

Text classification method based on deep multi-task learning
A multi-task learning and text classification technology, applied in the field of natural language processing, can solve the problems of insufficient training data and the decline of test set generalization ability, and achieve the effect of solving insufficient training data and improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

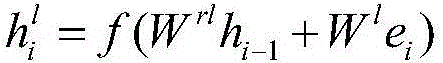
Examples
Embodiment 1
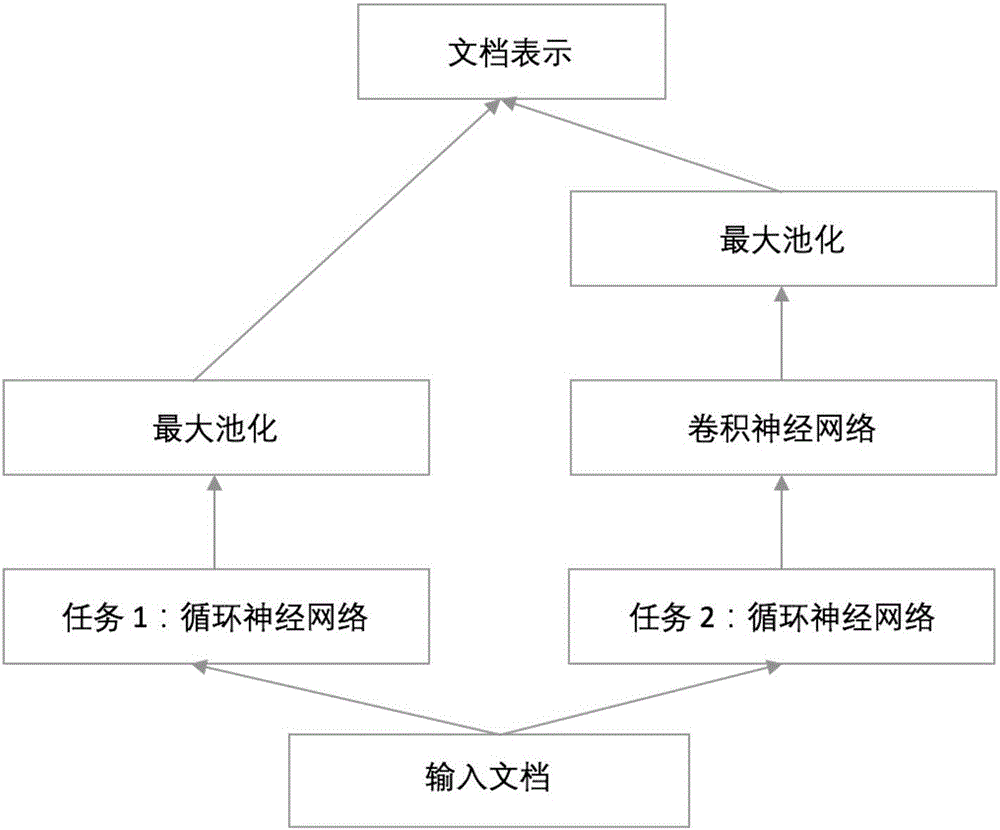
[0038] like Figure 1-2 As shown, a text classification method based on deep multi-task learning includes the following steps:
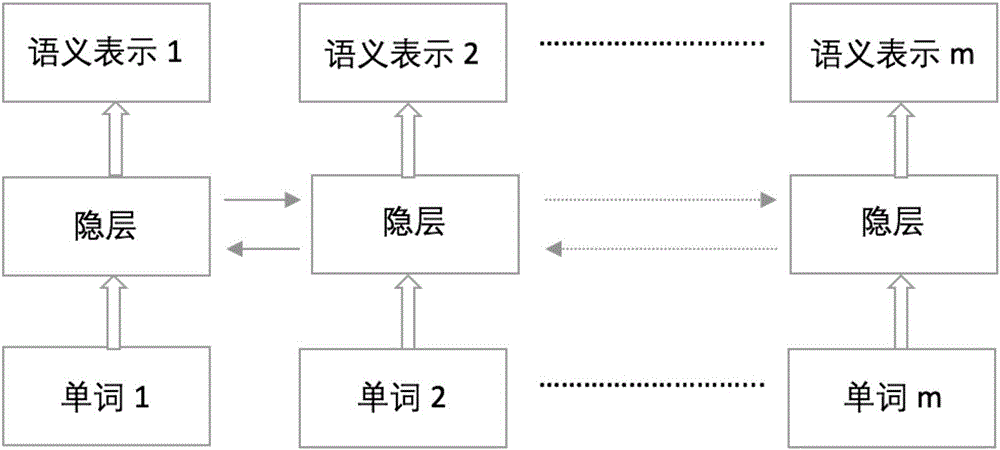
[0039] S1: Use word vectors and bidirectional recurrent networks to learn the document representation of the current task;
[0040] S2: Extract features from document representations of other tasks using convolutional neural networks;
[0041] S3: Learn a classifier using the document representation of the current task and the features of other tasks.
[0042] The specific process of step S1 is:
[0043] Divide all Chinese documents in all tasks into word segmentation, assuming that there are N words in total, and then assign each word a unique label, and then represent it as a K-dimensional vector, that is, all word vectors travel an N*K matrix, and then use positive The state distribution is randomly initialized, and the word vector matrix is shared by all tasks;
[0044] The document representation of the current task is learned with word ve...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More