A bus missing data recovery method based on coupling information
A technology for driving data and missing data, which is applied to the redundancy in the operation for data error detection, electrical digital data processing, response error generation, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

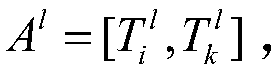
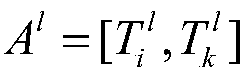
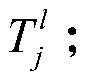
Examples
Embodiment Construction
[0041] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0042] like figure 1 As shown, in the embodiment of the present invention, a kind of method for bus missing driving data recovery proposed, comprises the following steps:
[0043] Step S1, establish the main information of the bus line l to be restored and in the master message , select the missing data to be recovered in, is the arrival time of a bus on line l at station i; is the arrival time of the bus at the follow-up station k, k>=i+2; and are non-missing data; is the arrival time of the bus at the follow-up station j, j=i+1;
[0044] The specific process is to transform the data recovery problem into the travel time estimation problem of adjacent stations. set up is the elapsed time of the line bus from station i to station j; similarly, s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com