

Big-data clustering algorithm based on cloud computing platform
A cloud computing platform and clustering algorithm technology, applied in computing, electrical digital data processing, special data processing applications, etc., can solve the problem of not considering the different effects of big data data points on knowledge discovery tasks, not considering the relative distance of data points, Problems such as uneven data distribution can achieve the effects of reducing data processing costs, facilitating development, and improving processing capacity and speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] The technical solutions of the present invention will be further described in detail below in conjunction with specific embodiments.
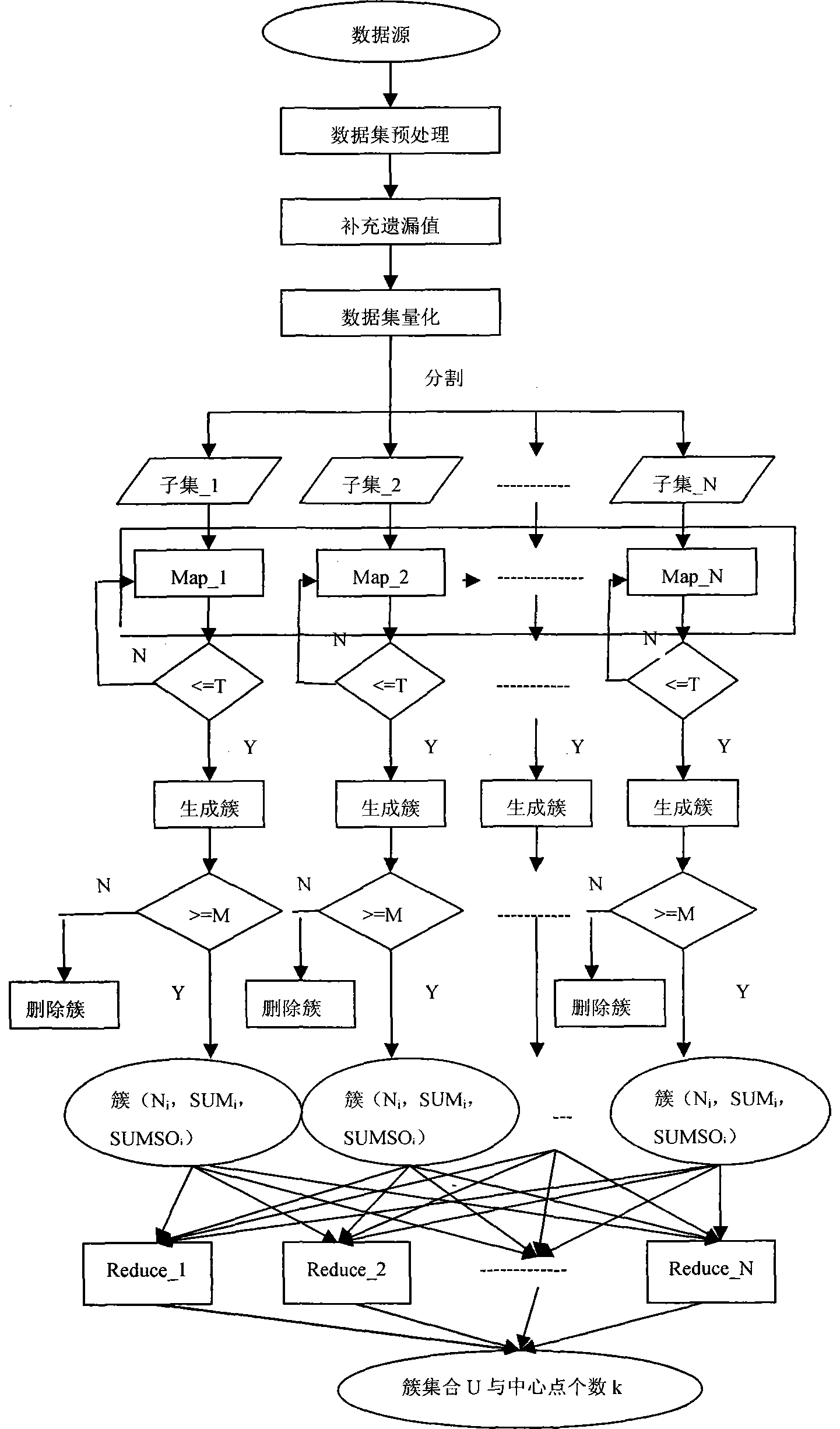
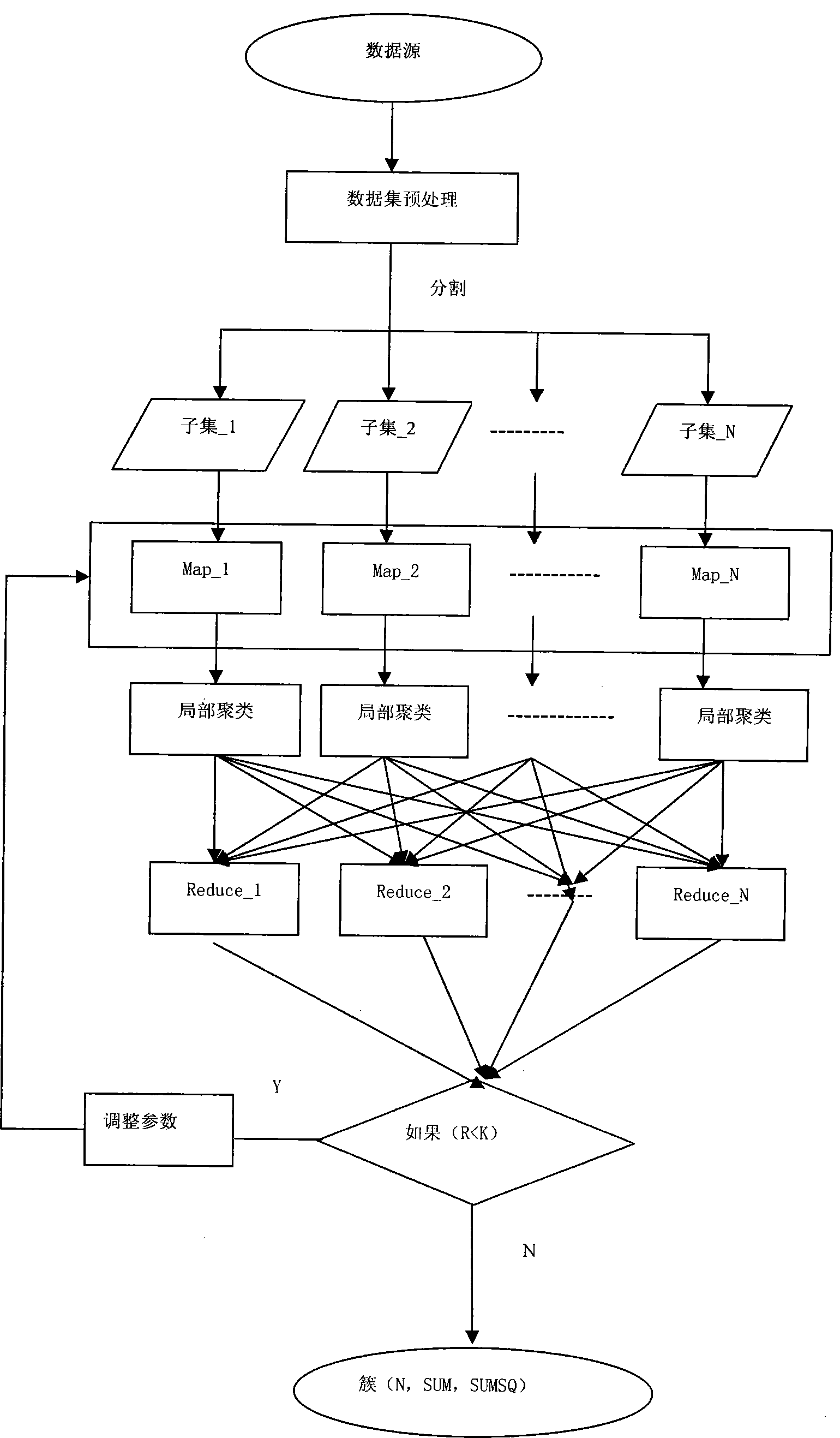
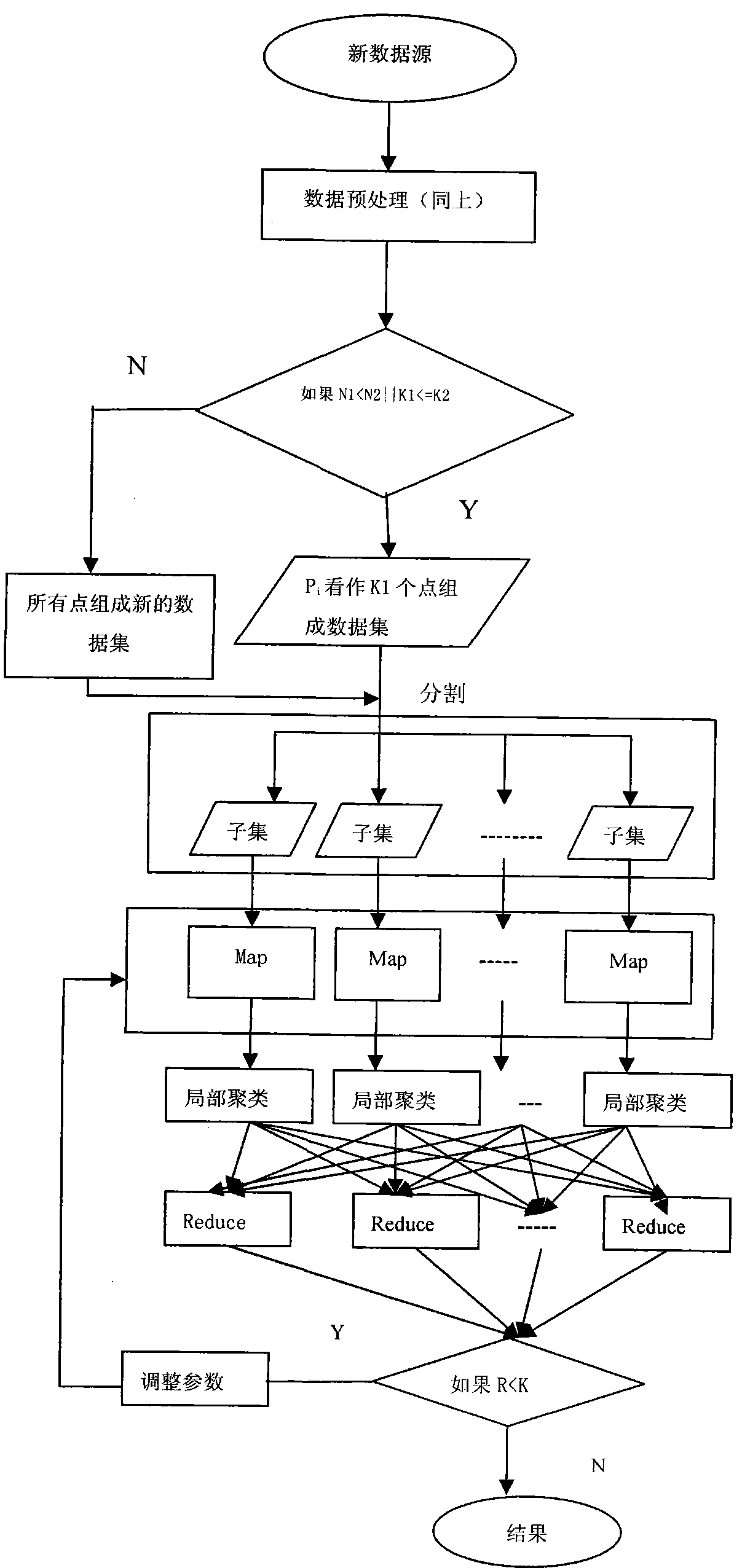
[0045] refer to figure 1 , 2 , 3, figure 1 Among them, T: the distance between points; M: the number of points included in the cluster; N: the number of points in the cluster; SUM: the vector sum of each dimension of all points; SUMSQ: the square of each dimension of all points and. image 3 Among them, N1: the number of points in the initial data source; N2: the number of new data sources; K1: the number of initial clusters; K2: the number of new preprocessed clusters; Pi: the center point of the initial cluster; K=[(K1 +K2) / 2].
[0046] A big data clustering algorithm based on cloud computing platform, comprising the following steps:
[0047] (1) Preprocessing the raw data;
[0048] The basic idea is: first, scan the entire data source to see if there are null values, and supplement missing values; the selection of missing values...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More