

Image-text cross-modal retrieval method based on joint features
A joint feature, cross-modal technology, applied in the field of image processing, to ensure that the overall semantics is not missing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0052] The present invention will be further described below with reference to the accompanying drawings and embodiments.
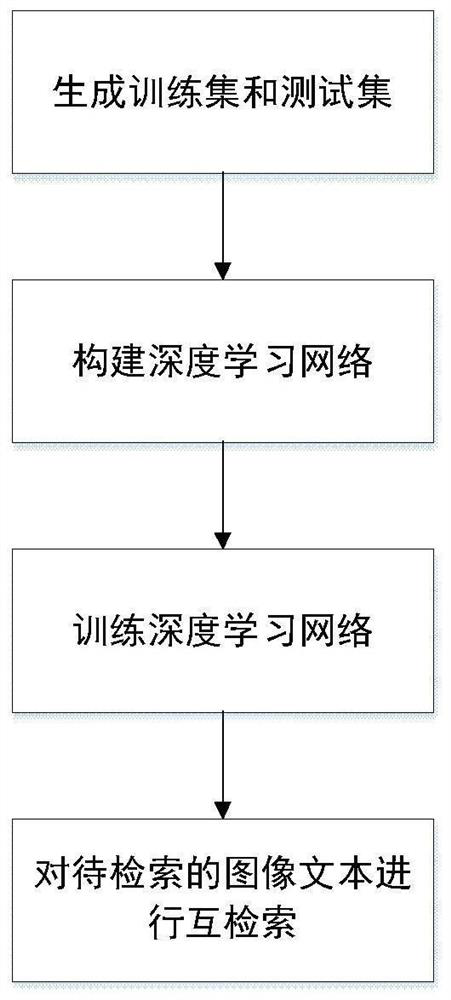
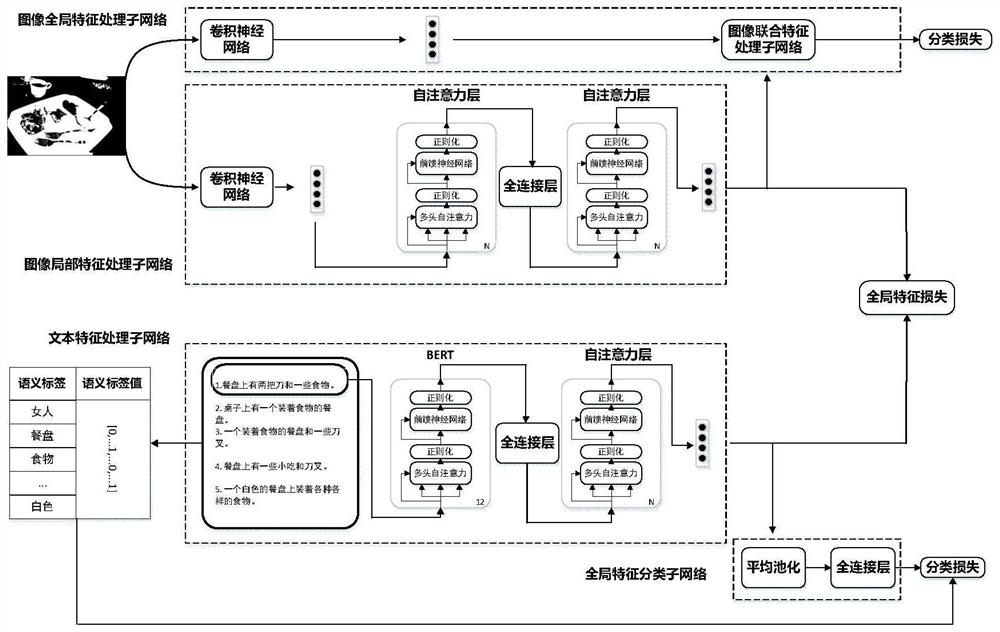
[0053] refer to figure 1 The implementation steps of the present invention are further described with the examples.
[0054] Step 1, generate training set and test set.
[0055] Step 1.1, select at least 10,000 natural images and their corresponding texts depicting the image content, each image has at least 5 sentences of text describing the image content, and the text can be in English or Chinese.
[0056] Step 1.2, traverse all the texts in the sample set, find out the nouns in each text, sort the number of occurrences of text nouns in the sample set from high to low, and select the 500 nouns with the highest number of occurrences to form a noun set. For each text in the sample set, define a semantic label. When the label is 1, it means that the text contains nouns in the noun set, and when the label value is 0, it means that the text does not contain...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More