

High-dimensional sparse text data clustering method based on Spark
A technology of text data and clustering method, applied in text database clustering/classification, unstructured text data retrieval, electrical digital data processing, etc. and computing time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0043] The technical solutions in the embodiments of the present invention will be described clearly and in detail below with reference to the drawings in the embodiments of the present invention. The described embodiments are only some of the embodiments of the invention.
[0044]Technical scheme of the present invention is as follows:
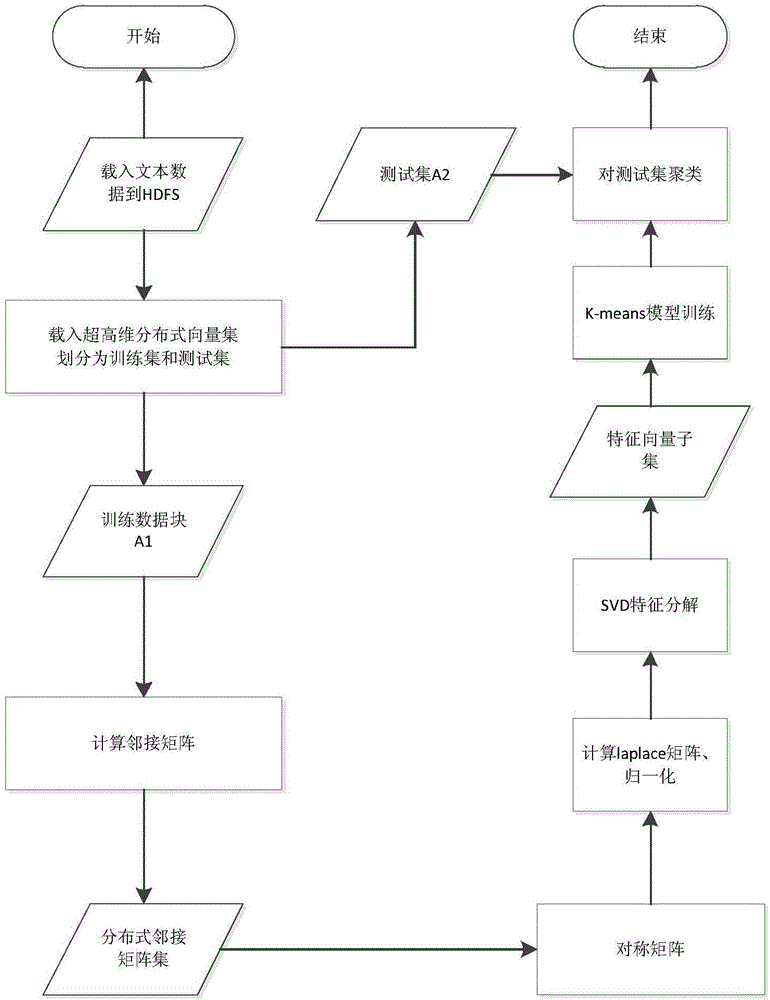
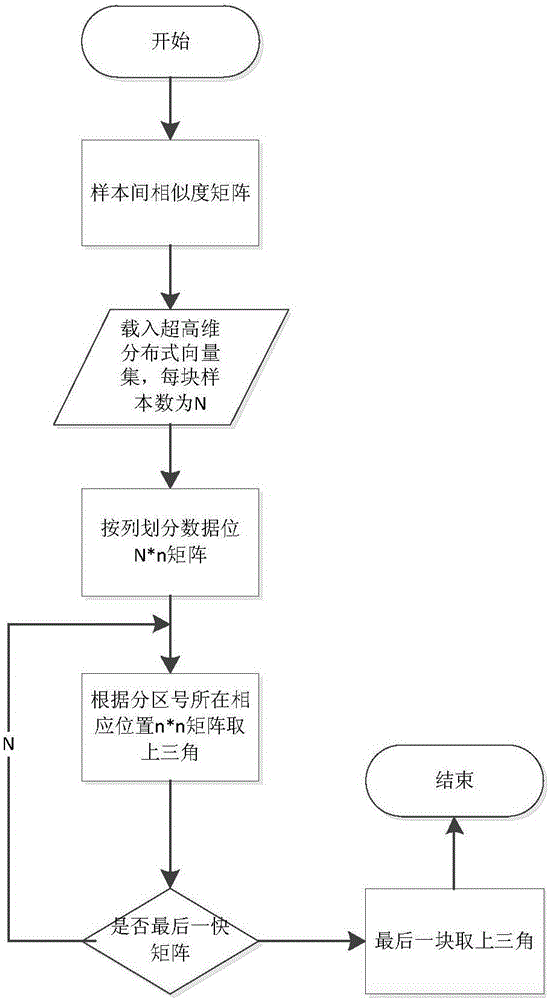
[0045] figure 1 It is a flow chart of the present invention, comprising the following steps:
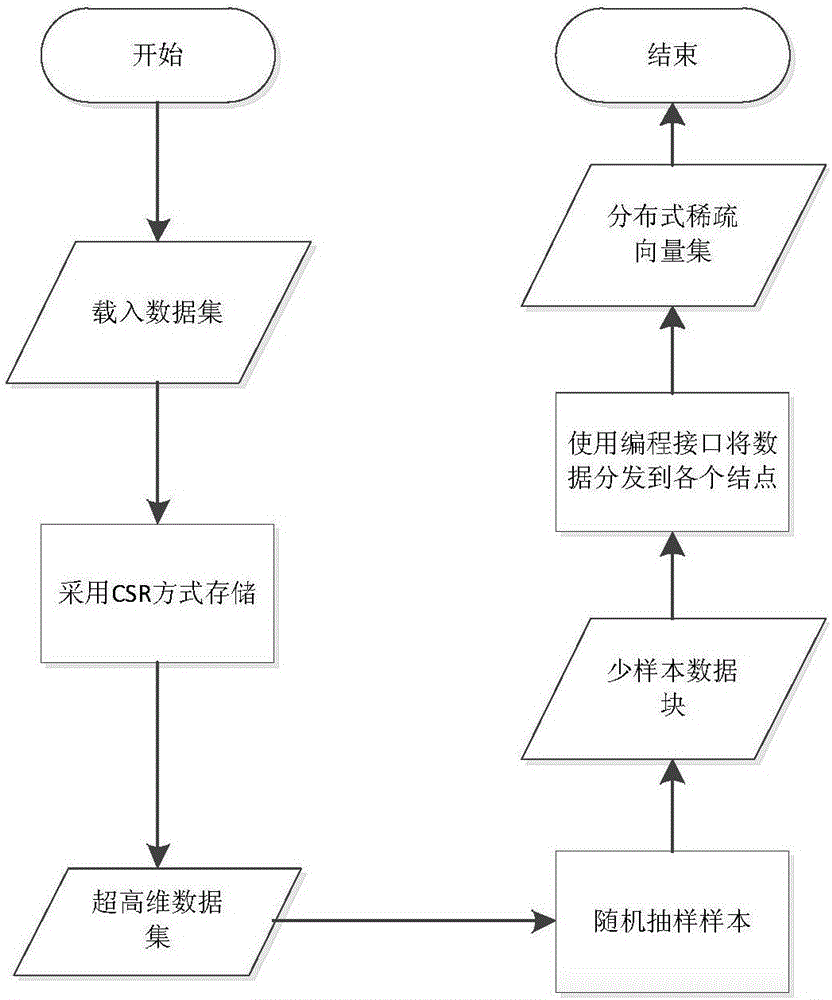
[0046] 1. The stage of loading data is as shown in the figure, such as figure 2 shown;
[0047] At this stage, the data source to be processed (source UCI data platform) needs to be read into the elastic distributed data set (RDD), then loaded into the high-dimensional distributed vector set data P, and divided into training set A 1 and test set A 2 ,
[0048] Download the RCV1 data set from the UCI experimental data platform (URL: http: / / archive.ics.uci.edu / ml / ), the form of the data set is {decision label, condition attribute 1, condition a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More