

Incremental naive Bayes text classification method based on lifelong learning
A text classification and incremental technology, applied in text database clustering/classification, unstructured text data retrieval, character and pattern recognition, etc., can solve the problem that performance cannot be improved, and achieve new feature processing and field Adaptive ability, the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

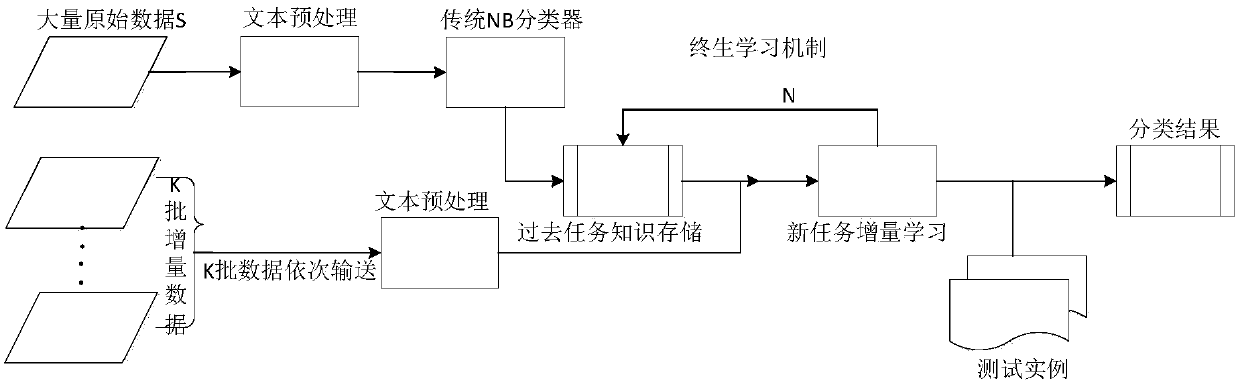
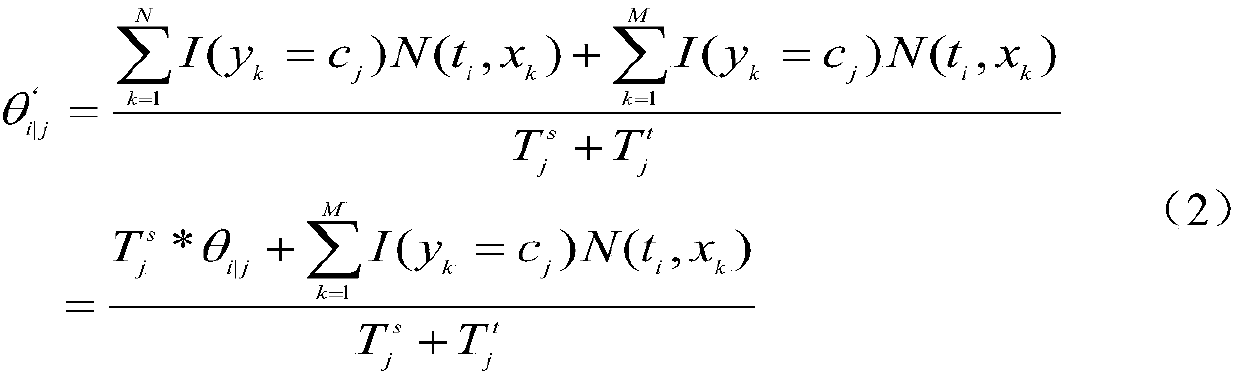
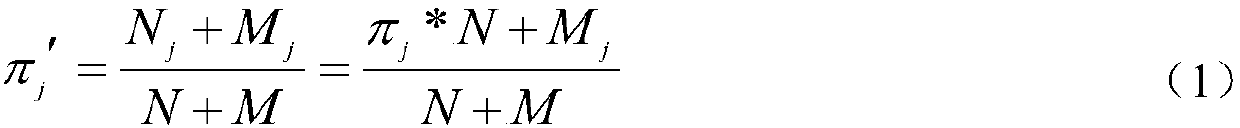
Examples
experiment example
[0044] In this embodiment, the performance analysis of the incremental naive Bayesian text classification method based on lifelong learning is carried out by using the classic text classification dataset 3 classification tasks, Movie review dataset and Multi-domain sentiment datasets; wherein the 3 classification tasks include movie3, network3 And health3, Multi-domain sentiment datasets include book, dvd, electronics and kitchen.
[0045] Experiments are further divided into two data conditions, domain-specific and domain-variant. Domain-specific means that historical data and incremental data come from the same domain, which is the most common text classification task. In domain changes, historical data and incremental data come from different related domains, which is the classification task of domain adaptation.
[0046](1) Domain-specific text classification
[0047] The domain-specific text classification and sentiment classification are respectively carried out on the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More