

Parallel data reflow method under stream computing environment
A data and external data technology, applied in the information field, can solve problems such as increasing system complexity, frequent Tuple replay, increasing system load, etc., and achieve the effect of improving system responsiveness, priority processing, and fault tolerance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0039] In order to make the above-mentioned features and processes of the present invention more comprehensible, the following specific embodiments are described in detail with reference to the accompanying drawings.
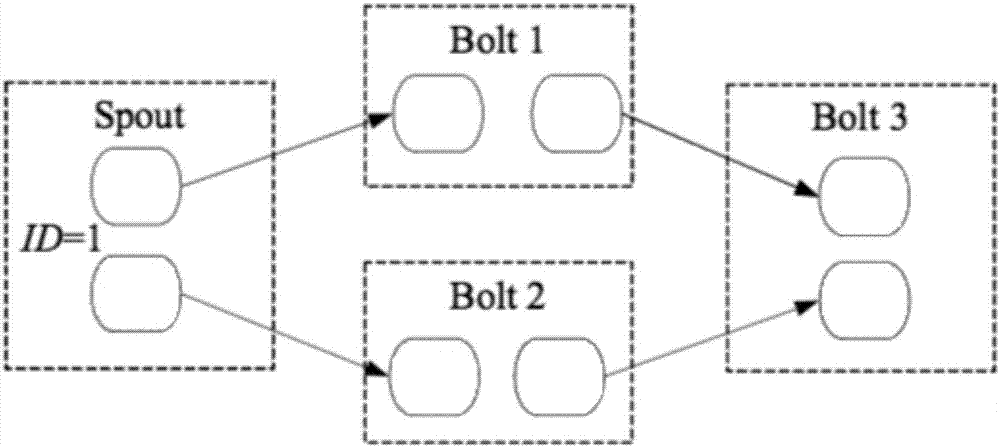
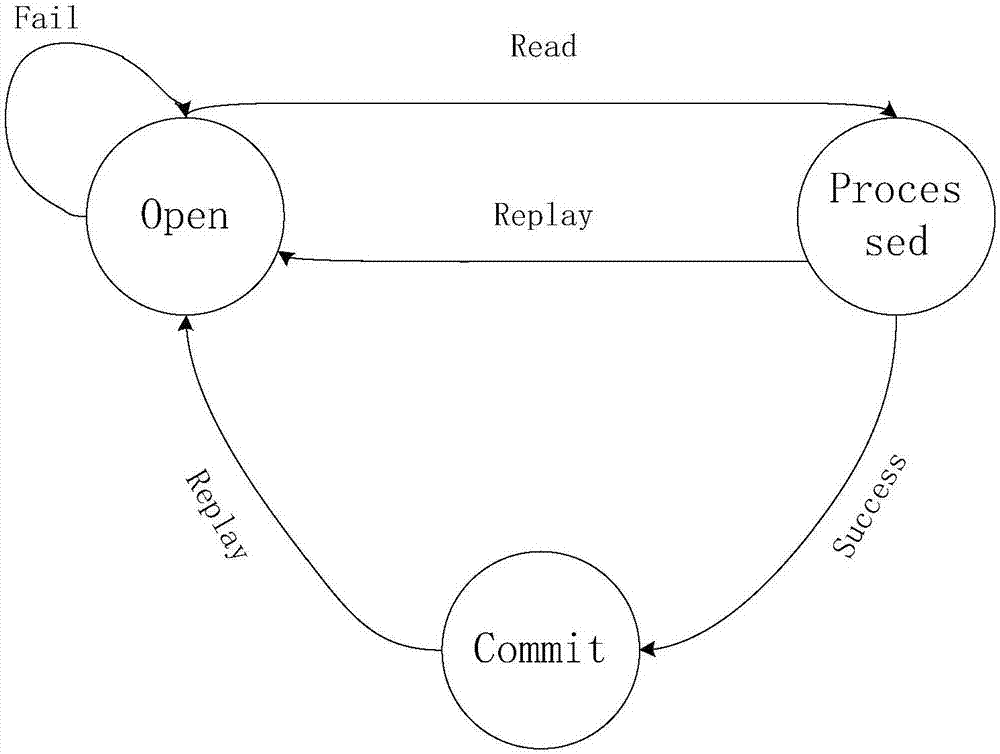
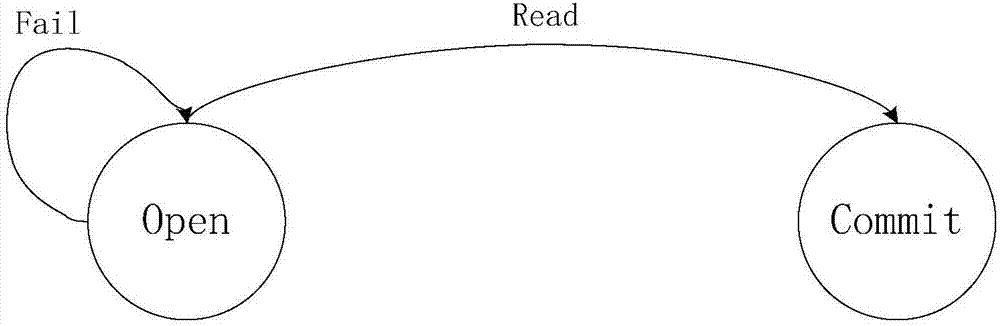
[0040] refer to Figure 1 ~ Figure 4, a parallel data backflow method for real-time stream computing, using Apache Storm as the real-time stream computing system and Apache Kafka as the data queue. The spouts in Apache Storm are divided into reliable spouts and unreliable spouts. Reliable Spout implements at-least-once semantics. It will resend failed Tuples to ensure that each Tuple is processed at least once. It is a stateful implementation of data; unreliable Spouts implement It is at-most-once semantics, and it will not process Tuples that fail to be sent. Because the data sending method nextTuple() and data confirmation method ack() / fail() of Spout in Storm in Storm are serially called in the same thread, where ack() is the function called when the Tuple ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More