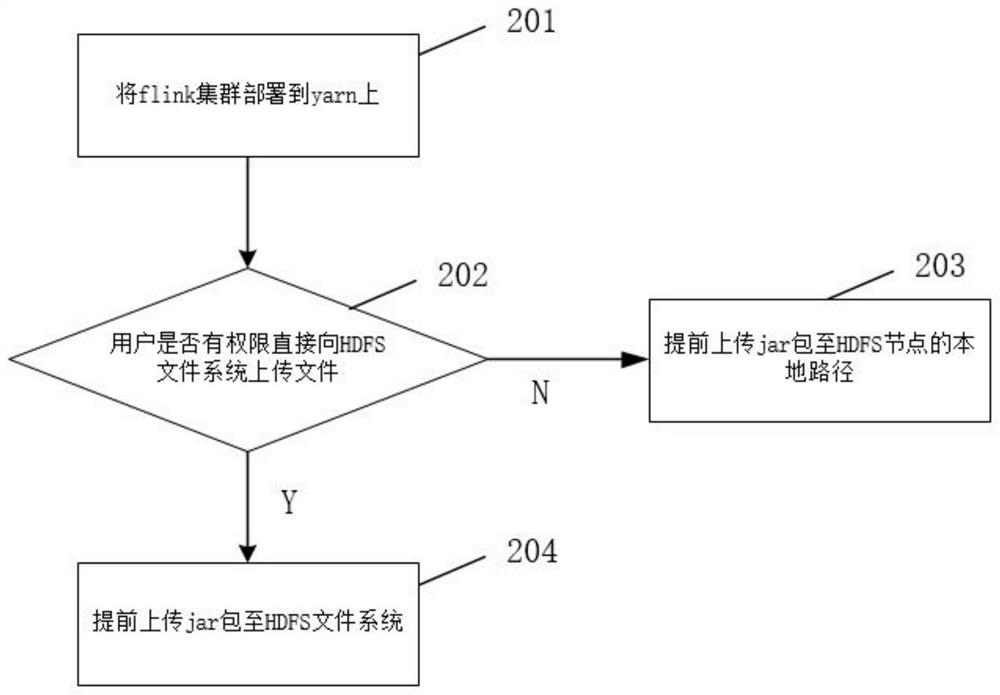
[0237] Embodiment 3 of the present invention provides an implementation method for submitting flink jobs to yarn clusters in an application program. Compared with Embodiment 1, Embodiment 3 presents a more realistic scenario in this solution to solve the problem that jar packages are uploaded to HDFS and occupy a large amount. The implementation process of network IO problems.
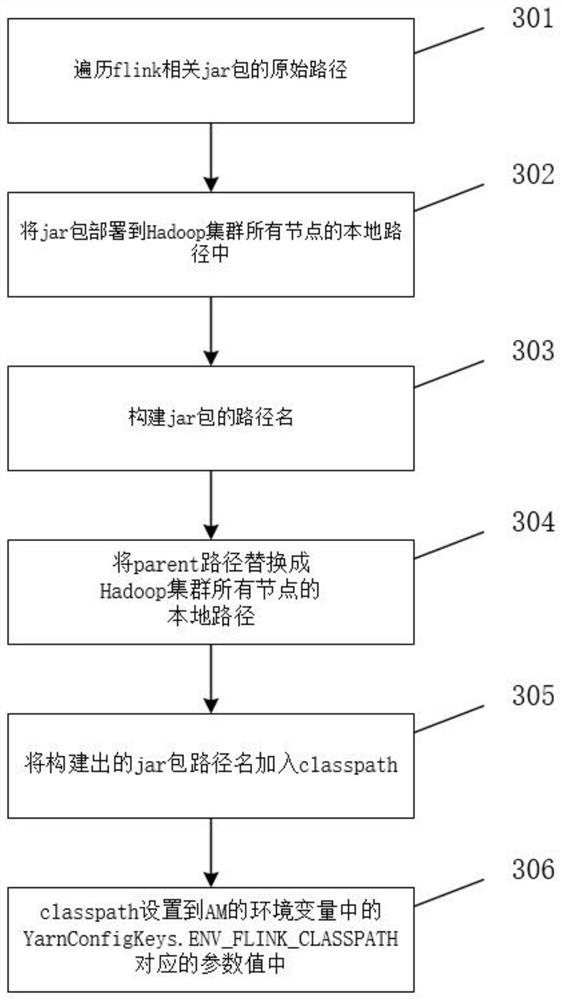
[0238] When it is necessary to submit a job from flink to run on yarn, first check whether the user has permission to directly upload files to the HDFS system file. In this embodiment, the user does not have permission to directly upload files to the HDFS system file, so first traverse the flink system jar package and the first The original path of the three-party dependent jar package was found to exist in the D drive 110 folder. The user manually uploaded the flink system jar package and the third-party dependent jar package from the D drive 110 folder to the path with the same name as the full pa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More