

Parallel indexing method supporting real-time biased query of high dimensional data
A high-dimensional data and indexing technology, applied in the search field, can solve problems such as unsatisfactory real-time performance and scalability, and achieve good real-time performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific example
[0027] The specific example is as follows: a hash function maps a d-dimensional vector v to a set of int values. The way each hash function in this group is indexed is determined by a, b, where a is a d-dimensional vector, which satisfies the "stable (stable) distribution" in the existing LSH algorithm, and b is in In the existing LSH algorithm, it is a real number evenly distributed in the interval [0, r]. The specific embodiment of the present invention modifies b to generate uniform distribution according to the density of data, such as normal distribution can be adopted according to the characteristics of data, so that the length of each section is different, but after a and b are given, a special based on The position-sensitive hash of "stable distribution" can be generated by (a.v+b) / r. Since the value of b is distributed according to density rather than constant, the data can be distributed as evenly as possible in each data Buckets, so as to avoid the problem of uncer...
Embodiment
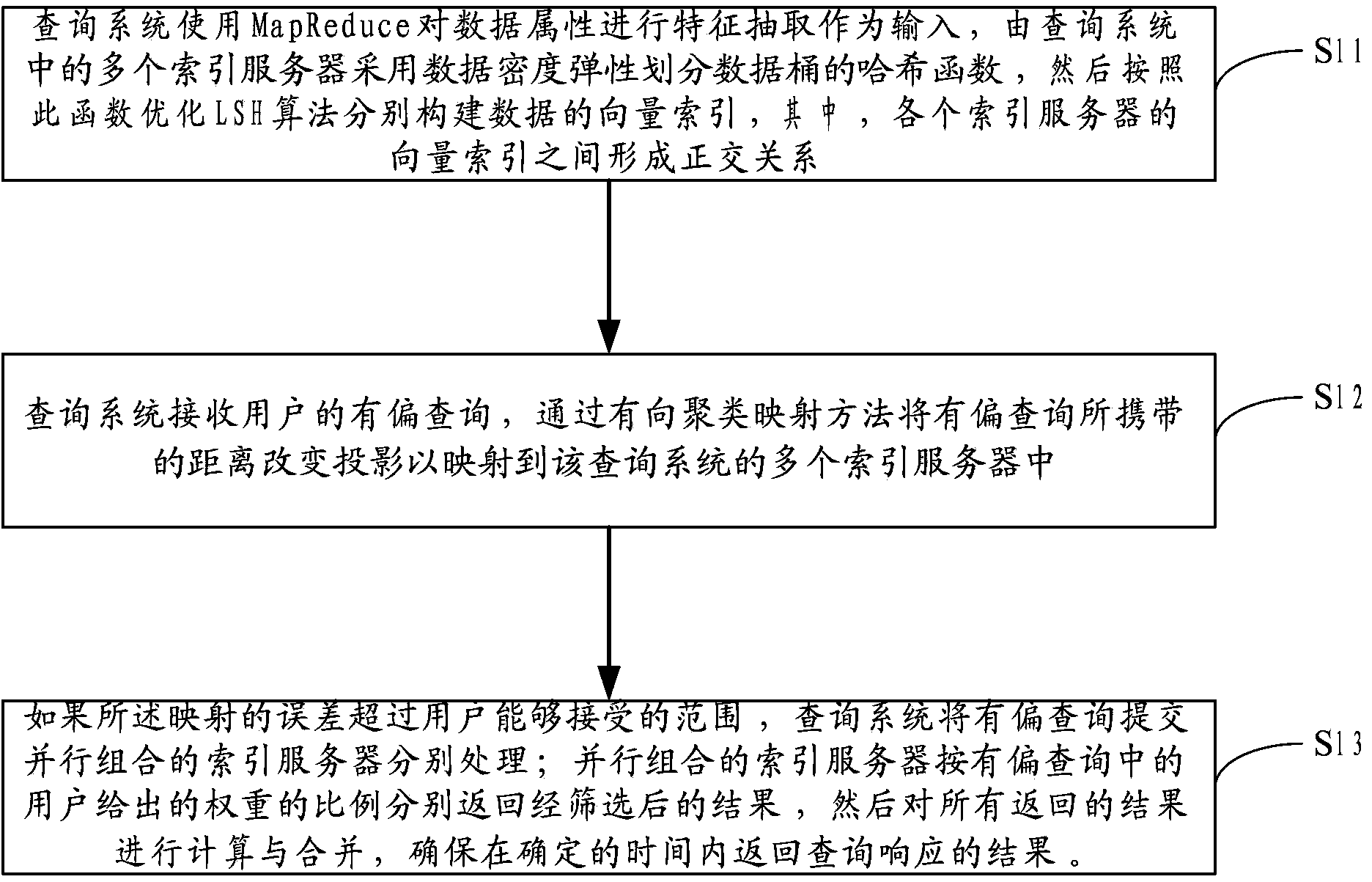
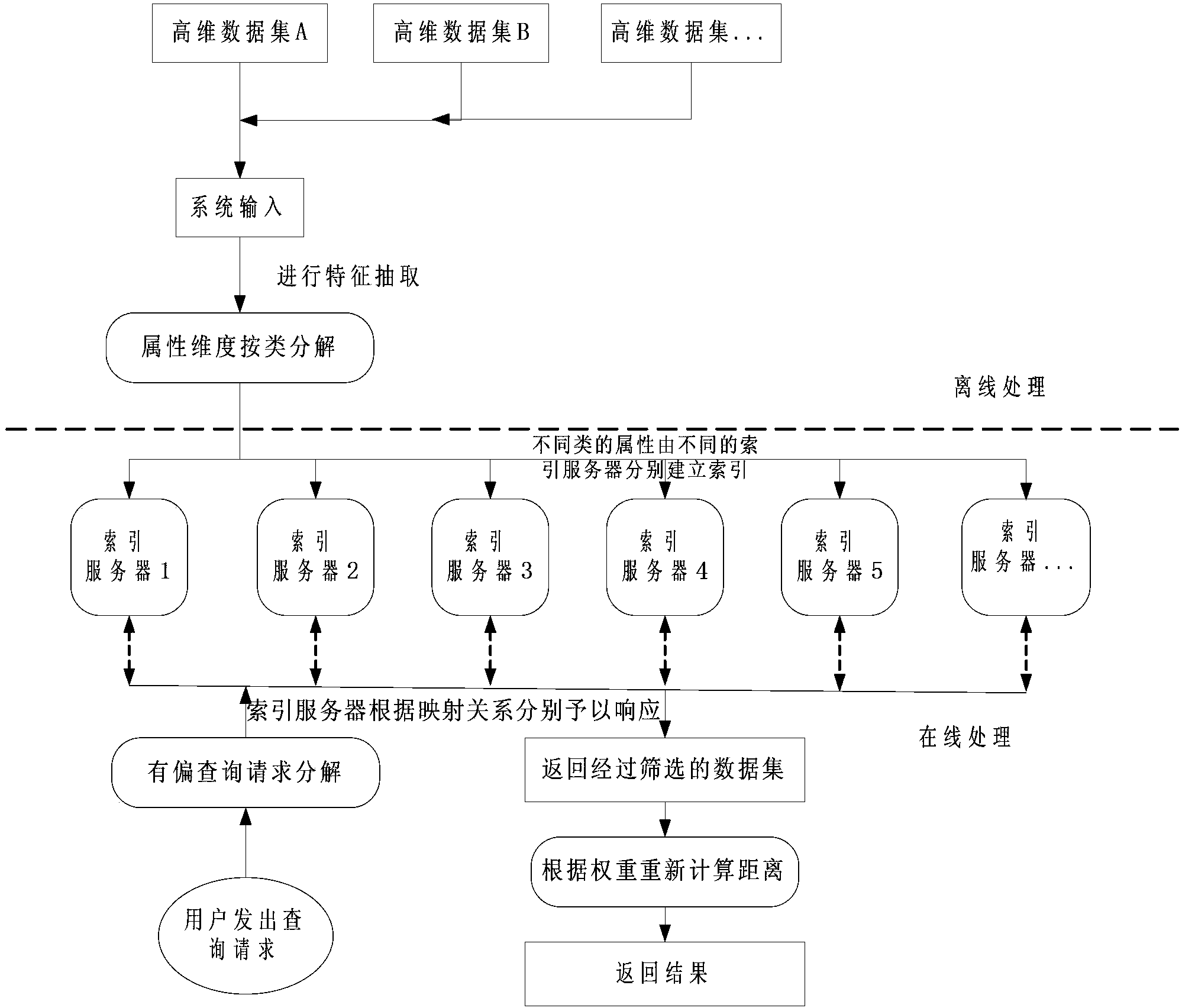
[0031] The flow chart of index establishment and query provided by the embodiment of the present invention is as follows figure 2 As shown, it is divided into two parts, the offline processing part and the online processing part.
[0032] Offline processing part: use (MapReduce and other methods) to perform feature extraction on data attributes as input, and multiple index servers use hash functions that elastically divide data buckets according to data density (such as normal distribution) to construct data vectors according to the LSH algorithm Index, the vector index of each index server forms an orthogonal relationship to support the index of massive data.
[0033] Online processing part: when the user's query comes, the distance change caused by the user's biased (weighted) query is first projected into the existing index structure through the directed clustering mapping method, so as to reduce the calculation time of index reconstruction ; If the mapping error exceeds ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More