A method for data duplicate checking
A data and database technology, which is applied in the field of big data duplication check, can solve the problems of limited storage system scalability, inefficient consumption, complex metadata management and storage, etc., to solve high memory usage, slow solution speed, reduce The effect of connection time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
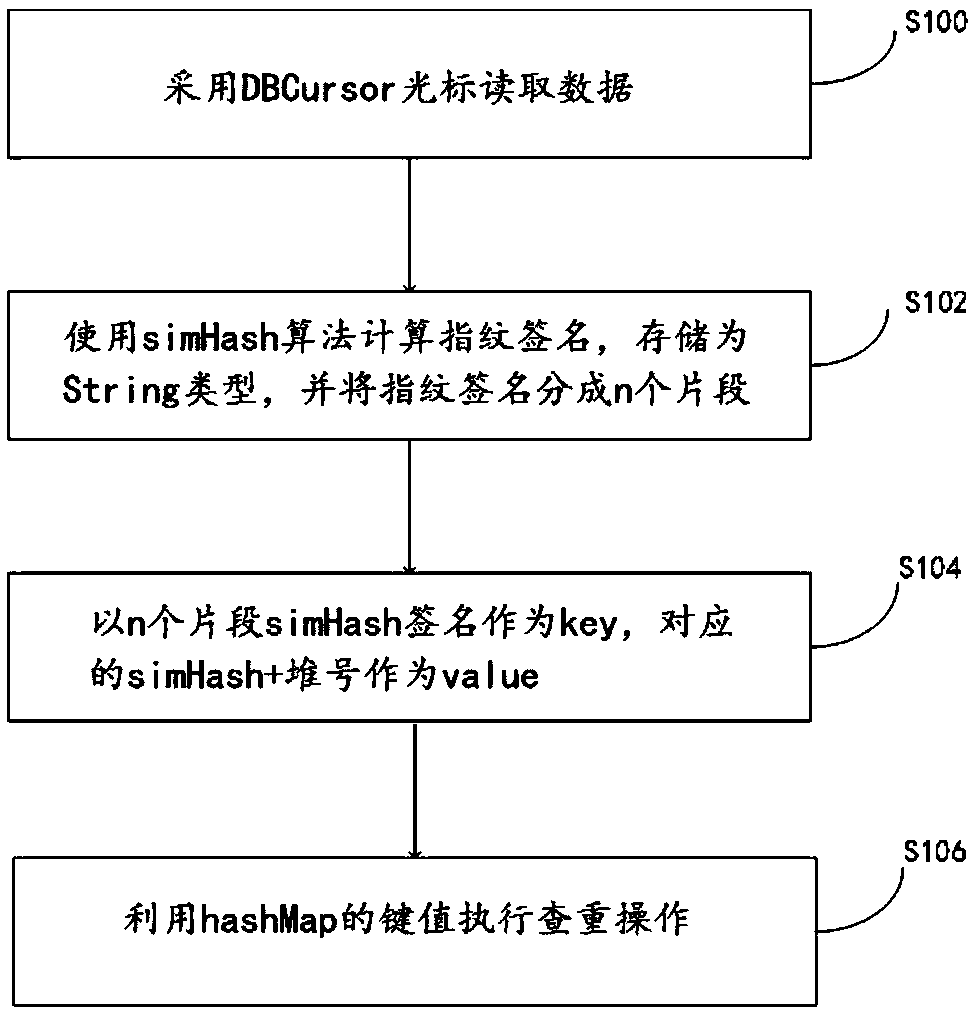
[0038] Such as figure 1 As shown, in the first aspect, the present invention provides a data duplication check processing method, comprising the following steps:
[0039] Step S100: use the DBCursor cursor to read data for massive resource data, use .next() to read data in the database in order, and close the connection with close() after reading;
[0040] Step S102: traverse the resource data list in batches, use the simHash algorithm to calculate the text in the resource database as a simHash fingerprint signature, store it as a String type, and divide the fingerprint signature into n pieces, where n is a natural number;
[0041] Step S104: Use the above obtained simHash signature as the key, and the corresponding sinHash+heap number as the value;
[0042] S106: Use the key value of the hashMap to perform a duplicate check of the target text, and determine whether the Hamming distance of the n segments is less than the set threshold, if it is less than the threshold, it is ...
Embodiment 2
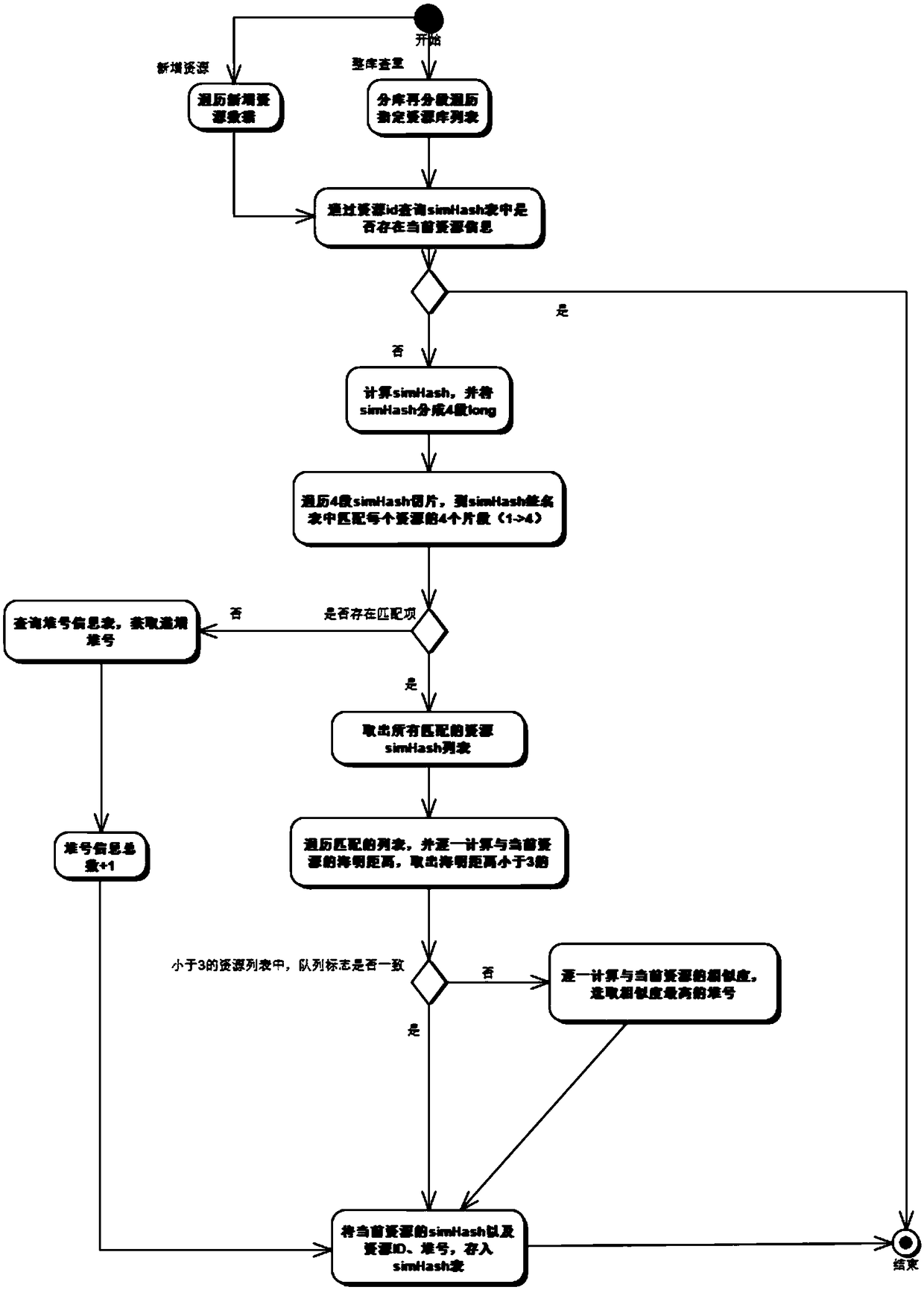
[0053] Such as figure 2 As shown, in the second aspect, the present invention provides a logical flow chart of data duplication check, including:
[0054] Data reading, use the DBCursor cursor to read the data in the resource database;
[0055] Data query, query whether there is current resource information in the simHash table through the target resource data id; if yes, end the current data duplication check, if not, further calculate the simHash fingerprint signature operation on the current data, and segment the fingerprint signature;
[0056] Traverse each segmented simHash segment, and match the segmented simHash fingerprint of the target resource data in the resource data signature list: If there is no match, then further query the heap number information table, and store the heap number information + 1 into the cache ; If there is a matching item, take out all matching resource simHash lists, calculate the Hamming distance with the current resource data one by one, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More