

Rapid data de-duplication method adapted to big data application
A technology for deduplication and big data, which is applied in special data processing applications, redundancy in operations, data error detection, response error generation, etc. It can solve the problem of low deduplication rate and inability to effectively adapt to complex Changeable application environment, unsuitable big data application environment and other problems, to achieve the effect of reducing the backup window and storage overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0037] The method of the present invention will be described in detail below with reference to the accompanying drawings.
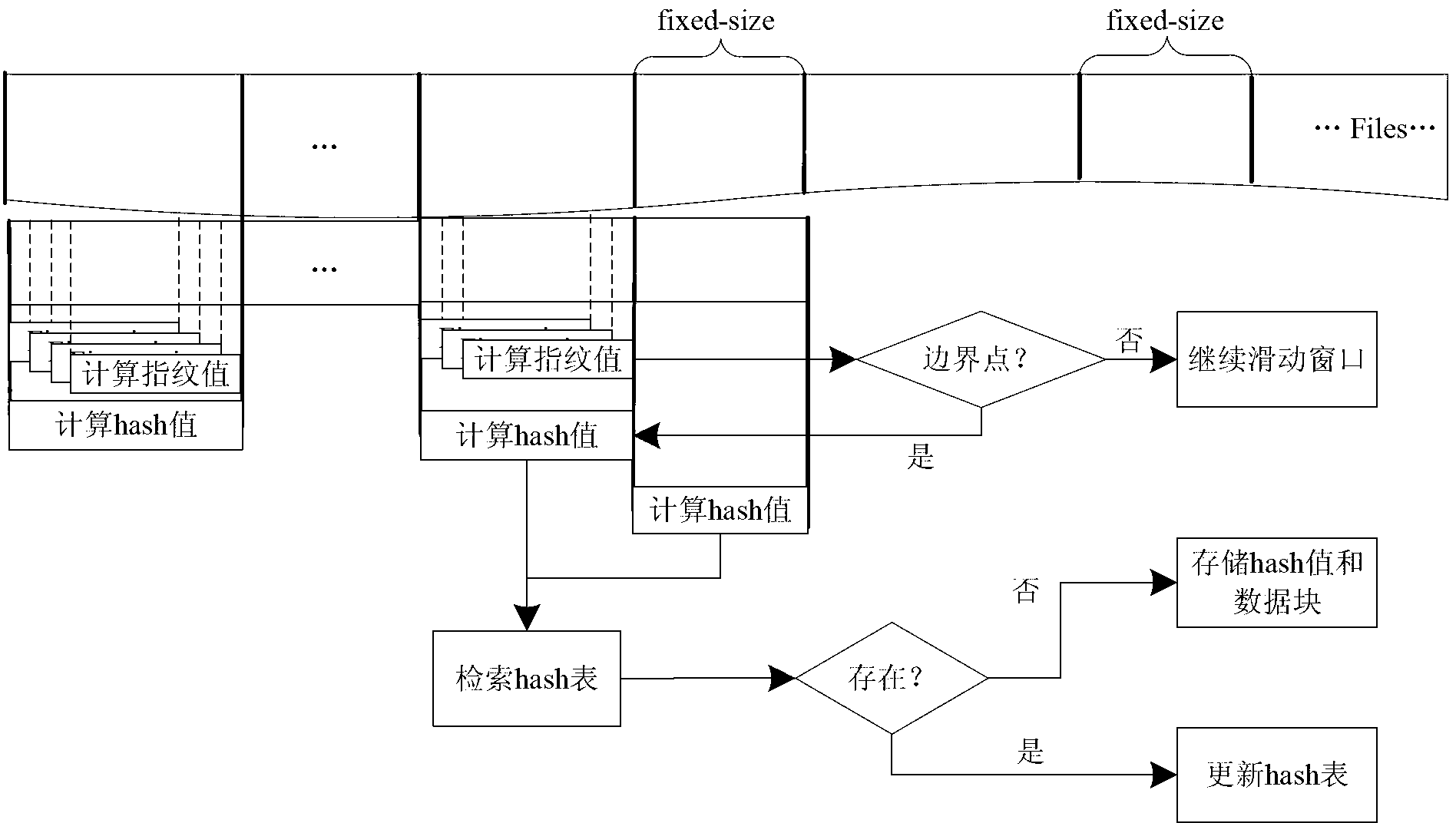
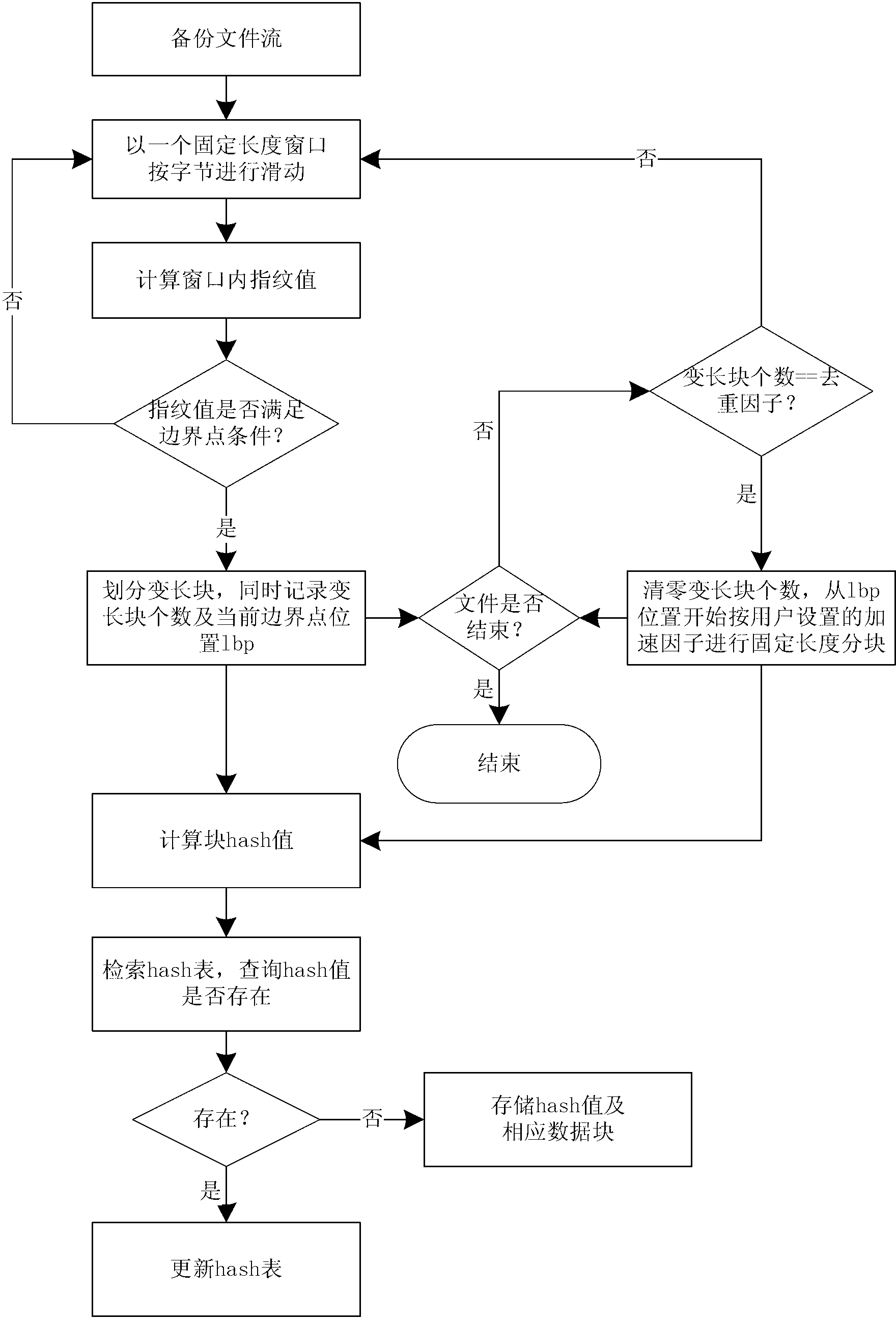
[0038] see Figure 1 to Figure 2 As shown, the present invention is to deduplicate the redundant data existing in the backup process. Considering the impact of the existing deduplication method on the backup window under the big data application and the problem of limited scope of application, the combination becomes block and fixed The advantage of the length block algorithm is to use the deduplication factor and the acceleration factor to ensure the deduplication rate and greatly improve the deduplication rate. The specific ideas of the method of the present invention are as follows: figure 1 shown.
[0039]Data deduplication is suitable for application environments with a large amount of redundant data, such as backup systems, E-mail systems, data migration, and disaster recovery. In these application environments, a high deduplication rate can be ach...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More