

A Method for Similarity Query of Time Series Data Based on Memory Computing
A time series and query method technology, applied in computing, digital data processing, structured data retrieval, etc., can solve problems such as increasing query delay and reducing query efficiency, achieving low space overhead and maintenance cost, and high query accuracy. , The effect of efficient time series similarity query
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
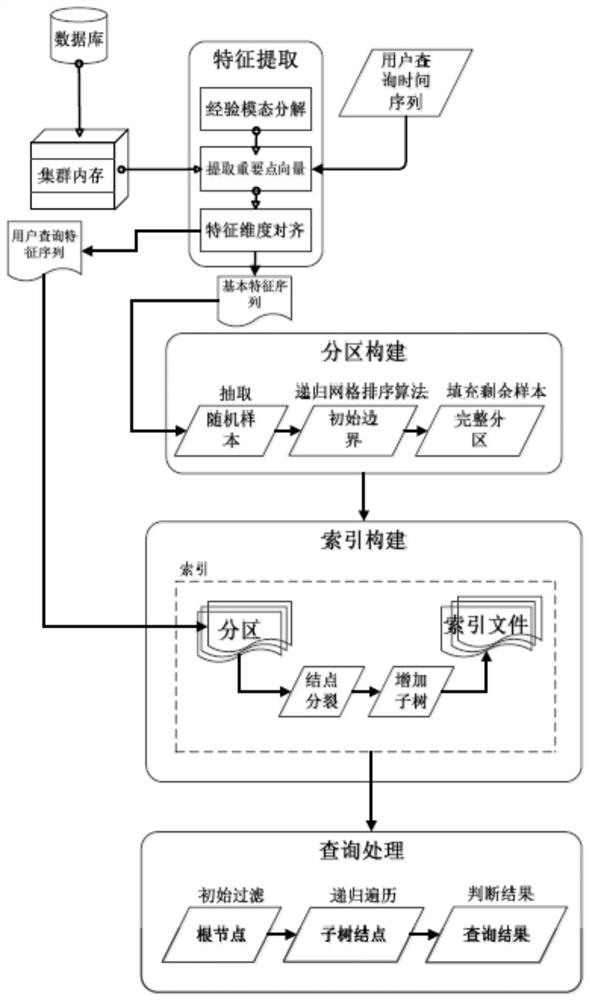
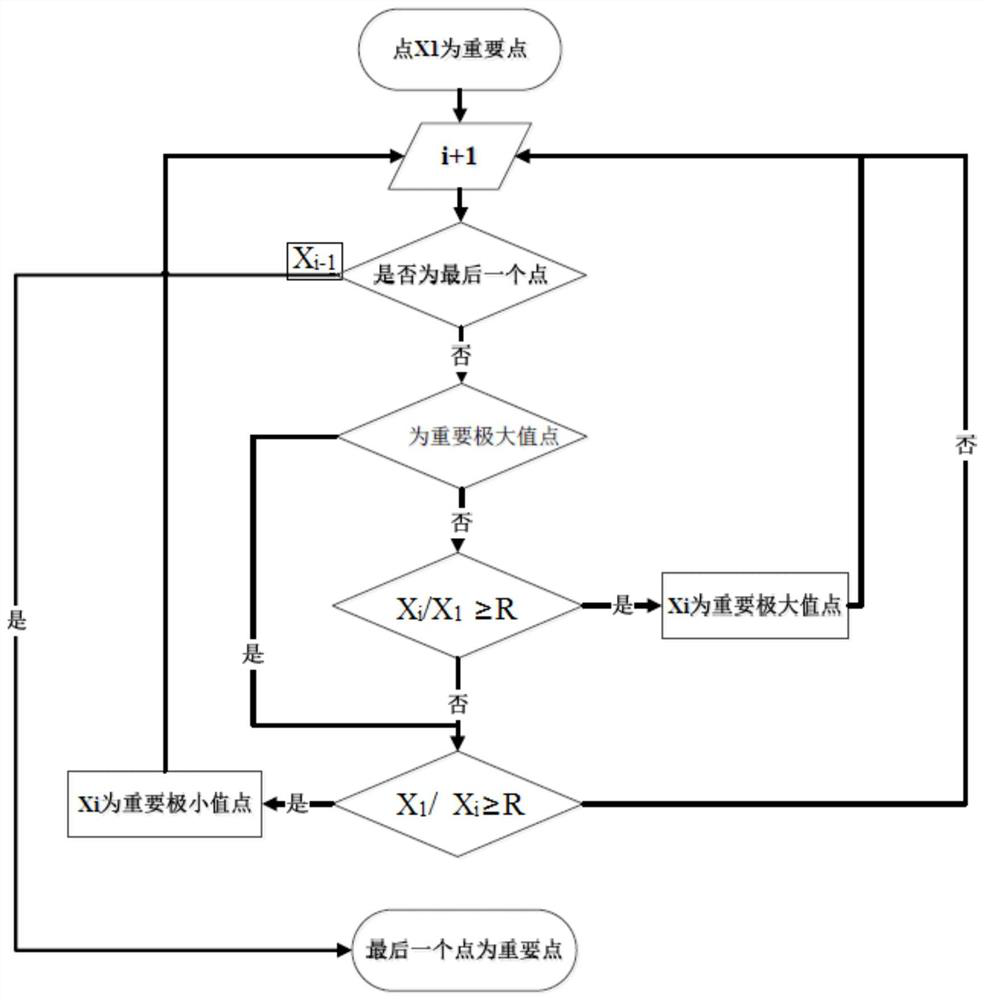
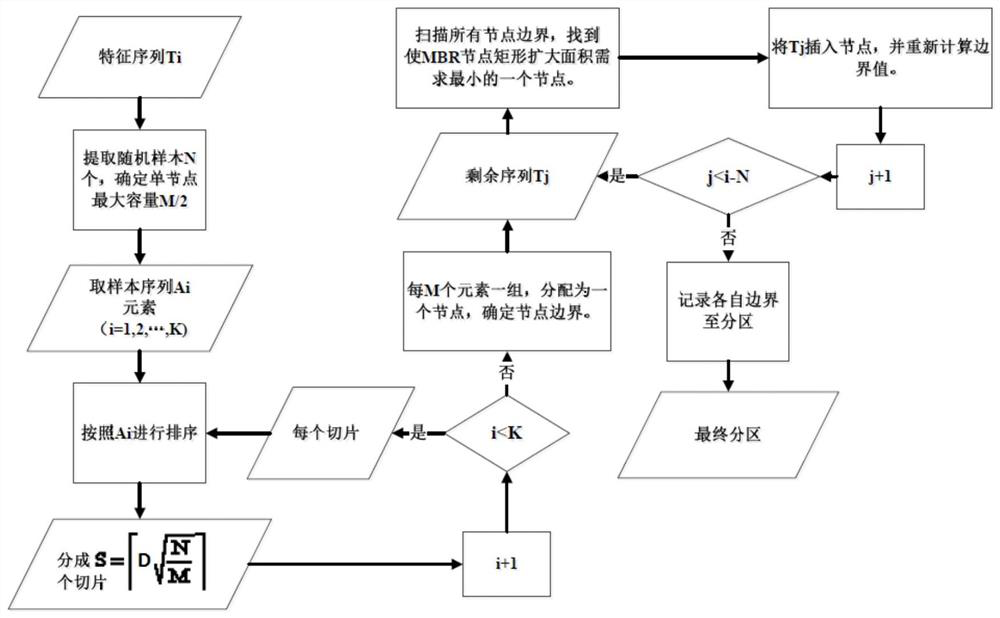
[0067] combine figure 1 , a time series data similarity query method based on memory computing in this embodiment uses a cluster composed of distributed computing nodes, stores data through memory, and expands the computing power of the cluster by expanding distributed nodes. In this embodiment, time-series data is allocated to computing nodes according to corresponding steps, and index resident memory is formed according to corresponding steps. After the cluster receives a search request, each computing node is scheduled to search according to corresponding steps. The partitioning and index construction of each node's data are performed in local memory, and can communicate with other nodes or overall external submodules to aggregate, move and process data. The query process reads data on some of the nodes, guided by an in-memory index, eliminating the need to scan the entire cluster. This embodiment specifically includes the following steps:
[0068] (1) Data preprocessing,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More