

Spark-based extreme learning machine parallelization calculation method
An extreme learning machine and computing method technology, applied in the field of parallel computing, can solve the problem of low efficiency of parallelization schemes, and achieve the effects of improving operating efficiency, reducing the number and improving computing efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] specific implementation
[0029] Embodiments of the present invention will be further described below in conjunction with the accompanying drawings
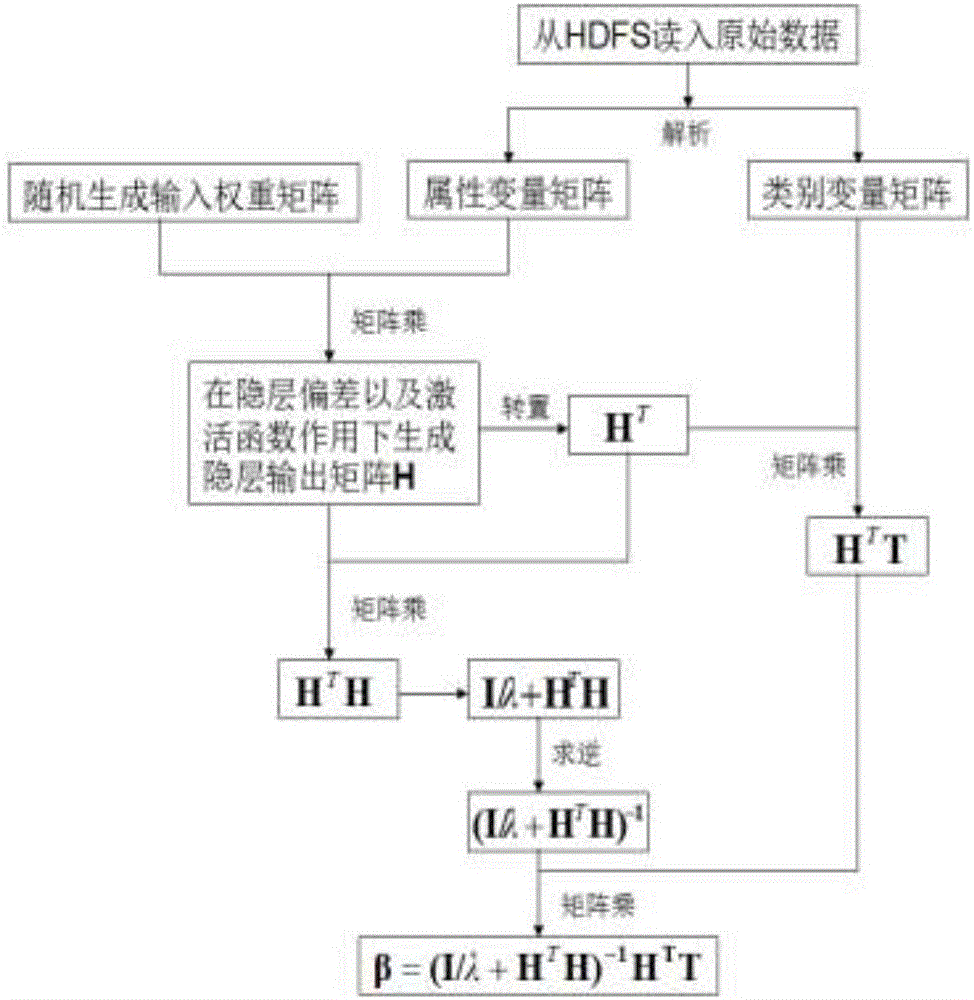
[0030] Such as figure 1 Shown, the Spark-based extreme learning machine parallelization calculation method of the present invention, the steps are as follows:
[0031] a. Combine the original feature and category data with specific problems to convert attributes and categories into specific values, and then perform a normalization operation on each attribute. Each sample attribute is used as a row to obtain an attribute variable matrix, and each category is used as a row. Get the category variable matrix;
[0032] b. Randomly generate the input weight matrix ω, the number of rows of the weight matrix is the number of attribute variables of each sample, the number of columns of the weight matrix is the number of hidden layer nodes of the neural network, and the product of the two is obtained by multiplying ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More