

Integrated data source finding method for deep layer net page data source
A technology of web page data and discovery method, which is applied in the data source discovery of deep web pages and the integration of deep web data sources, can solve the problems of inability to obtain in-depth information, subject drift, and inability to control the crawling process well, so as to improve the Discover efficiency, prevent theme drift, and avoid the effect of theme drift
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
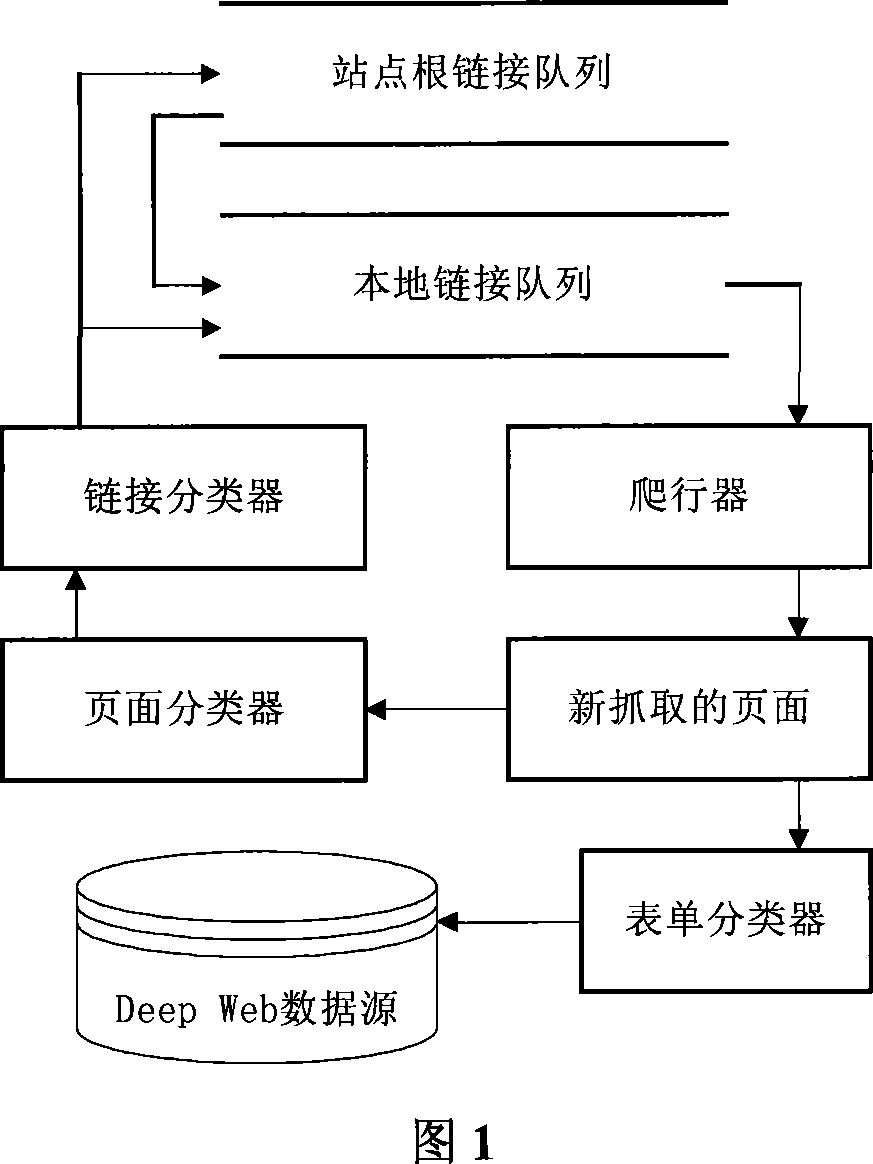
[0031] Embodiment 1: Referring to Figure 1 to Figure 2, a data source discovery method for deep webpage data source integration includes the following steps:
[0032] (1) Provide the topic of the data to be queried, construct the site root link queue and the local link queue respectively, put at least one seed root link address in the site root link queue, and give a weight according to its relationship with the topic;
[0033] (2) If the local link queue is empty, take the root link address with the largest weight from the site root link queue and put it into the local link queue; take the highest-scoring page link from the local link queue, and download it by the crawling module page;
[0034] (3) Use the form classifier to process the page downloaded in step (2). If it contains a form query interface, add it to the deep web page data source;
[0035] (4) Use the page classifier to process the page downloaded in step (2). The page classifier adopts the best-first strategy for sub...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More