

Multiple GPUs-based BPNN training method and apparatus
A training method and technology of a training device, which are applied in the field of neural network training, can solve the problems of high data synchronization overhead and low efficiency, and achieve the effect of reducing data synchronization overhead and improving training efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
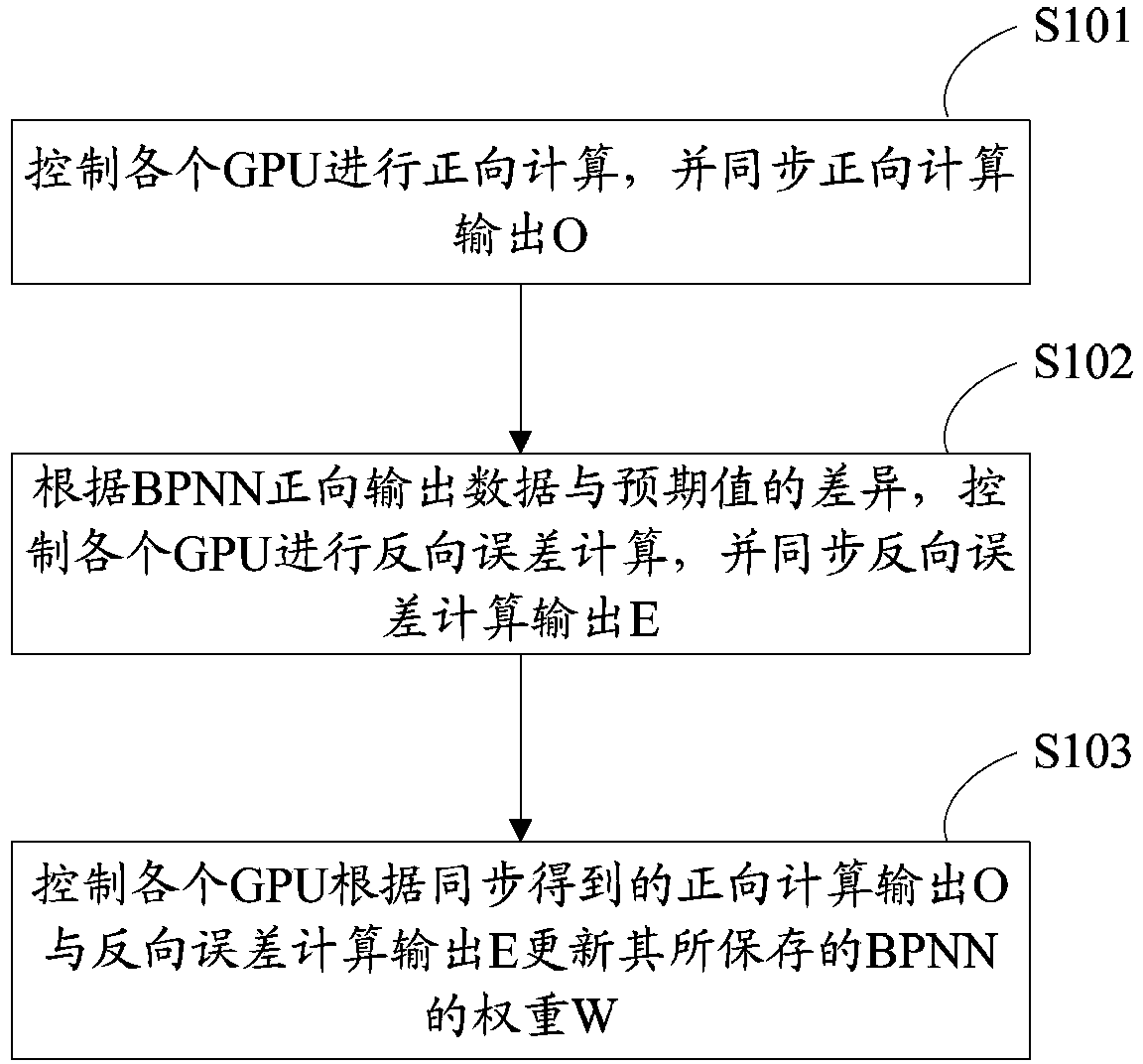
[0041] figure 1 The flow chart of the multi-GPU-based BPNN training method provided by Embodiment 1 of the present invention, such as figure 1 As shown, the method includes:
[0042] S101. Control each GPU to perform forward calculation, and output O for forward calculation synchronously.
[0043] The forward calculation and reverse error calculation of BPNN are performed layer by layer, and the calculation output data of this layer can be synchronized between each GPU after the calculation of each layer is completed.
[0044]After the input layer transmits the data to the first hidden layer, each GPU is controlled to start forward calculation from the first hidden layer, and the forward calculation of each hidden layer can be completed and the forward calculation output O can be passed to the next At the same time as one hidden layer, the forward calculation output O of this layer is synchronized between each GPU, until the last layer of hidden layer transmits the forward c...
Embodiment 2
[0058] Image 6 A schematic diagram of a multi-GPU-based BPNN training device provided in Embodiment 2 of the present invention, such as Image 6 As shown, the device includes: a forward calculation unit 10 , a reverse error calculation unit 20 , and a weight update unit 30 .
[0059] The forward calculation unit 10 is used for controlling each GPU to perform forward calculation of BPNN, and synchronously outputting the forward calculation among each GPU.
[0060] The forward calculation and reverse error calculation of BPNN are performed layer by layer, and the calculation output data of this layer can be synchronized between each GPU after the calculation of each layer is completed.
[0061] After the data is passed from the input layer to the first hidden layer, the forward calculation unit 10 controls each GPU to start forward calculation from the first hidden layer, and the forward calculation of each hidden layer can be completed and the forward calculation While the o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More