

Lip reading technology based lip language input method
An input method and lip language technology, applied in the input/output of user/computer interaction, graphic reading, instruments, etc., to achieve the effect of strong practicability and recognition accuracy, strong pertinence, improved accuracy and rapidity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

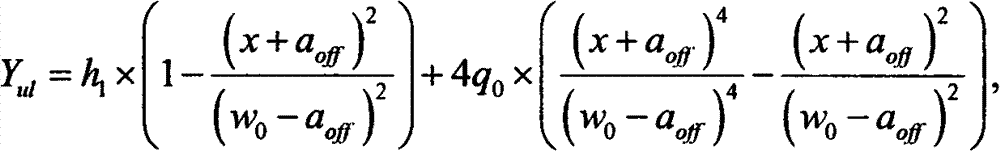
Examples
Embodiment Construction
[0025] The following will introduce the lip language input system based on lip reading technology and its implementation method:
[0026] First, the system camera is used to locate the lips of the person, and the lip movement video containing only the speaker's lips is collected, and the key frame image in the video stream is obtained by using the key frame extraction technology.
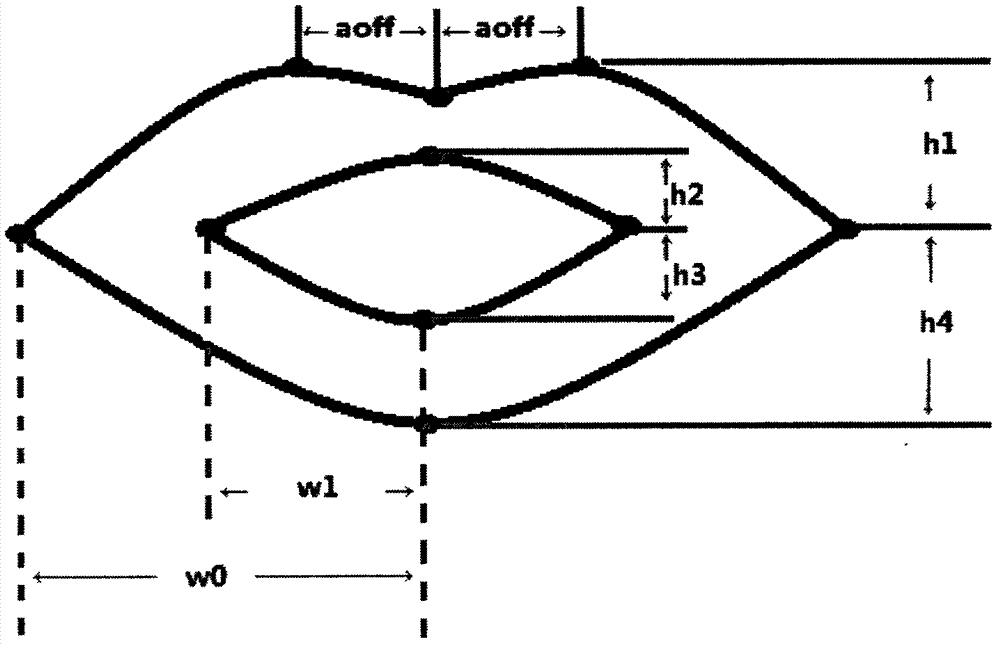
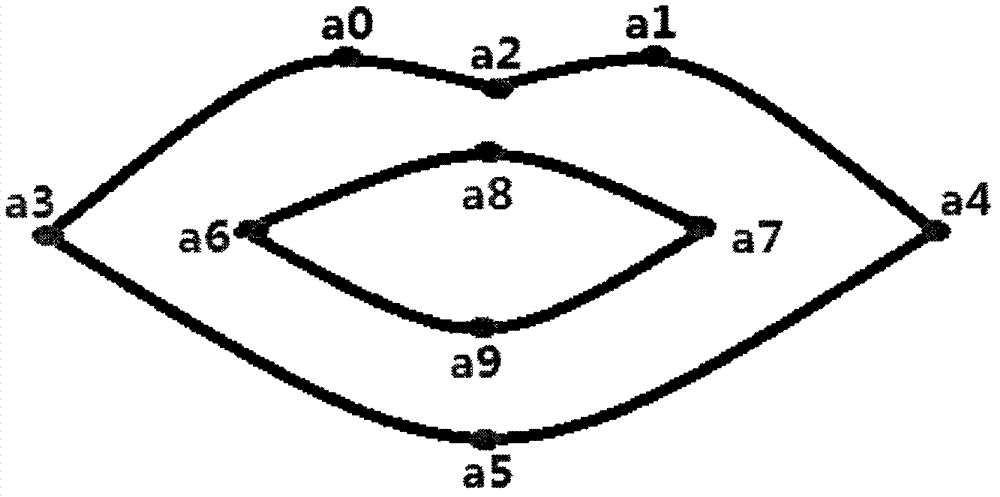
[0027] For the obtained normalized lip color static picture, the OpenCV library function is used to grayscale and median filter the picture, and then the Otsu method (Otsu method) is used to calculate the binarization threshold of the picture. Use this threshold to binarize the smoothed grayscale image. In this way, the effect of adaptive acquisition threshold is achieved. For the binarized image, scan each pixel in the image to determine whether it is an isolated point. The isolated points are removed during the scanning process, thus having a good denoising effect on the binarized image. The pi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More