

Method for identifying taxicabs in real time by utilizing video images
A recognition method and video image technology, applied in character and pattern recognition, road vehicle traffic control system, instrument, etc., can solve problems such as difficult to predict traffic flow interference and chaotic and complex external environment, difficult to control and predict, etc. Achieve high judgment accuracy and robustness, increase effectiveness, and improve judgment accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

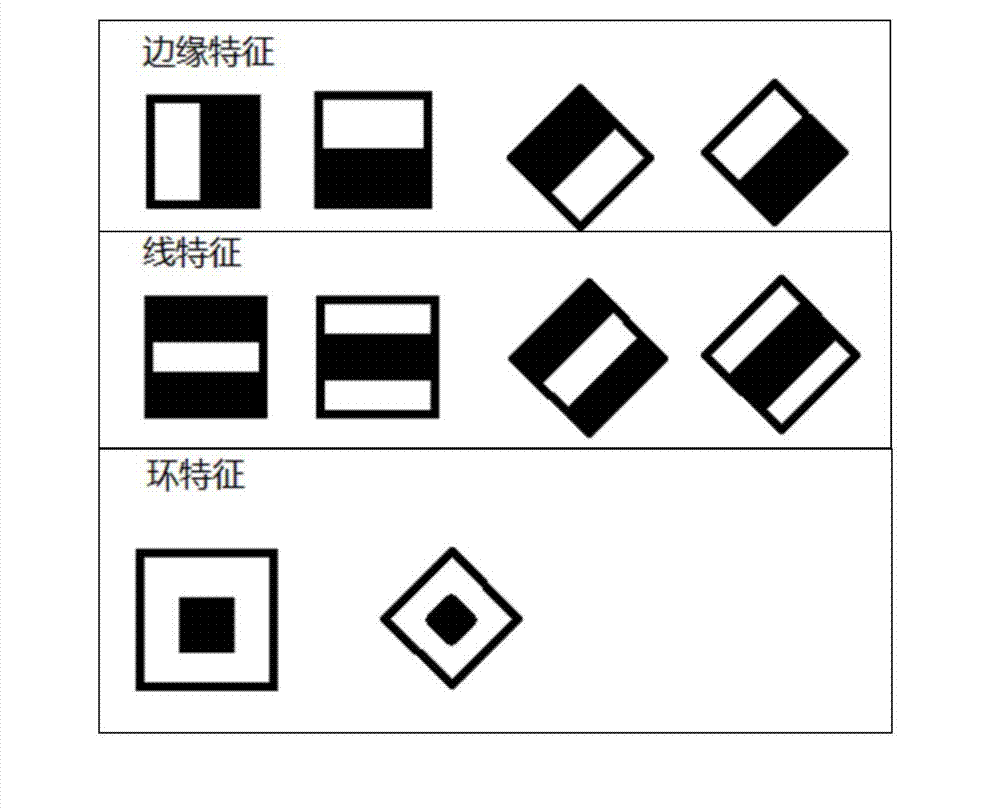
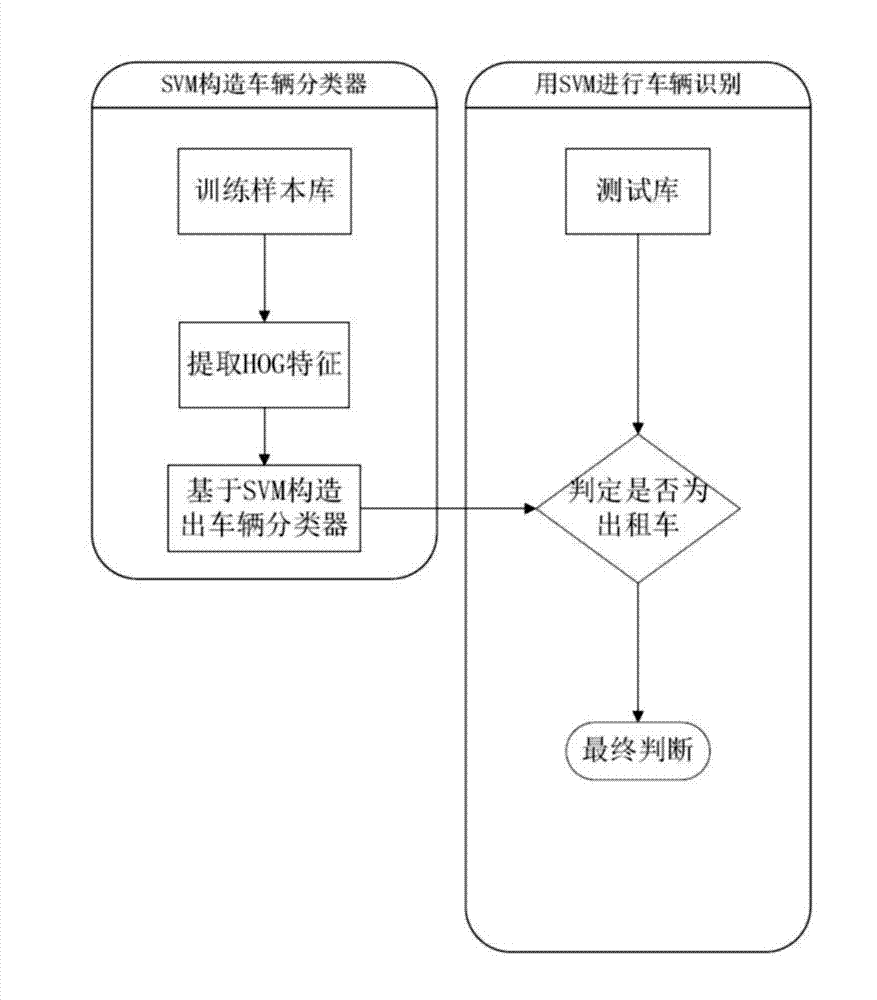
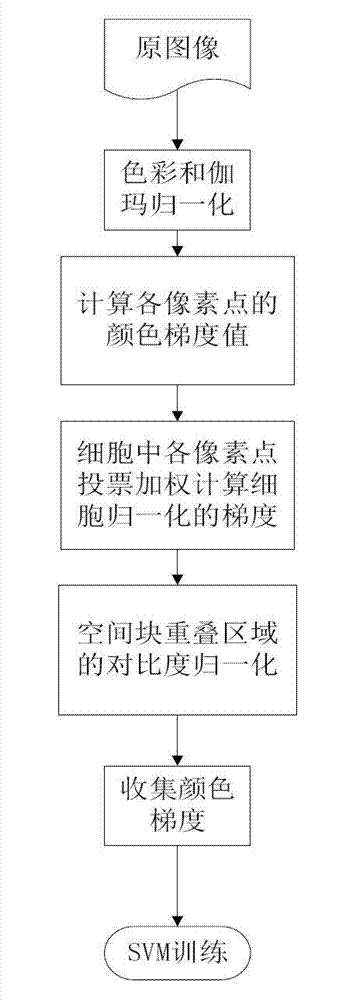
Examples
Embodiment Construction
[0040] Below in conjunction with accompanying drawing, the present invention is described in further detail, so that those skilled in the art understand:
[0041] Compared with other motor vehicles, taxis have the following salient features:
[0042] Features 1. Dome light. The dome light of a taxi is an obvious sign that distinguishes it from other vehicles. Significant changes have been made to the profile character of the body.
[0043] Features 2. Models. Taxi is a small car model, which is obviously different from medium and large vehicles in terms of outline.
[0044]Features three, color. In order to reflect the significant difference between taxis and private cars and facilitate citizens to distinguish them, each region often has clear restrictions on the color of taxi bodies, so there is a significant difference in color between taxis and private cars.
[0045] For example, in Beijing, taxis are two-color cars, and the ancient five-element culture of our country ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More