

Video description method based on deep learning and text summarization
A text summary and video description technology, applied in the field of video description, can solve the problems of lack of human natural language expression color, single sentence structure, difficulty in implementation, etc., and achieve good video description effect and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
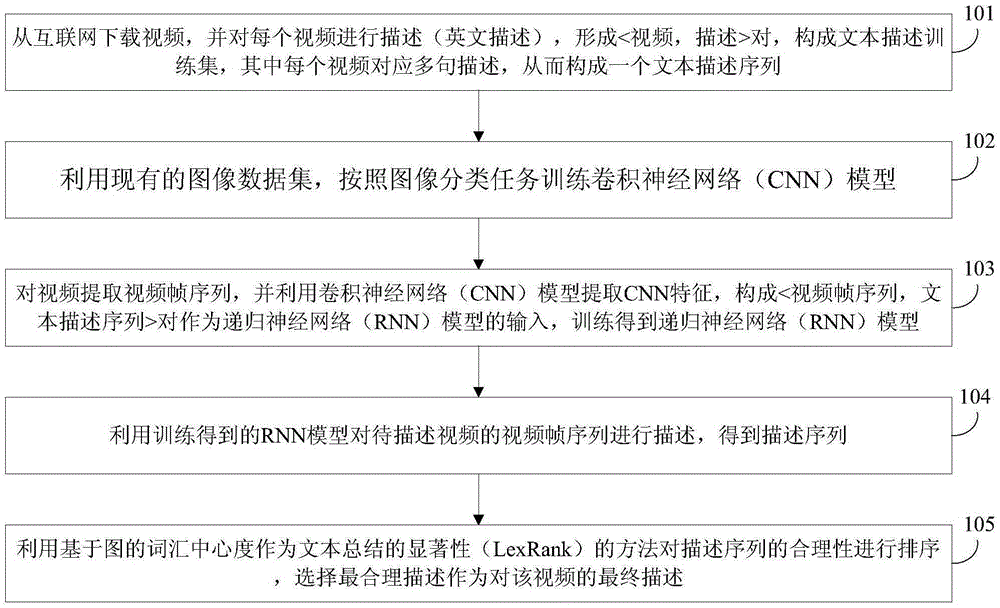
[0037] A video description method based on deep learning and text summarization, see figure 1 , the method includes the following steps:
[0038] 101: Download videos from the Internet, and describe each video (English description), form a pair, and form a text description training set, wherein each video corresponds to multiple sentence descriptions, thereby forming a text description sequence;
[0039] 102: Utilize the existing image data set to train a convolutional neural network (CNN) model according to the image classification task;
[0040] For example: ImageNet.
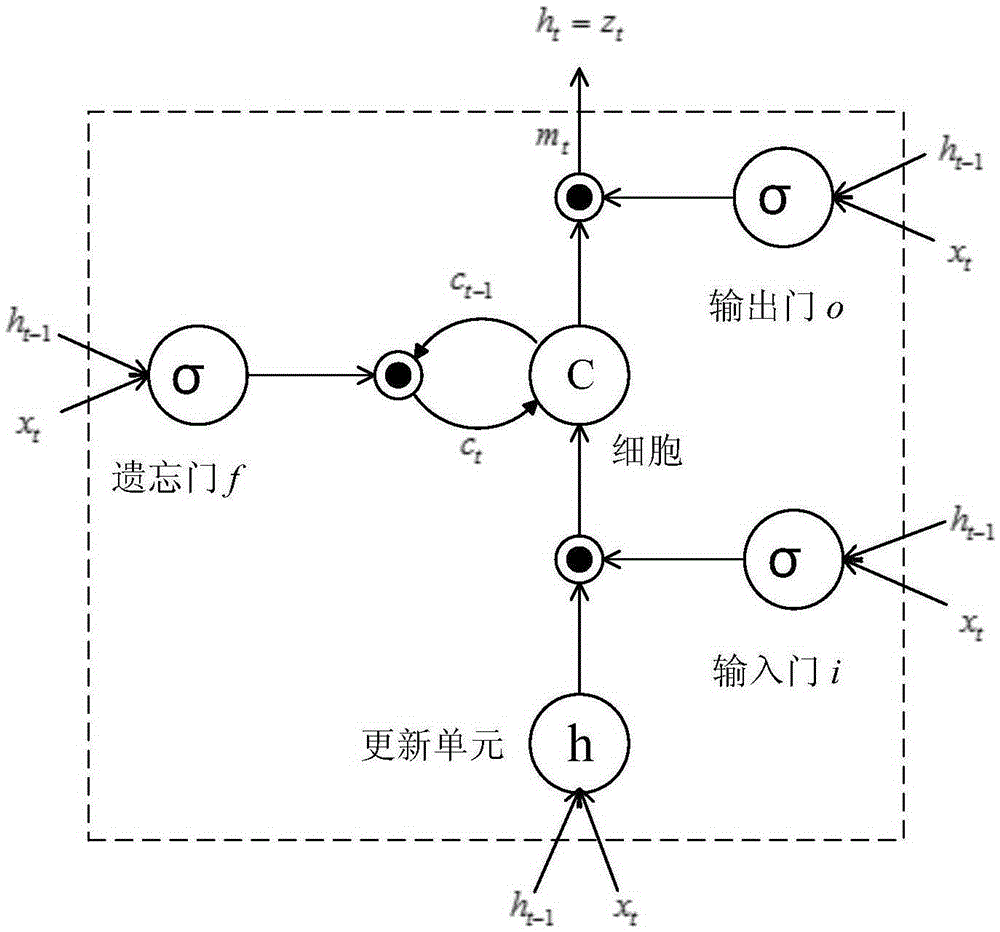
[0041] 103: Extract the video frame sequence from the video, and use the convolutional neural network (CNN) model to extract CNN features, form a pair as the input of the recurrent neural network (RNN) model, and train the recurrent neural network (RNN) model;
[0042] 104: Using the trained RNN model to describe the video frame sequence of the video to be described to obtain a description sequence;
[...
Embodiment 2
[0046] 201: Download images from the Internet, and describe each video to form a pair to form a text description training set;
[0047] This step specifically includes:
[0048] (1) Download the Microsoft Research Video Description Dataset (MicrosoftResearchVideoDescriptionCorpus) from the Internet. This data set includes 1970 video segments collected from YouTube. The data set can be expressed as V I D = { Video 1 , ... , Video N d } , where N d is a video in the collection VID total.
[0049] (2) Each video will have multiple corresponding descriptions, and the sentence description of each video is Sentences={Sentence 1 ,...,Sentence N}, where N represents the sentence corresponding to each video (Sentence 1 ,...,Sentence N ) description number.
[0050] (3) The ...
Embodiment 3
[0124] Here, two videos are selected as the videos to be described, such as Figure 5 As shown, use the method based on deep learning and text summary in the present invention to predict and output the corresponding video description:
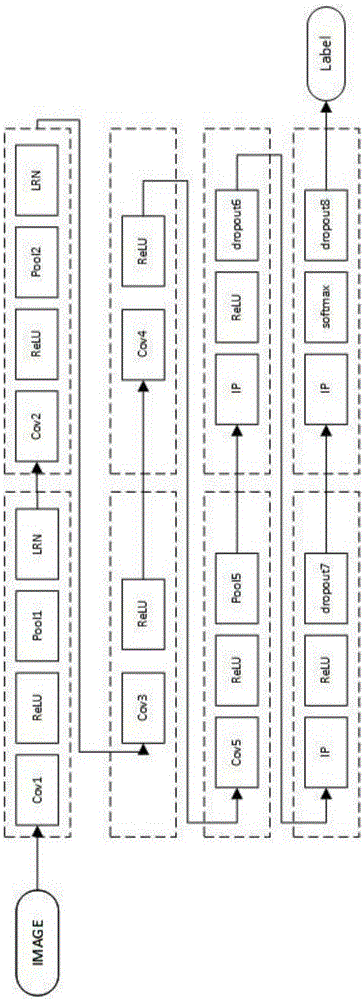
[0125] (1) Use ImageNet as the training set, sample each picture in the data set to a picture of 256*256 size, I M A G E = { Image 1 , ... , Image N m } As input, N m is the number of pictures.
[0126](2) Build the first convolutional layer, set the convolution kernel cov1 size to 11, stride to 4, select ReLU as max(0,x), perform pooling operation on the convolutional featuremap, and the kernel size is 3. The stride is 2, and the convolutional data is normalized using local corresponding normalization. In AlexNet, k=2, n=5, α=10...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More