

Malicious file identification method, device and storage medium
A malicious file and identification method technology, applied in the Internet field, can solve problems such as low efficiency, virus harm, and time-consuming extraction of virus features, and achieve the effect of improving detection efficiency, accurate and effective extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
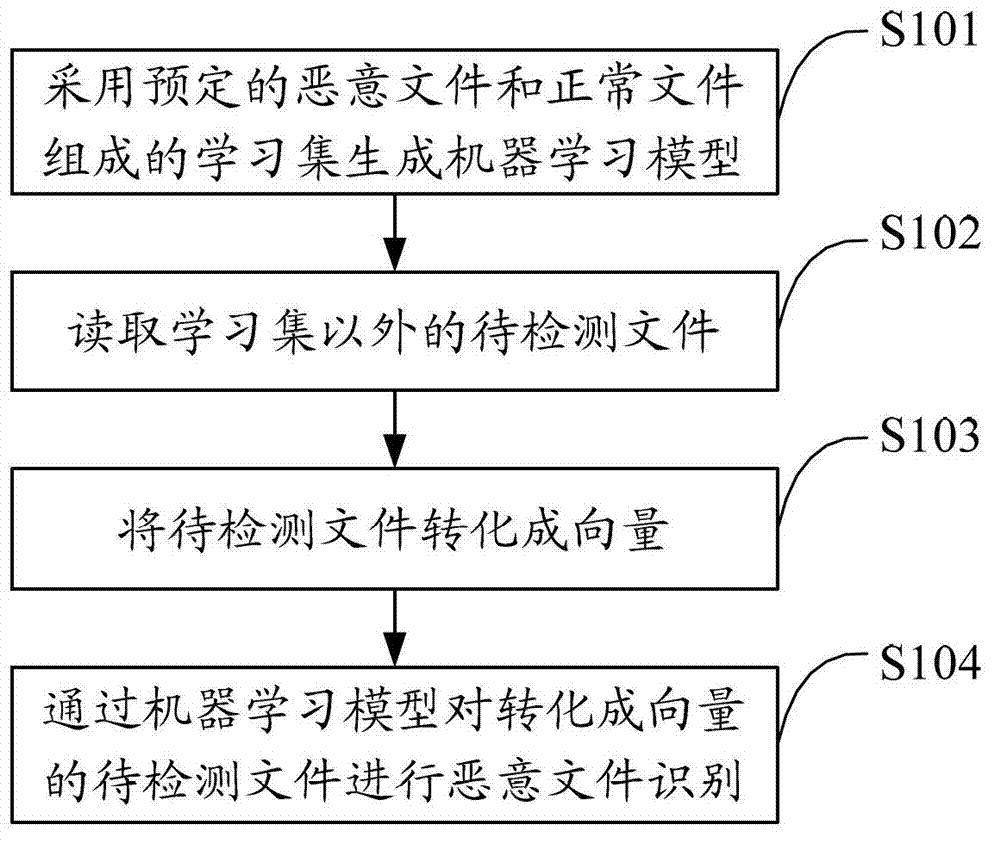
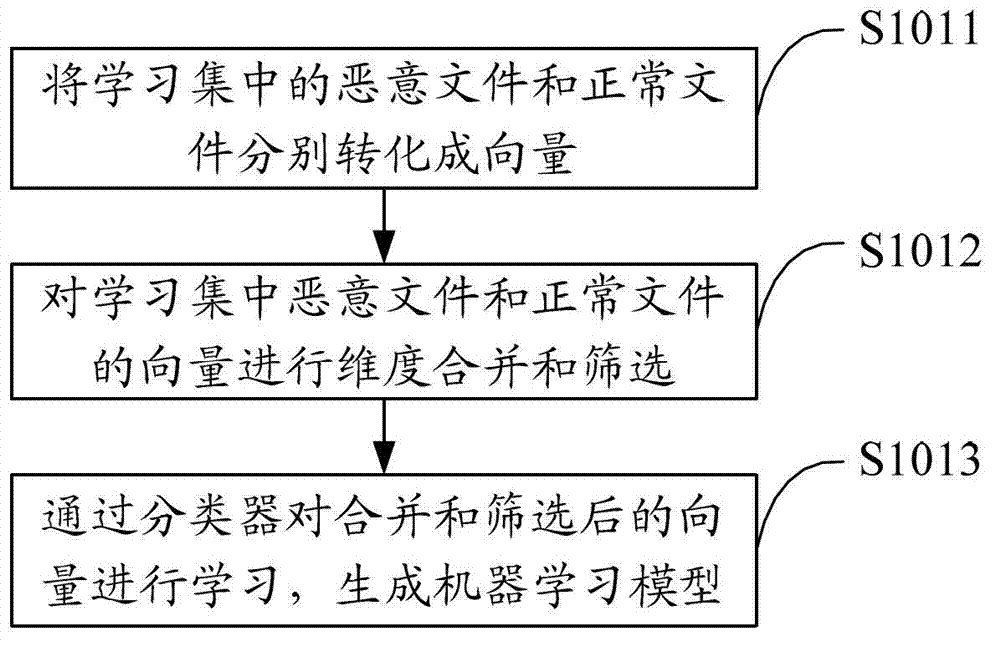
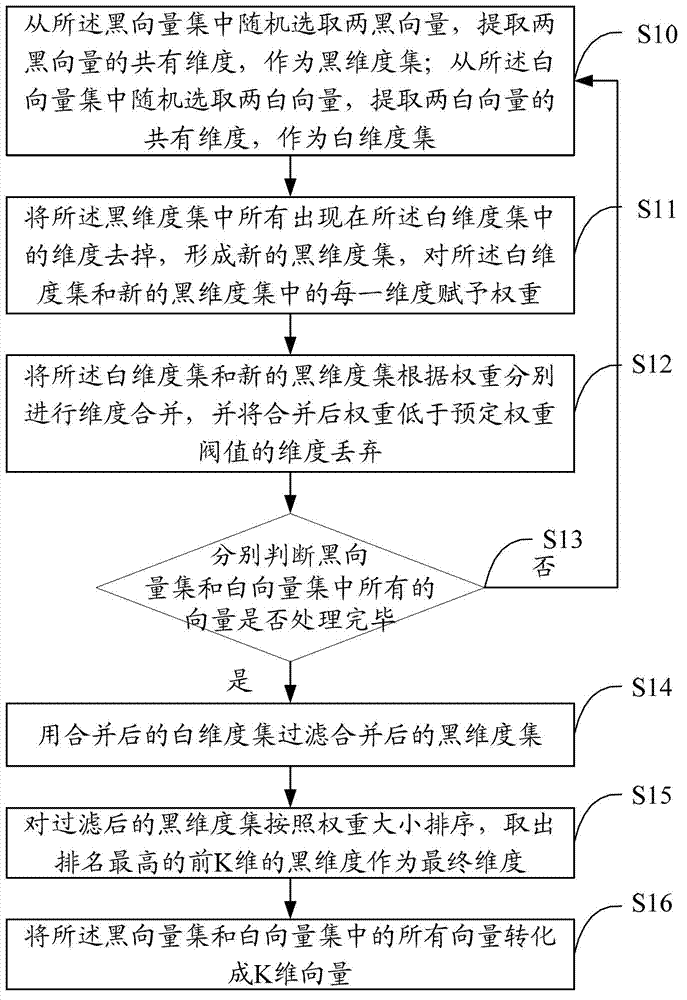
[0031] The solution of the embodiment of the present invention is mainly: using a learning set composed of predetermined malicious files and normal files to generate a machine learning model; reading the files to be detected other than the learning set, and converting the files to be detected into vectors, and using The model identifies malicious files on the files to be detected that are converted into vectors, and uses machine learning to respond in a timely manner and process quickly to improve the detection efficiency of malicious files.
[0032] Malicious files in the present invention may be virus files or other malicious files, and the following embodiments use malicious files as examples for illustration. Among them, the technical terms involved include:
[0033] Black Files: Virus Files
[0034] Black vectors: vectors converted from virus files
[0035] White files: normal non-virus files
[0036] White vector: the vector converted from a normal non-virus file
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More