

Caching optimizing method of internal storage calculation
A cache optimization and memory computing technology, applied in computing, memory address/allocation/relocation, memory system, etc., can solve problems such as inability to increase memory usage, and achieve the effect of reducing programming burden
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
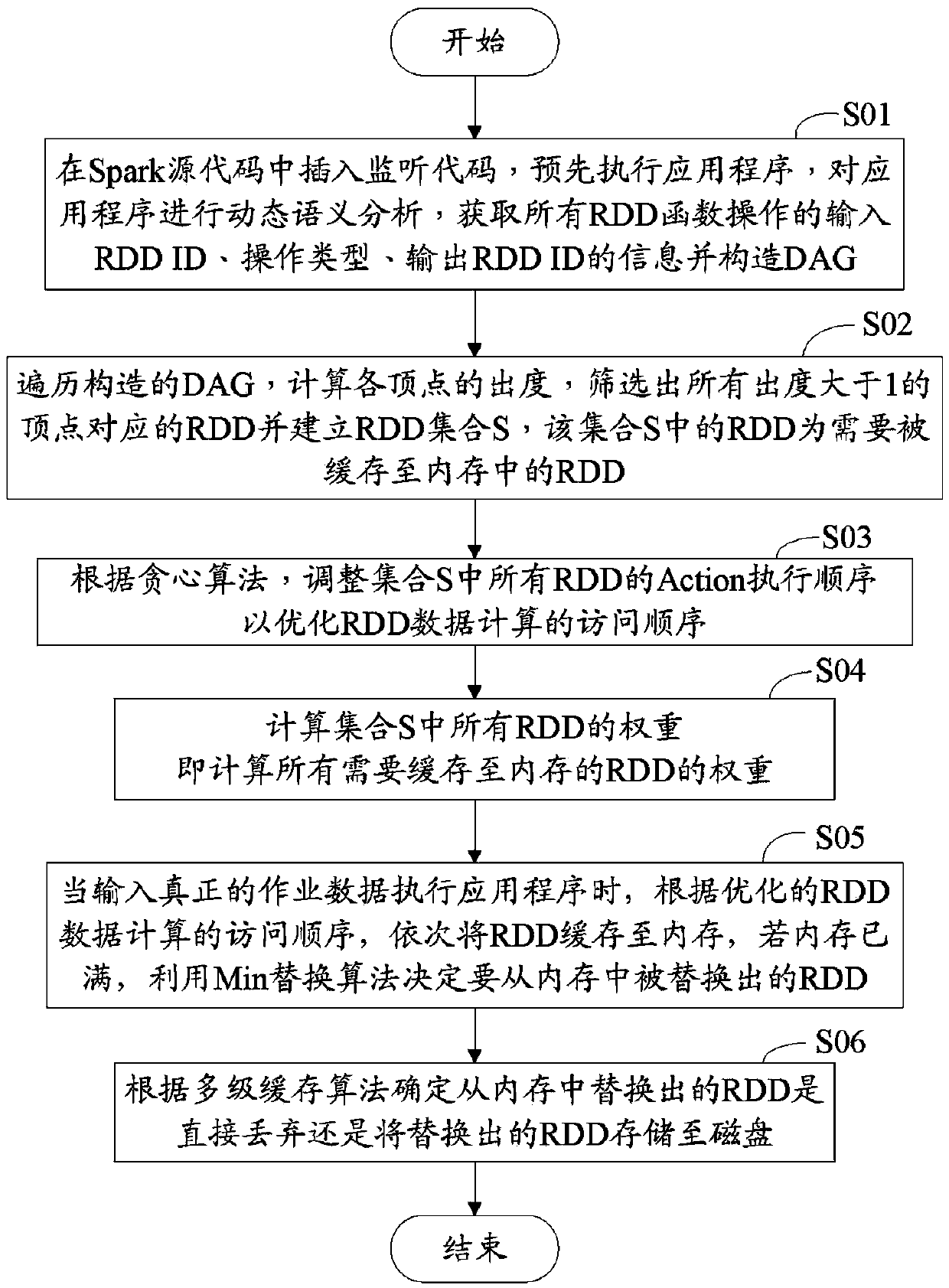
[0017] The memory computing cache optimization method (hereinafter referred to as "memory optimization method") of the present invention is an optimization of the existing open source project Spark. Applying the memory optimization method can improve memory utilization and further improve the operation of parallel processing of large data. speed.
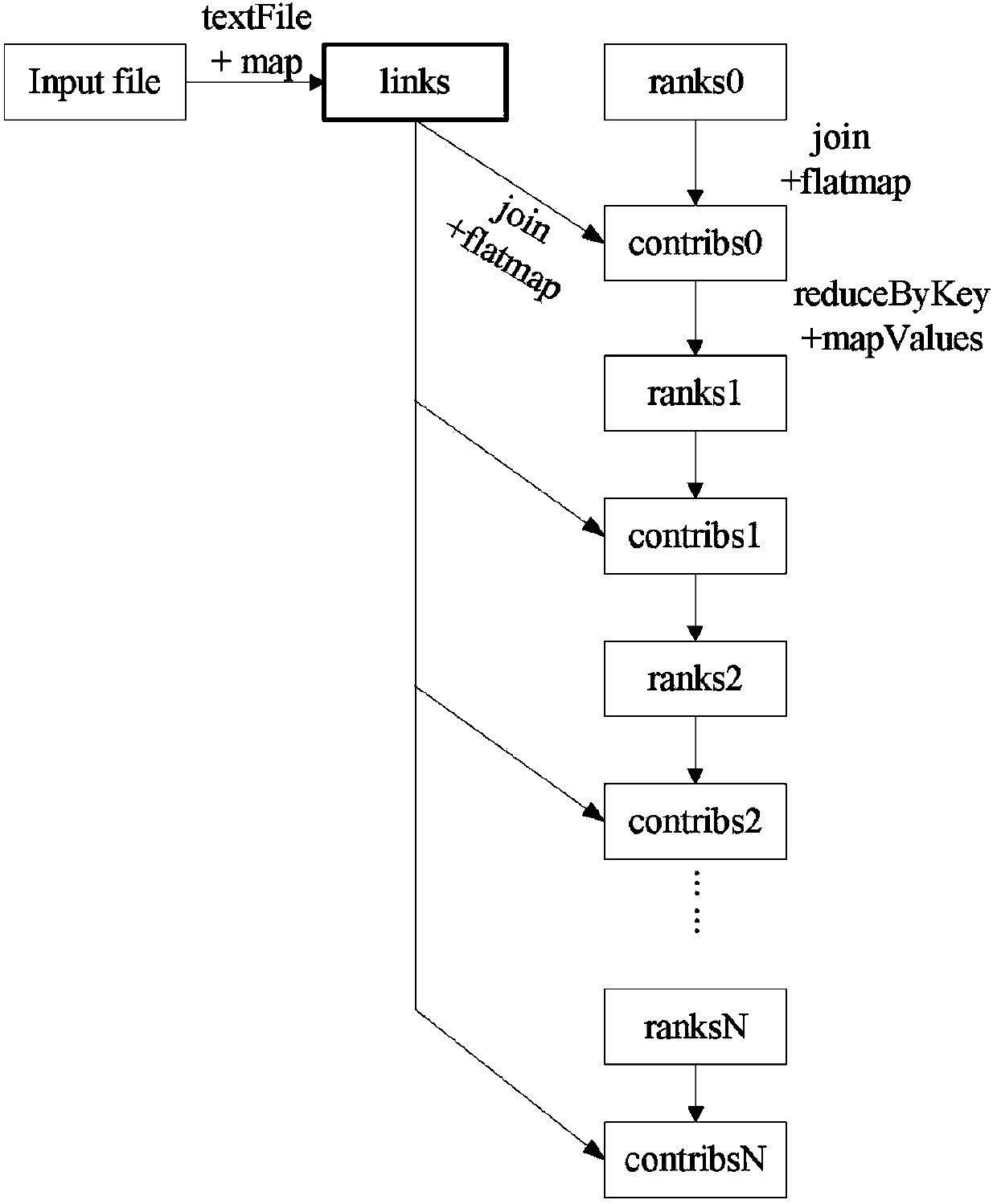
[0018] Spark is implemented in Scala language, which is an effective and general-purpose programming language framework that allows interactive analysis of data sets on clusters. The Scala language is a statically typed, functional, object-oriented language based on the JVM (Java Virtual Machine, Java Virtual Machine). Among them, RDD (Resilient Distributed Dataset, Resilient Distributed Dataset) is an important abstract concept of Spark. It is a set of read-only record partitions distributed on cluster nodes with fault tolerance mechanism and parallel operation. All data can be loaded into Memory, which allows memory-based computa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More