

Speaker separating model training method, two-speaker separation method, and related equipment
A speaker separation and model training technology, applied in the field of biometrics, can solve the problems of poor speaker separation effect and insufficient single Gaussian model to describe the data distribution of different speakers, so as to improve the accuracy rate, achieve the best separation effect, and reduce the The effect of the risk of reduced performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
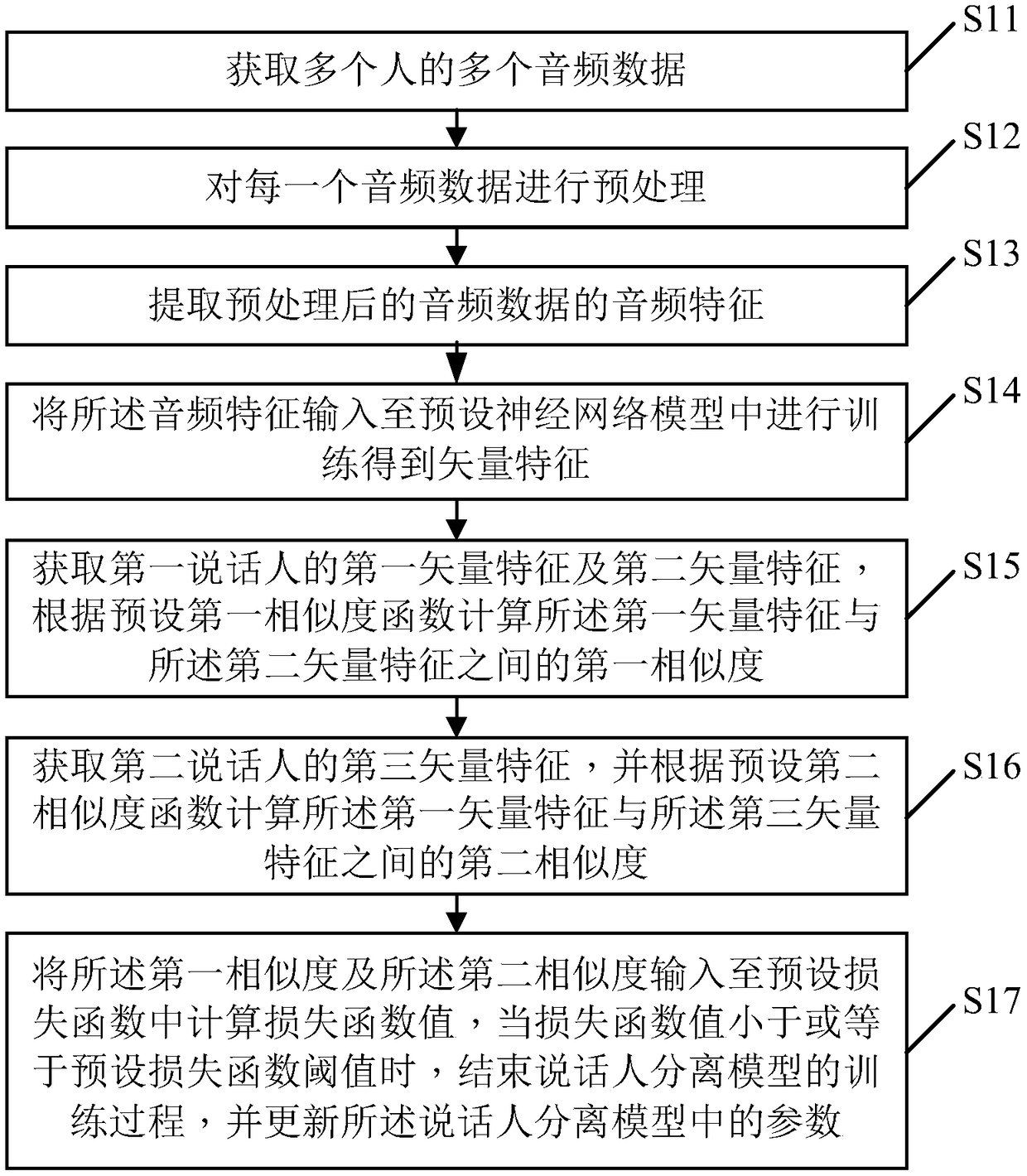
[0061] figure 1 It is a flow chart of the speaker separation model training method provided by Embodiment 1 of the present invention. According to different requirements, the execution sequence in the flow chart can be changed, and some steps can be omitted.
[0062] S11. Acquire multiple pieces of audio data of multiple people.
[0063] In this embodiment, the acquisition of the plurality of audio data may include the following two methods:
[0064] (1) An audio device (for example, a tape recorder, etc.) is set in advance, and the voices of multiple people are recorded on the spot through the audio device to obtain audio data.
[0065] (2) Obtain a plurality of audio data from the audio data set.
[0066] The audio data set is an open-source data set, such as UBM data set and TV data set. The open-source audio data set is dedicated to training the speaker separation model and testing the accuracy of the trained speaker separation model. The UBM data set and TV data set c...
Embodiment 2
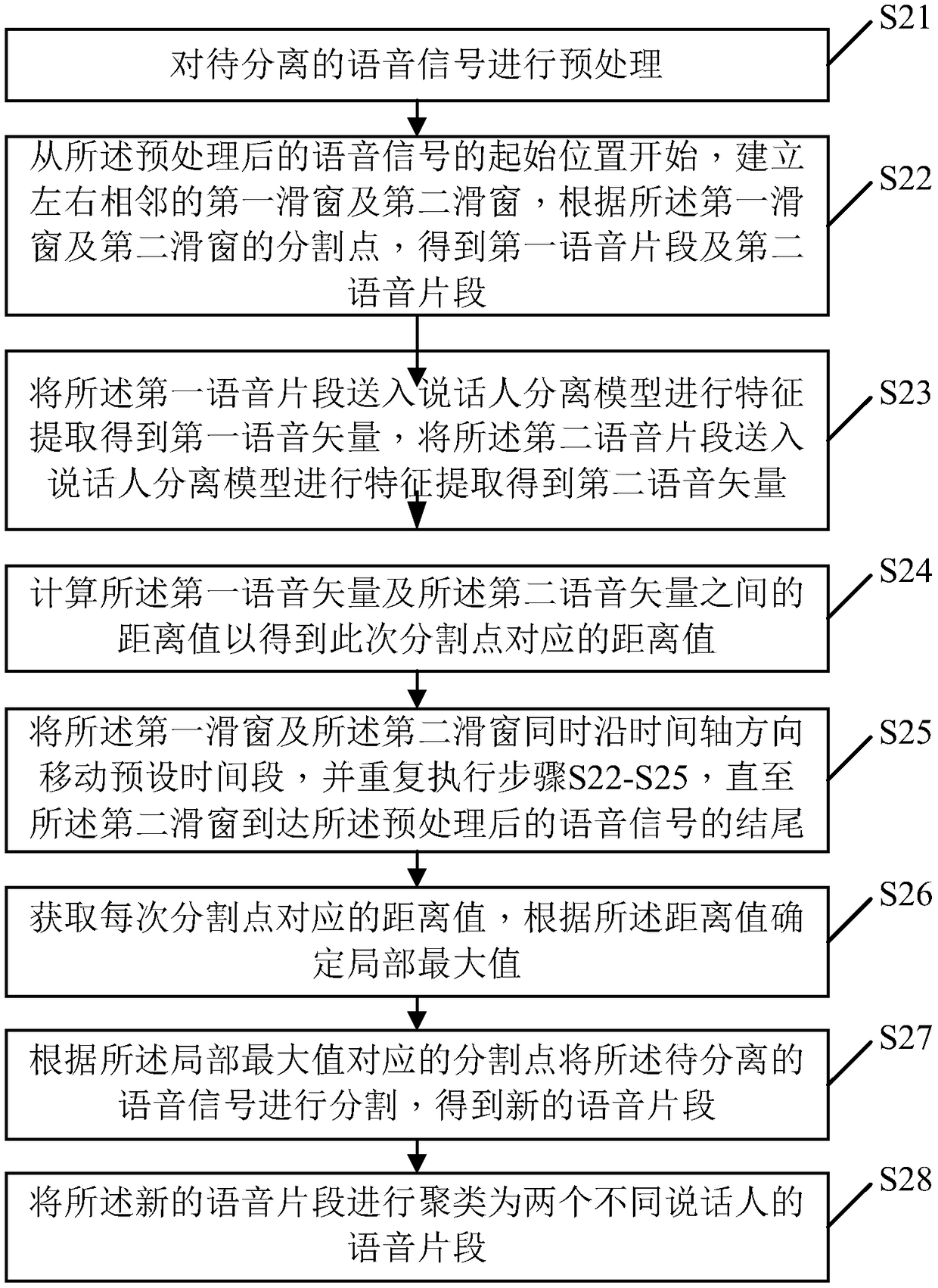
[0103] figure 2 It is a flow chart of the two-speaker separation method provided by Embodiment 2 of the present invention. According to different requirements, the execution sequence in the flow chart can be changed, and some steps can be omitted.
[0104] S21. Perform preprocessing on the speech signal to be separated.
[0105] In this embodiment, the process of preprocessing the speech signal to be separated includes:
[0106] 1) Pre-emphasis processing
[0107] In this embodiment, a digital filter may be used to perform pre-emphasis processing on the speech signal to be separated, so as to enhance the speech signal of the high frequency part. The details are as follows (2-1):
[0108]
[0109] Among them, S(n) is the speech signal to be separated, a is the pre-emphasis coefficient, and generally a is 0.95, is the speech signal after pre-emphasis processing.
[0110] Due to factors such as the human vocal organ itself and the equipment for collecting voice signals...
Embodiment 3
[0143] Figure 4 It is a functional block diagram of a preferred embodiment of the speaker separation model training device of the present invention.
[0144] In some embodiments, the speaker separation model training device 40 runs in a terminal. The speaker separation model training device 40 may include a plurality of functional modules composed of program code segments. The program codes of each program segment in the speaker separation model training device 40 can be stored in a memory, and executed by at least one processor to execute (see for details figure 1 and its related description) to train the speaker separation model.
[0145] In this embodiment, the speaker separation model training device 40 of the terminal can be divided into multiple functional modules according to the functions it performs. The functional modules may include: an acquisition module 401 , a preprocessing module 402 , a feature extraction module 403 , a training module 404 , a calculation m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More