

A social network public opinion evolution method
A social network and public opinion technology, applied in the field of Nash equilibrium strategy, can solve problems such as the inability to guarantee the global optimality of the algorithm, and achieve the effect of maximizing benefits
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] The present invention will be described in further detail below in conjunction with the accompanying drawings and embodiments.
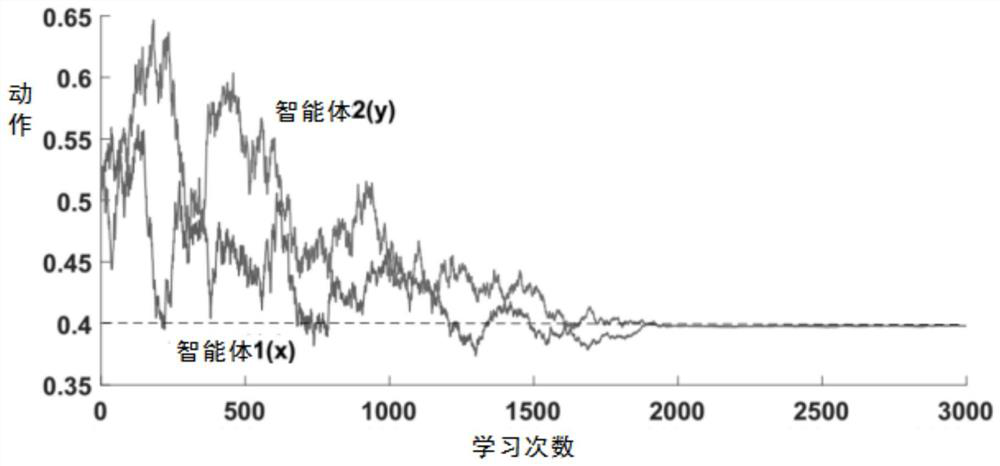
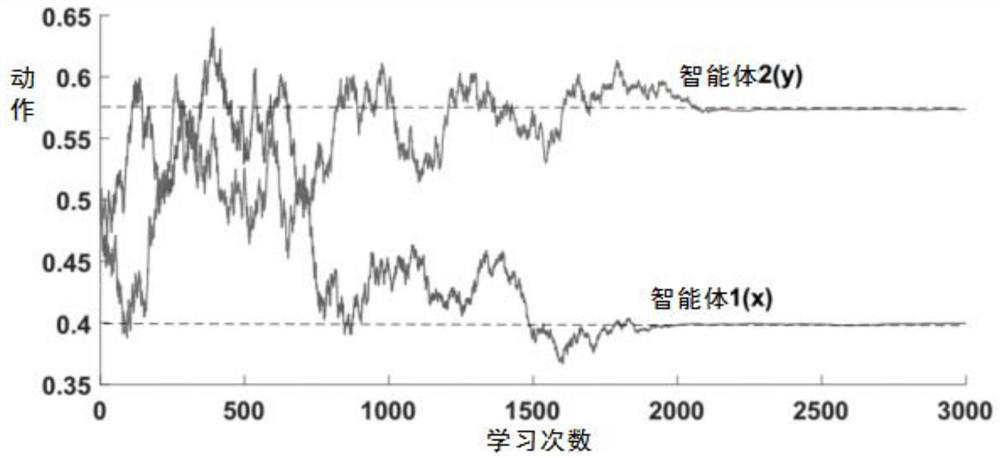
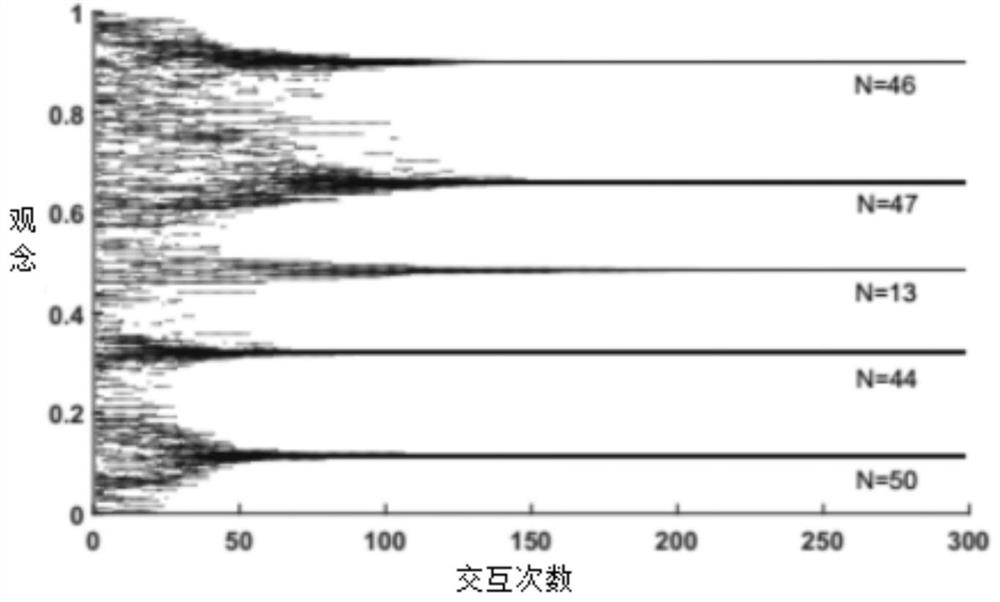
[0045] The Nash equilibrium strategy on the continuous action space of the present invention is extended from the single-agent reinforcement learning algorithm CALA [7] (Continuous Action Learning Automata, continuous action learning automata), by introducing WoLS (Win or Learn Slow, learning quickly when winning) mechanism, so that the algorithm can effectively deal with learning problems in a multi-agent environment. Therefore, the Nash equilibrium strategy of the present invention is referred to as: WoLS-CALA (Win or Learn Slow Continuous Action Learning Automaton, win is fast-continuous action learning automaton) . The present invention firstly describes the CALA in detail.
[0046] Continuous Action Learning Automata (CALA) [7] is a policy gradient reinforcement learning algorithm for learning problems in continuous action spaces. Among...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More