Full-audio-frequency sensing system for intelligent driving vehicle and intelligent control method thereof
A technology of intelligent driving and perception system, which is applied in the field of full audio perception system and intelligent control of intelligent driving vehicles, which can solve the problems of activity safety restrictions, the inability to predict the changing trend of the surrounding environment, and the inability to obtain environmental information, etc., to achieve the elimination of safety problems. Hidden dangers, the effect of improving the ability to obtain information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
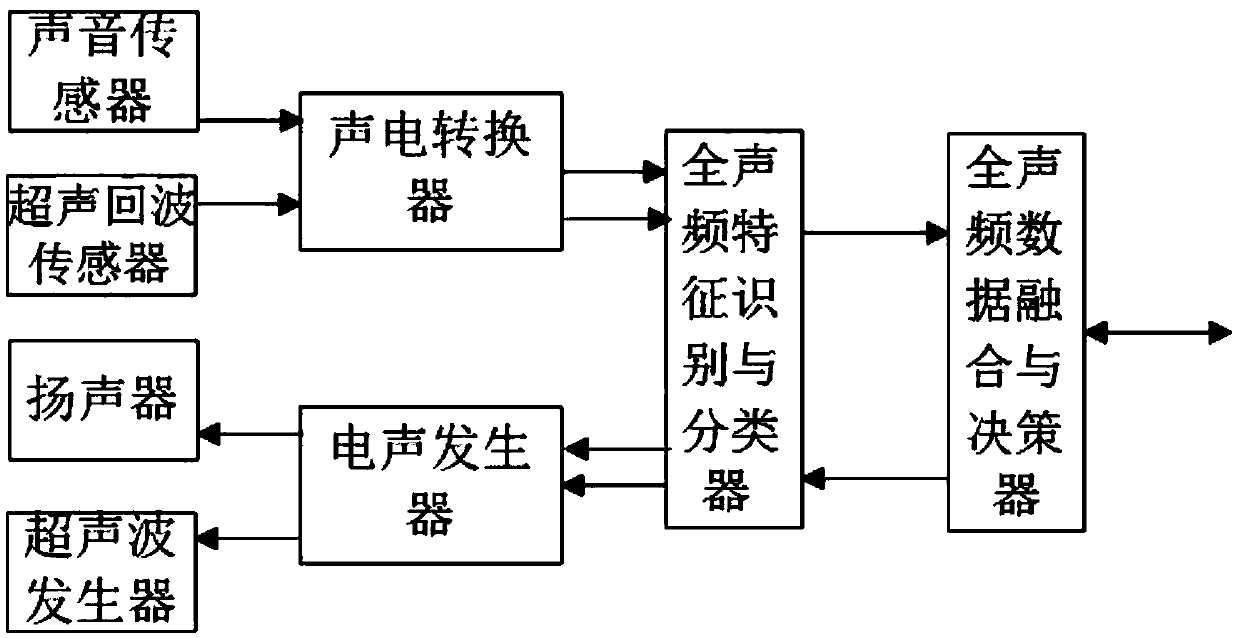
[0057] Such as figure 1 As shown, the present embodiment provides a full audio perception system for an intelligent driving vehicle, hereinafter referred to as a full audio perception system, including a sound sensor, an ultrasonic echo sensor, an acoustic-electric converter, a loudspeaker, an ultrasonic generator, an electroacoustic generator, a full Audio feature recognition and classifier and full audio data fusion and decision maker.
[0058] The sound sensor is used to collect all the sound wave signals that the human ear can feel in the space; the ultrasonic echo sensor is used to collect the specific ultrasonic signal reflected by the object, and analyze the ultrasonic signal of the vehicle identity information it carries; the sound sensor and the ultrasonic The echo sensors are respectively connected with the acoustic-electric transducers.
[0059] The acoustic-electric converter converts the sound signal generated by the sound sensor and the ultrasonic signal generat...
Embodiment 2
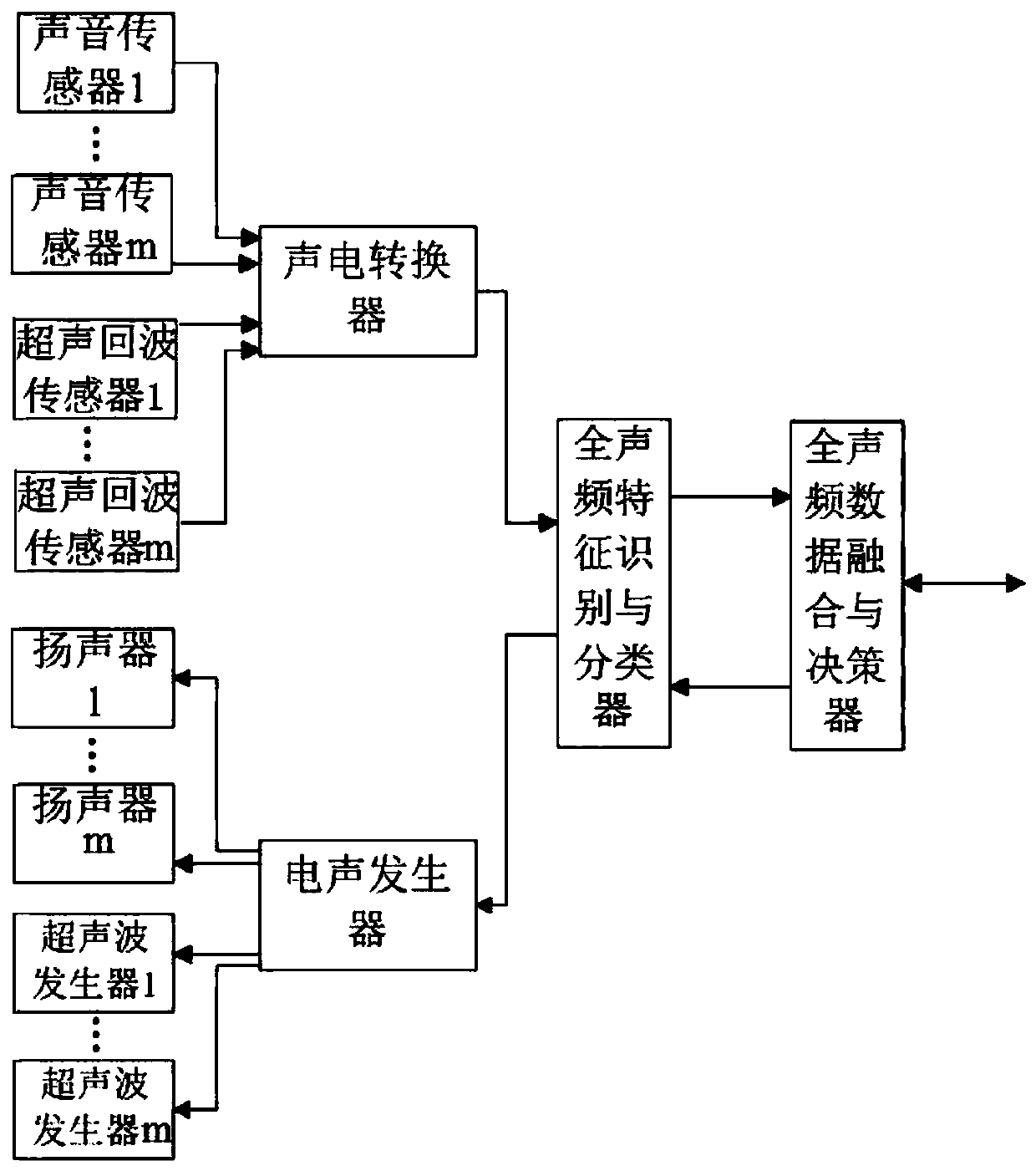
[0090] Such as figure 2As shown, the difference between this embodiment and Embodiment 1 is that there are m acoustic sensors, m ultrasonic echo sensors, m loudspeakers, and m ultrasonic generators; correspondingly, the acoustic The electric converter is provided with multi-channel input and output, and the electroacoustic generator is provided with multi-channel input and output, wherein m is an integer greater than 2.
[0091] It should be noted that in this embodiment, there are multiple sound sensors, ultrasonic echo sensors, loudspeakers, and ultrasonic generators, and the numbers are the same. quantity.
[0092] In this embodiment, increasing the number of sensors can improve the confidence of the data. like Figure 6 As shown, for example, the data obtained by sound sensor 1, sound sensor 2, and sound sensor m at different times are A1 1 、A1 2 、A1 m , A2 1 、A2 2 、A2 m ,An 1 、An 2 、An m , the data obtained by ultrasonic echo sensor 1, ultrasonic echo sensor ...
Embodiment 3
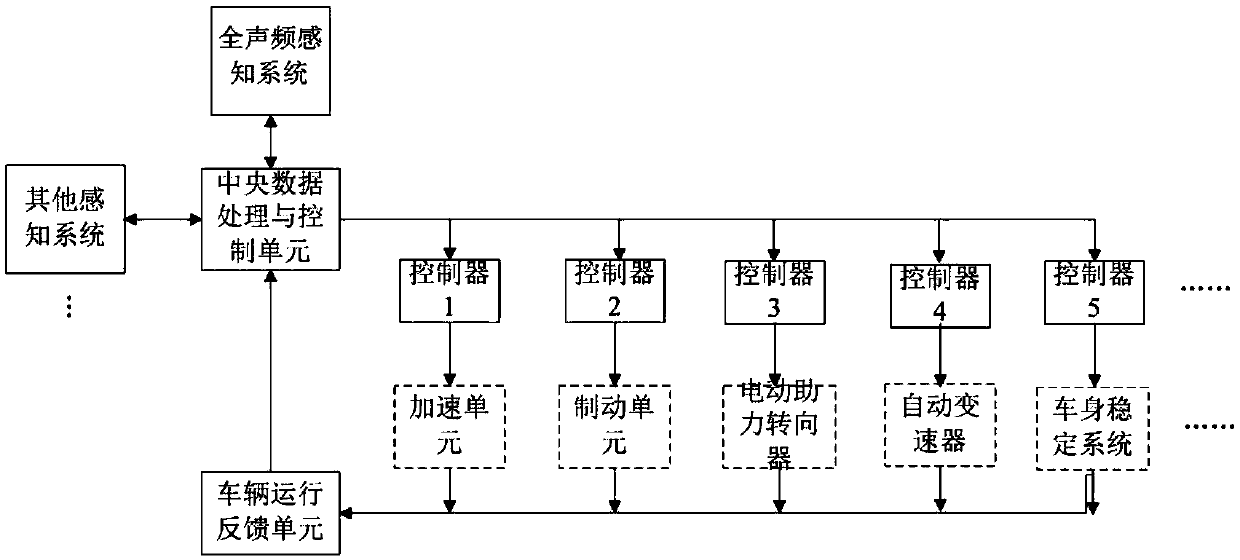
[0095] like image 3 As shown, this embodiment provides an intelligent driving vehicle control system, including the full audio perception system in Embodiment 2, and also includes other sensing systems, specifically connected to the central data processing and control unit of the intelligent driving vehicle GIS-T geographic transportation system, machine vision system, laser radar system, millimeter wave radar system, and vehicle operation feedback unit, the vehicle operation feedback unit is connected with each executive controller, detects the actual working state of the executive controller, and Status information is fed back to the central data processing and control unit.
[0096] The full audio perception system of the intelligent driving vehicle is connected with the central data processing and control unit of the vehicle to realize information interaction between the two parties; the full audio perception system sends vehicle control information to the central data pr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com