

Content extraction method based on keyword matching
A keyword matching and keyword technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of difficult webpage text extraction, high error rate, high time complexity, and ensure objectivity and reasonableness. The effect of stability, high accuracy and good versatility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0041] The content of the present invention will be further elaborated below in conjunction with the accompanying drawings, but it is not intended to limit the present invention.
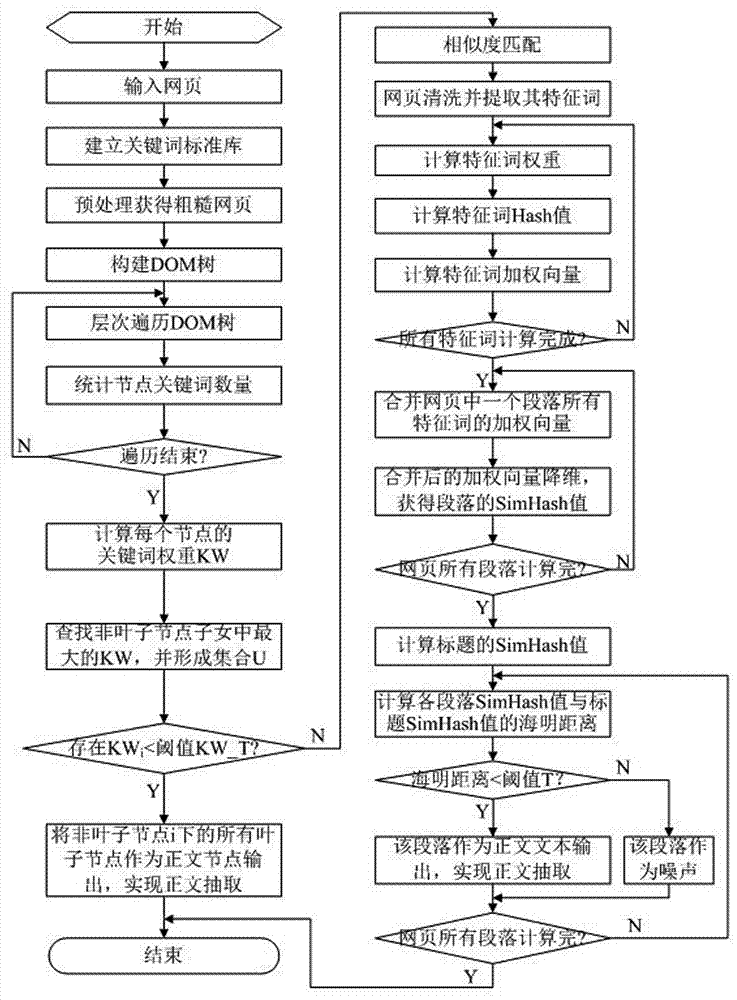
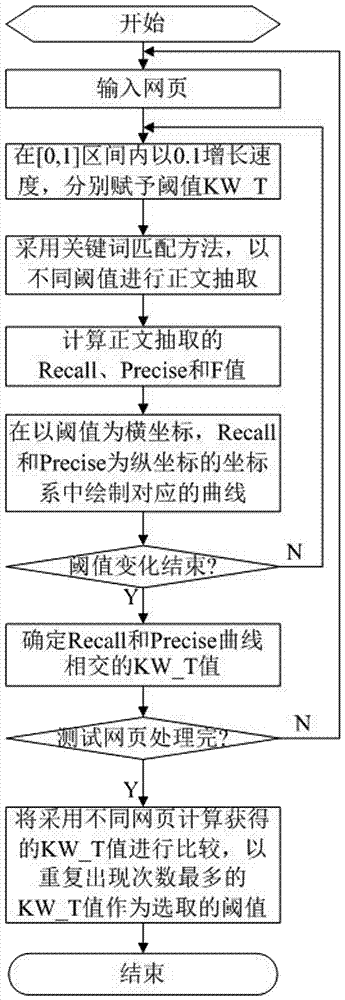
[0042] like figure 1 As shown, the text extraction method based on keyword matching of the present invention specifically includes the following steps:
[0043] (1) Webpage preprocessing, counting and extracting the keywords in the Keywords tag of the webpage source code, and establishing a standard library with keywords; using regular expressions to preprocess the webpage to be processed, removing obvious noise text, and obtaining a rough webpage;
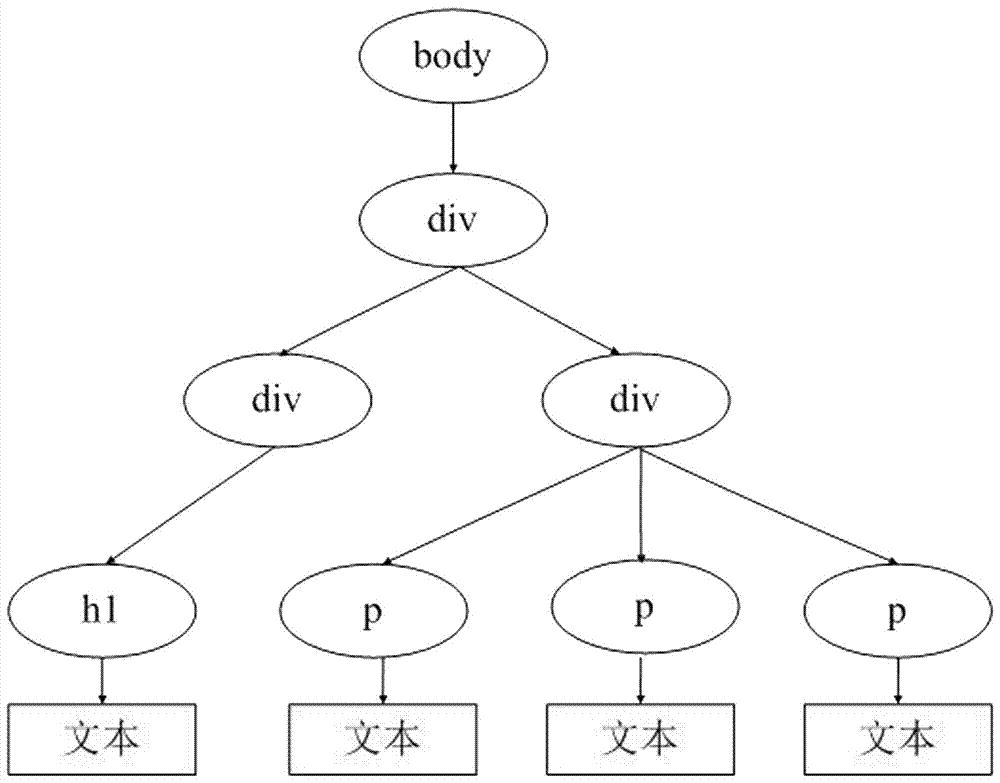
[0044] (2) Build a DOM tree, use the Jsoup tool to parse the HTML of the rough web page, and obtain the data of the rough web page; DOM uses a set of structured nodes and objects to represent the structure of the document, that is, each component in the document is defined as a node , so as to connect the webpage, scripting language and progr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More