

Advertisement Weibo article identification method based on stacking noise reduction own-coding machine
A recognition method and self-encoding technology, which can be used in natural language data processing, special data processing applications, network data retrieval, etc., and can solve problems such as feature redundancy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
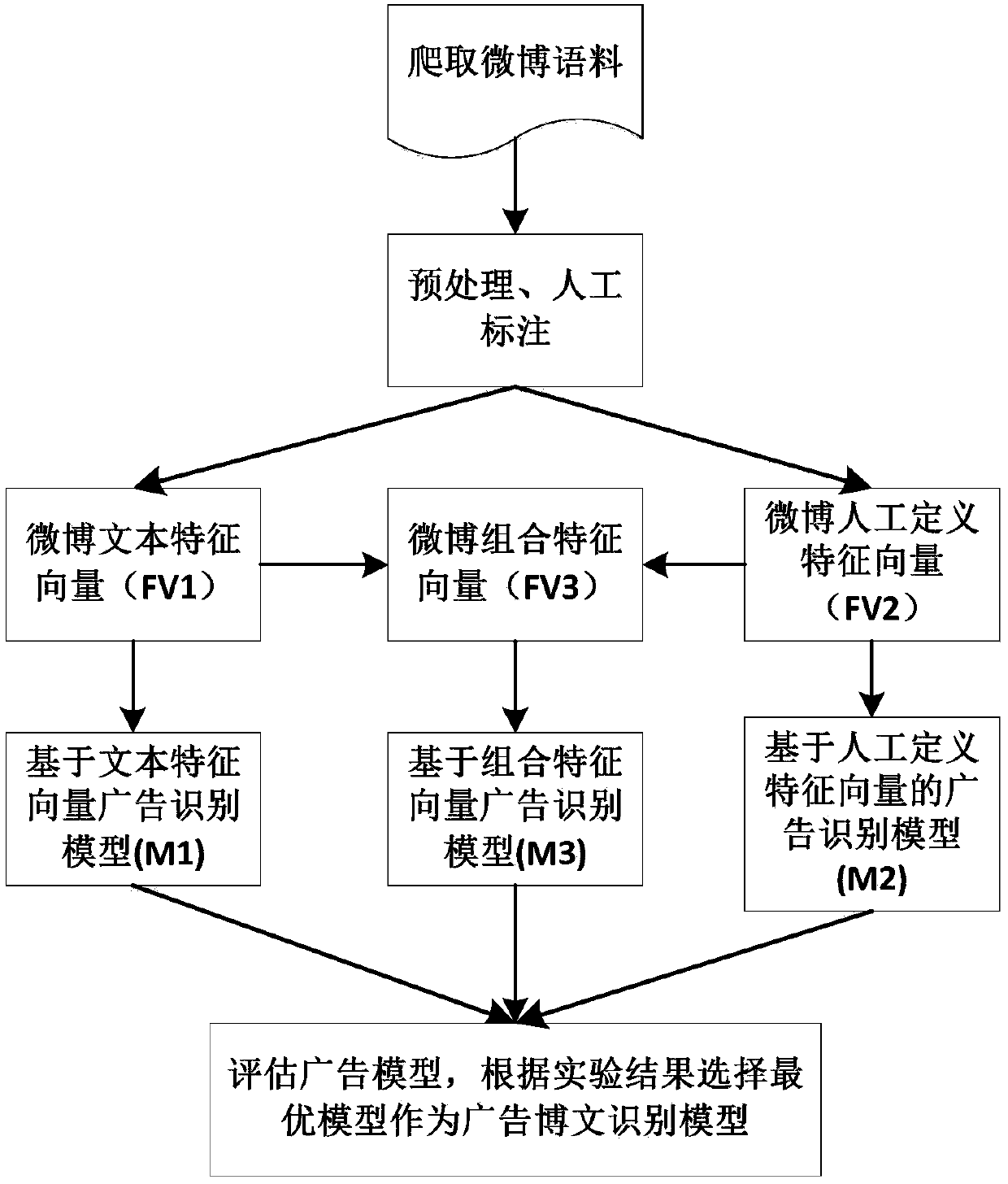
[0057] Example 1: Such as figure 1 As shown, the advertising blog post recognition method based on the stacked noise reduction self-encoder, the specific steps of the advertising blog post recognition method based on the stacked noise reduction self-encoder are as follows:
[0058] Step1. First crawl the Weibo corpus, obtain the training set and test set by manually labeling the corpus, and then preprocess the corpus;
[0059] Step2: Construct the feature vector of the Weibo text to represent the blog post, and then put the feature vector into the maximum entropy classification to train and model, and obtain an advertising blog post recognition model based on the feature vector of the Weibo text;
[0060] Step3. Construct a manually defined feature vector to represent the blog post, and then put it into the maximum entropy classification to train and model, and obtain an advertisement blog post recognition model based on the manually defined feature vector;
[0061] Step4. Construct a...
Embodiment 2
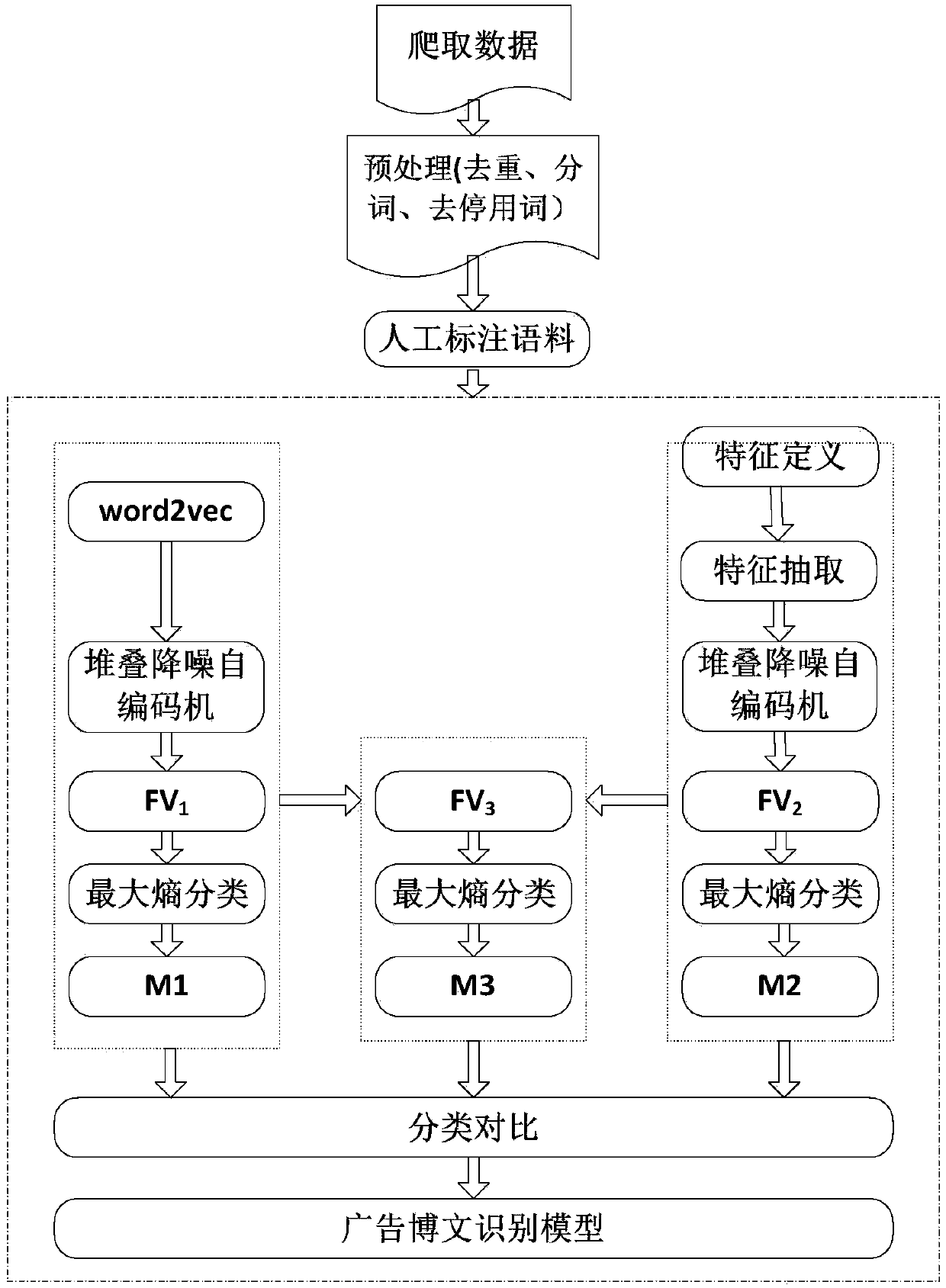
[0063] Example 2: Such as Figure 1-2 As shown, the advertising blog post recognition method based on the stacked noise reduction self-encoder, this embodiment is the same as the embodiment 1, in which:
[0064] As a preferred solution of the present invention, the specific steps of Step 1 are:
[0065] Step1.1. First, manually write a crawler program, crawl Weibo to obtain Weibo corpus;
[0066] Step1.2. Filter and de-duplicate the crawled Weibo corpus to obtain non-repetitive Weibo corpus, and store the Weibo corpus in the database;
[0067] The present invention takes into account that there may be repeated blog posts in the crawled microblog corpus. These blog posts increase the workload and are of little significance. Therefore, it is necessary to filter and de-duplicate to obtain the non-repetitive microblog blog corpus, which is stored in the database in order to be able to Convenient data management and use.
[0068] Step1.3. Manually label the corpus in the database to obtain ...
Embodiment 3
[0070] Example 3: Such as Figure 1-2 As shown, the method for identifying advertisement blog posts based on stacked noise reduction self-encoders, this embodiment is the same as embodiment 2, in which:
[0071] As a preferred solution of the present invention, the specific steps of Step 2 are:
[0072] Step2.1. First use word2vec to process the Weibo text to get the text vector of the Weibo;
[0073] The present invention takes into account that Sina Weibo has adjusted the word limit of the text from 140 to 2000, so that the feature words of the text are correspondingly expanded, and there are a large number of synonyms, and the context is heavily dependent, in order to avoid feature word redundancy. The invention first uses word2vec to process the text. With the help of word2vec in semantic information representation, each word in the text is converted into a vector representation, and then the corresponding dimension in the vector of each word in the blog post is accumulated and d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More