

Webpage class feature vector extracting method based on ant colony algorithm
An ant colony algorithm and feature word technology, applied in the field of text mining, can solve the problems of complex redundancy of Internet information and the inability of learning algorithms to deal with it, and achieve the effect of high accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
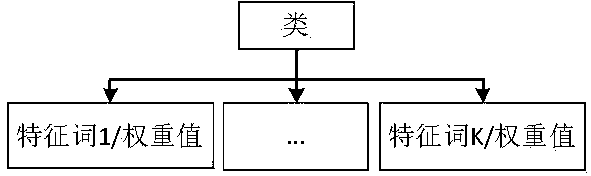
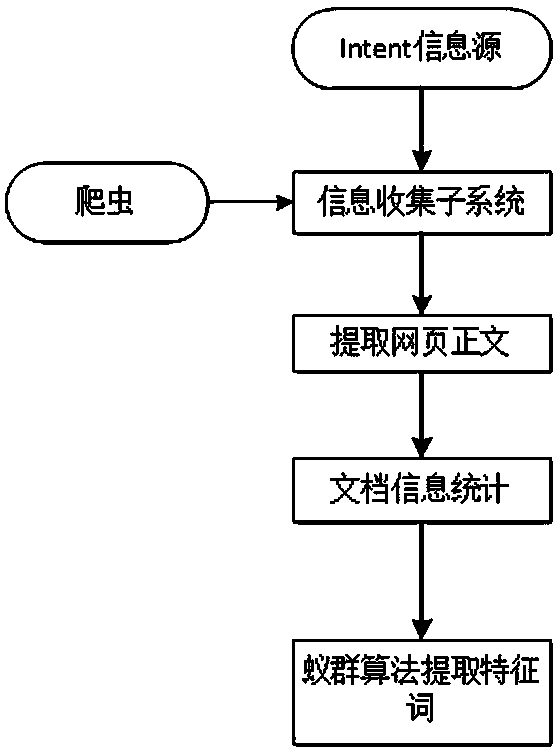
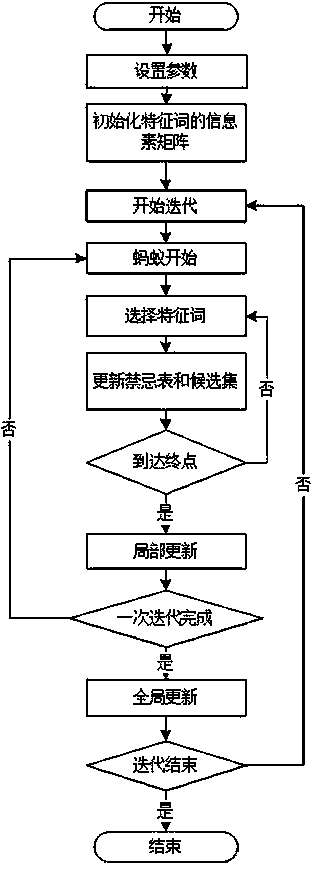
[0029] The present invention is based on the traditional search engine, extracts categories according to the manual classification catalog of DMOZ, and then uses the web crawler to crawl the first 200 results of the full-text search engine search results according to the category names, and excludes webpage tags, advertisements, etc. After waiting for the noise information, the text of the web page is extracted as a sample set. Then use the tokenizer to segment the training set, remove stop words and low-frequency words, and count the word frequency of each word in each article, the total number of documents where the word appears, the number of times the word and the class name co-occur, and the total number of articles . Finally, the improved ant colony algorithm is used to extract the feature words and obtain their weight values, so as to obtain the class and its feature words. The specific structure of the class is as figure 1 shown. The classifier is constructed in thi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More