

Massive high-dimension data clustering method for MapReduce platform
A technology of high-dimensional data and clustering method, applied in electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as poor performance and insufficient memory, and achieve good customizability, high scalability and Customizability, the effect of reducing data size
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

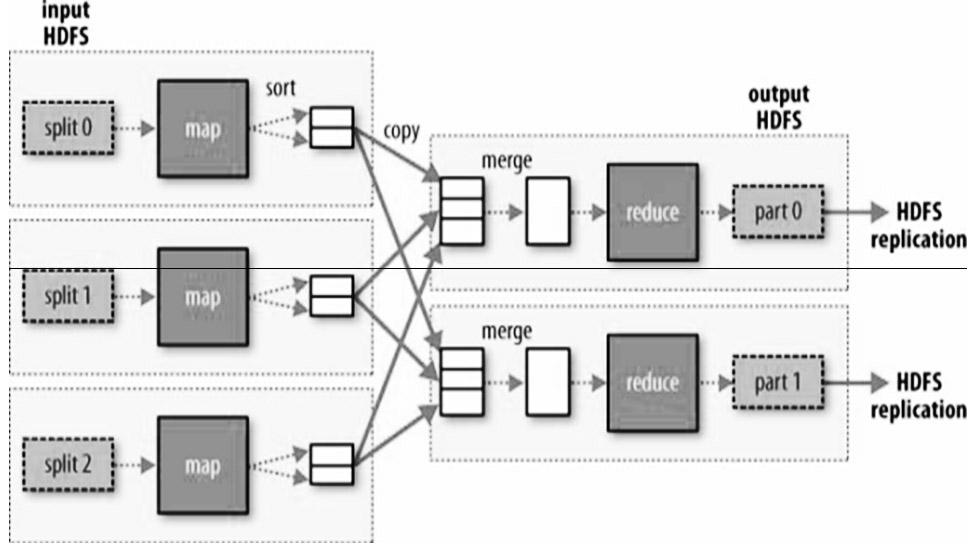
Examples
specific Embodiment approach
[0048] The input data is 2000 music feature files, which are extracted from 2000 Chinese songs. Each song is divided into about 5000 frames, each frame has 26 attributes, represented by floating point numbers, and all frames are required to be clustered into 1500 classes. We regard this about 10 million frames as a set of points, and the 26 attributes of each point are used as 26-dimensional coordinates, and the clustering is performed according to the following steps:
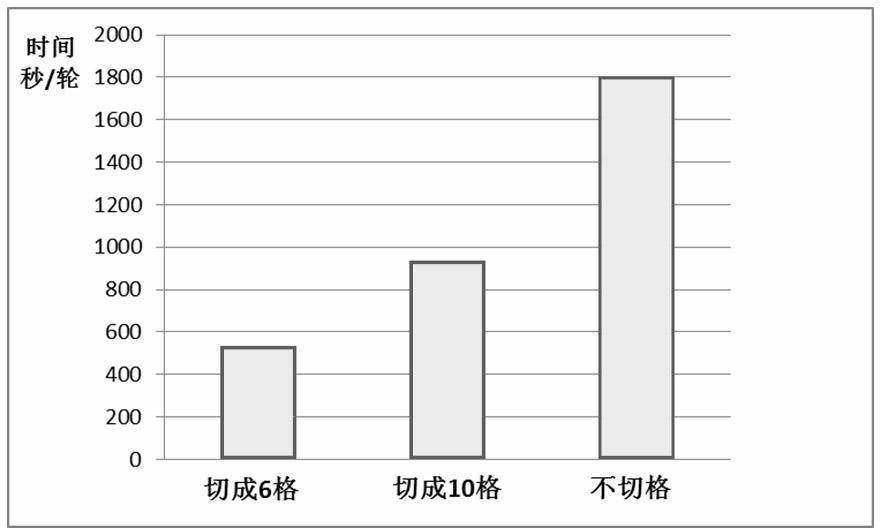
[0049] (1) First cut each dimension into 10 grids (N=10), get all non-empty 26-dimensional grids, and remove the duplicates. Since N=10, the coordinate value of each dimension is an integer in the range [0,9].
[0050] (2) Randomly select 1500 grids from all the 26-dimensional grids output in step (1) as the initial center points.
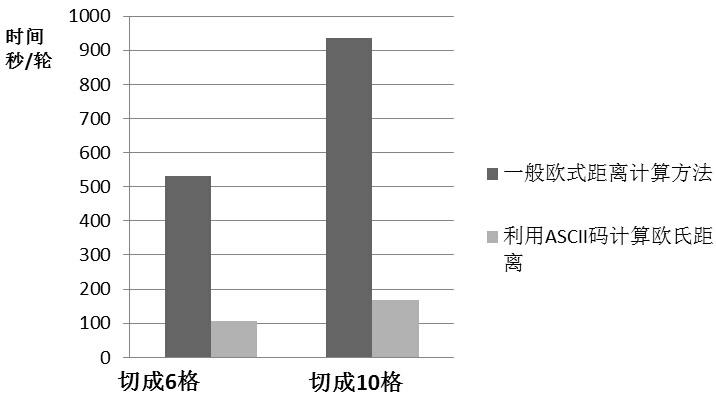
[0051] (3) Cluster all 26-dimensional grids output from step (1) on the MapReduce distributed platform. When calculating the distance, use the ASCII codes of 0, 2, 4...50 in the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More